Add WebP image support. #159
Comments
|
Doesn't seem to be working as expected. Covers aren't returned during search for import:
Then when an import is attempted, I get this in the cmd window: Exception in thread "Jarvis-ComiXed" java.lang.UnsatisfiedLinkError: C:\Users<user>\AppData\Local\Temp\4033803682668637191webp-imageio.dll: Can't find dependent libraries |

|
@bareheiny Okay, there's a DLL mentioned in the stacktrack:
(the username seems to be redacted) Can you verify if that DLL is present on your system when CX is running? (the filename might change since it's a temporary file) Opening the JAR file I'm seeing the following contents: and the native library for the Mac ran for me here. |
|
I redacted the username as it's not an alias...which is fine for anybody how already know that bareheiny = Guy Incognito, but not something that I want all and sundry to know :P Anyways, I can see the temp webp-imageio.dll files - the one mentioned in the log is still there, and another was created when I just started CX. As some WebP comics were still in the processing queue, CX threw the same error, just referencing the newer copy of the dll. |
|
Same error here under Win10. The dll exists while the CX is running. |
|
Maybe pointing to the issue? For sure copying the dll into the java/bin directory didn't work - unsurprising I guess. |
|
Testing this on my Windows laptop, the WebP comic page appears to have loaded: And peeking at the page and at the database, all of the metrics were extracted, which could only be done if the WebP library worked. My Windows laptop specs are:
|

|
I tried another Windows machine - same thing's happening. Both machines are 64bit Win 10 Pro. Specs on both are lower than your machine, but I wouldn't expect that to be an issue. Both are also running JRE 1.8. |
|
Is there value in looking back to the part where we first find the comics? It tries to create thumbnails but it doesn't create thumbnails for webp images. It does create thumbnails for jpg in this part. It doesn't crash when opening CBZs or CBRs during this part. Only when trying to use the import function. |
|
I put the dll in the java\bin dir and tried again. I’m not getting that error anymore - it’s been replaced by another >_< No thumbnails generated either, and the logs say the archive doesn’t have any images... |
|
@bareheiny Can you give me a little more detail when you say you "put the dll in the java\bin dir and tried again"? Did you remove it from the JAR, or just copy it over there? I don't think Java's going to look for DLLs in that directory unless you explicitly tell Java to do so. And can you paste in the text from the logs? Also, please know that CX does not generate thumbnails. All it does it extract the image from the archive and return the bytes to the browser, and the browser itself renders the image from those bytes. The flow for loading images is:
In both cases, the backend doesn't try to decode the image: it only loads the bytes and returns them to the frontend. This WebP (and other image-processing) code only comes into play when the backend is performing the initial comic import, and only when getting the metrics of the image file. After that, it doesn't care what the bytes are. |
|
I'll need to start CX up again to get the logs - will do that when I get some free time. I don't muck around with the CX code these days, so I just copied the DLL from the temp directory, stripped the extra characters (so it's named webp-imageio.dll) and put it in the java\bin folder in my machines "Program Files" directory. As the bin directory is in the Windows PATH variable, I understood that Java or Windows looks there by default. Anyway, it caused another error so I was likely barking up the wrong tree. Cover images aren't being extracted and forwarded to the browser at any point (see the image attached to my first comment in this thread), and although I'm sure I saw text about MIME types and WebP in the logs, I definitely saw messaging saying the archive didn't contain any images. |
|
CX log (no webp-imageio.dll in the java\bin directory): Text from the CMD window: |
|
How many pages were in the WWDE01WebP80 (1).cbz file? I see where the comic was processed, and it loaded one page out of it: So that exception's getting thrown when the Page class is trying to get the image metrics. I'm not sure why your system isn't finding the DLL that comes with the JAR file. But this is ultimately a bug with the WebP library, not something we can fix at the CX level since it's happening outside of our code space. I'm opening a bug with them to get them to fix it. |
|
WWDE01WebP80 (1).cbz has 52 pages. There's a lot of "Loading entry: name P000..." type entries in the log as well, which all occur before the first (and only) hash is generated. I've converted my collection to WebP now - which reduced the space used significantly. While I do have un-converted backups, I'll likely be less active with regards to CX for a bit until I can get my converted library loaded. |
|
The log's no longer available (the link is 404). Can you repost it? |
|
I noticed the logs were missing earlier, but no clue where they went. |
|
I rebuilt my surface (for unrelated reasons), and tried this again - completely different set of errors. Then I tried again, and back to the missing libraries. Unfortunately I didn’t capture the logs. May try again later. But it got me to wondering how you converted a test comic to WebP? I’m getting a bunch of “no image in archive” messages...so perhaps the conversion process is corrupting the image somehow. |
|
@bareheiny Well, I never said "converted". 😉 What I did was to take some existing WebP-encoded images and put them into a zipfile with a "cbz" extension and then import it as a comic. Can you email one of those comics to me to test locally? Ultimately, though, I don't think this is a CX issue, but a bug in the WebP library JAR. I've files a bug with them and hopefully they'll get a fix together for it. Maybe go over there and let the developer know you're intested in the fix as well? |
|
Thinking about it, the conversion wouldn't trigger a library issue anyways (I assume!). Here are two copies of the same file - one was converted via CR, the other via cwebp. Oddly, the file sizes are different - so I may look into why, but for now I'm more interested in whether or not you can import them (and view the images). https://www.dropbox.com/s/v5uv4ys8ju9dshv/A52%20%28cwebp%20converted%29.cbz?dl=0 Let me know once you've picked the files up. I'm watching the issue you created, but I'll add a comment shortly :) |
|
(copied from sejda-pdf/webp-imageio#1) @mcpierce The tool you want is Dependencies. https://github.com/lucasg/Dependencies After installing that DLL webp comics import properly. The only problem I see is when choosing a library to import, the covers do not appear correctly. They appear as broken images. |

