Home
Titanoboa is fully distributed, highly scalable and fault tolerant workflow orchestration platform. It employs hybrid iPaaS and FaaS concepts and runs on the JVM. You can run it on your laptop, on-premises or in a cloud.
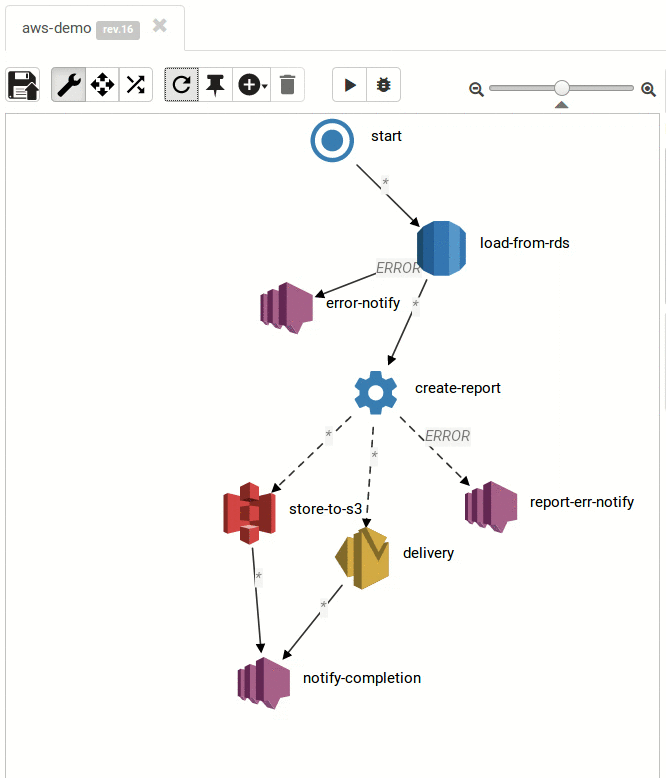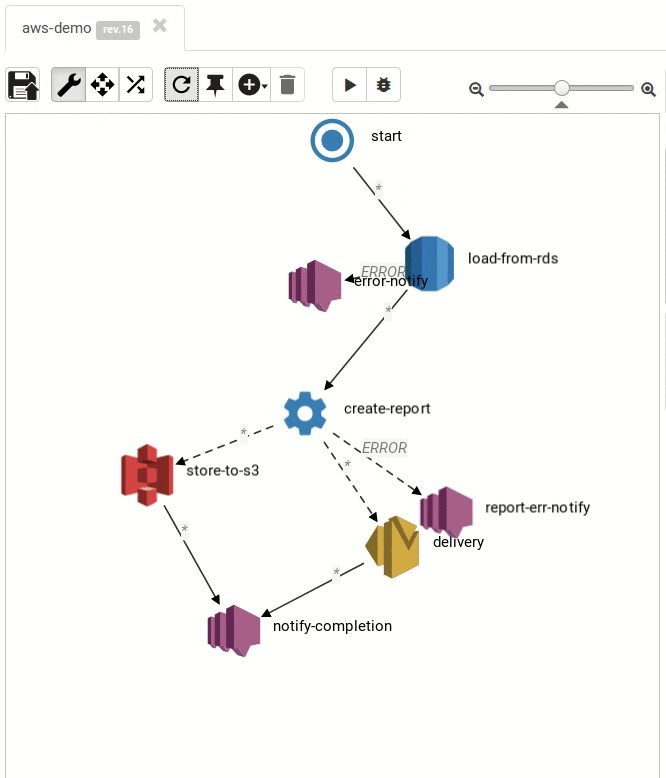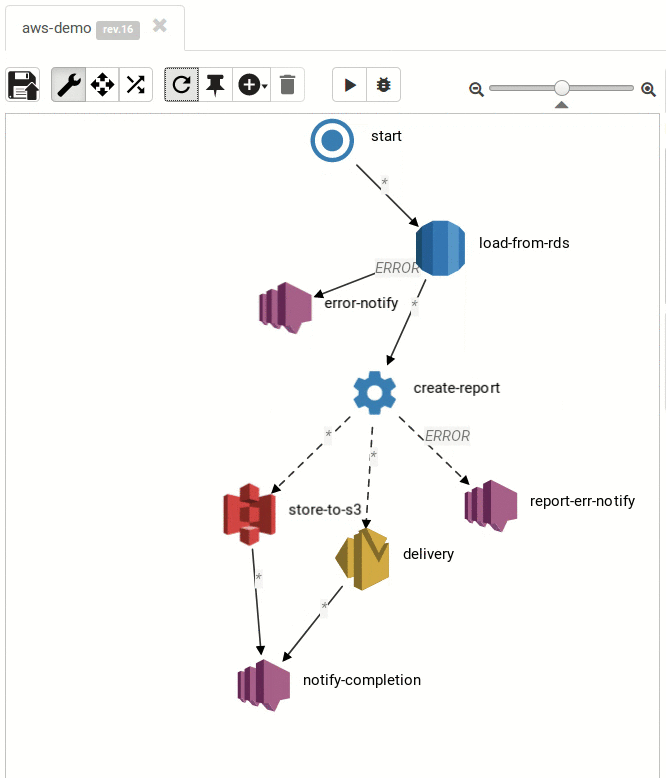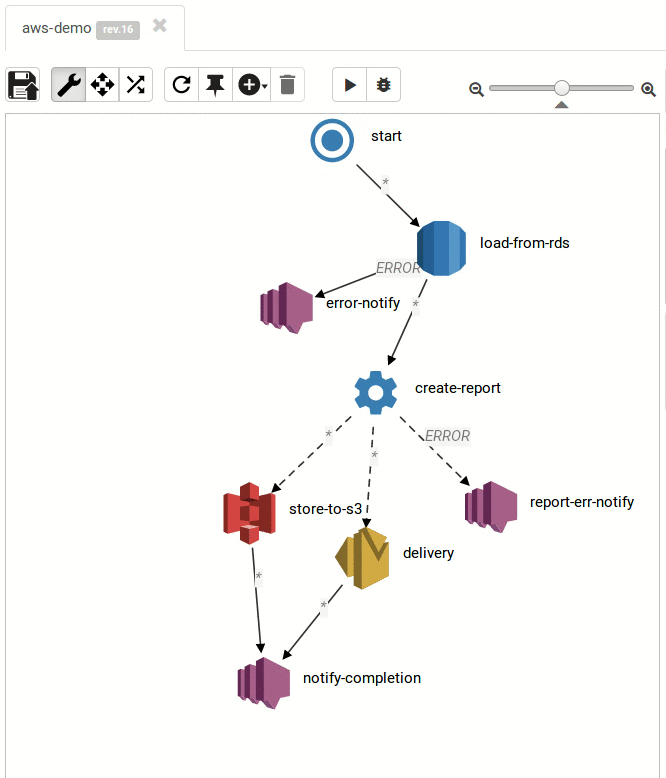
titanoboba.io started off as an experiment: how would a workflow engine or a batch processing engine (e.g. Spring Batch) look like if it was written following functional programming principles with a strong focus on immutability? Since titanoboa processes workflows in immutable way, it can be be fully distributed. Even titanoboa cluster operates in immutable, master-less way, so there is no horizontal scalability limit which means you can add any number of nodes into the cluster.
titanoboa is platform-agnostic. It does not expect you to run certain type of database or message provider. It is just a simple jar file and you can run it as such with no external dependencies - which is great for agile development & testing. You can use your own choice of message broker if you want the workflows to be distributed across multiple nodes as well as you can use your preferred database to archive the workflow jobs into.
titanoboa approaches these problems in a bit naughty way: instead of running a bunch of microservice instances for each (pre-compiled) step of a workflow and orchestrating the flow (as AWS step functions do) titanoboa server instance can process any workflow step you throw at it - if you wish (and allow it in production, which you may not) - you can even let it compile (eval) and execute new workflow/step code you throw at it during runtime. And you can allow this to happen only for workflow code that comes from your trusted (and tested) repository. This way no downtime (and pretty much no deployment) is required to deploy new workflows on running titanoboa nodes! Also, running multiple versions in parallel is trivial.
titanoboa is distributed in a form of a jar file that can be executed using java virtual machine. The so-called "unberjar" contains all its dependencies including a jetty server.
Workflow (also called as "workflow definition", "flow" or "job definition") is a definition of a workflow - its individual steps and their execution graph. Each workflow definition has a name and a set of global properties you can define.
Titanoboa workflows can be defined using json or edn data