|
@dukeofradish noice! I'd installed most of VS on my desktop, and got WebP archives importing...but using a few GB of space just to get that working wasn't viable on my Surface. Re the cover images, I'm seeing the same thing - once a comic is fully imported, they display fine. In the CX logs I'm seeing a lot of entries indicating CX is checking every file in the archive...any chance you're seeing that? It's almost like CX is opening the archive, checking the first file....going "nope, not a cover image", closing the archive, reopening it...loading the first file, then the second...checking it, "nope, not a cover image" and then repeating. On larger archives, I'm seeing hundreds of lines like that repeated... |
|
On a 64bit Win 10 Surface Pro 4, I'm seeing VCRUNTIME140D.dll as missing as well. |
|
I've attached a log of importing 2 of the same comic, same meta data, etc but one is webp and the other is jpg. |
|
I grabbed the missing dll from my other machine :) And yup, that's the stuff I'm seeing in the log. Will create a bug report about it. |
|
@bareheiny This is probably tangential. In the 6-prerelease is the reader supposed to be functional? |
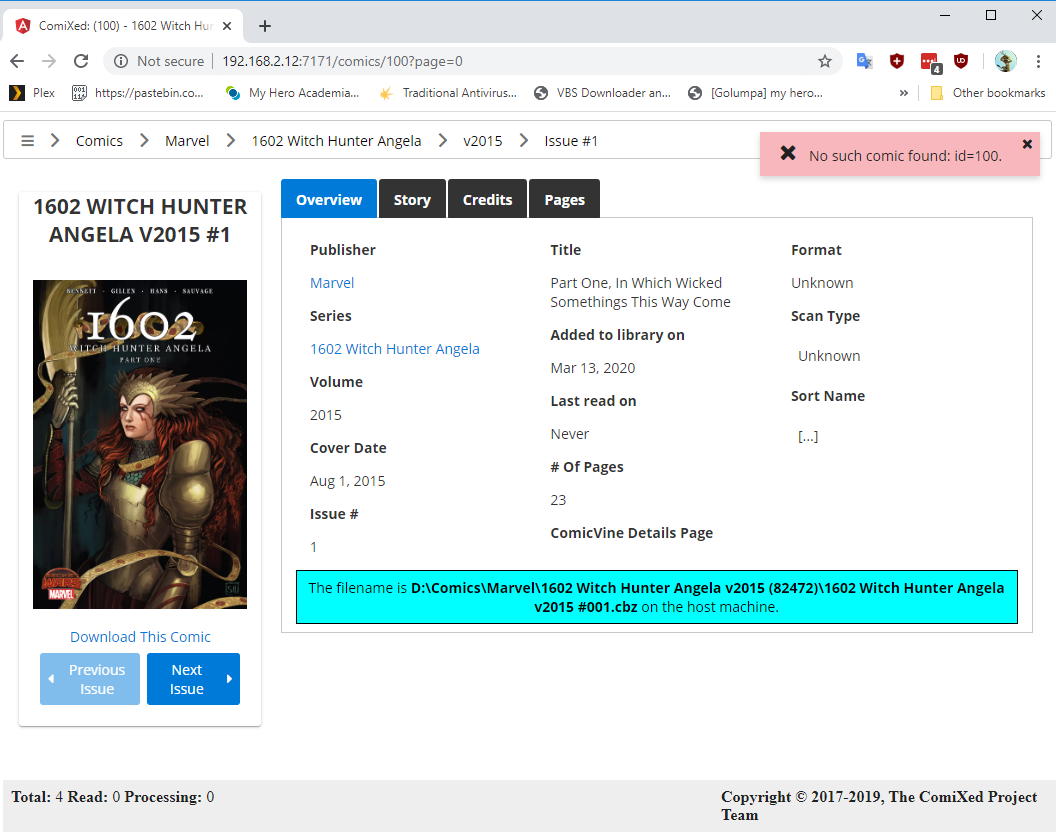
|
I think @mcpierce doesn't intend for CX to be a reader. I have noticed that "No such comic found" message before - I usually look at it, scratch my head because the comic info is displaying and then move on. I really need to get better at raising bugs for things like that as I'm working through processing my library >_< |
|
@dukeofradish As @bareheiny mentioned, CX isn't going to be a reader. Granted, there's a page viewer, but it's just for viewing pages; i.e., it doesn't treat that as reading the comic, nor does it track last page or anything. It's just for doing page-related maintenance (blocking/unblocking/deleting/undeleting pages). |
|
@bareheiny That toaster popup is a side effect of the comic state not having a proper "no such comic" field in it. So when you first go to a comic's details page, before it's loaded the comic, that message comes up. I haven't added that new field yet, but am going to open a ticket now so I don't forget to do it. It's annoying, and I see it all the time too. 😄 |
See this artifact for WebP codec support.
The text was updated successfully, but these errors were encountered: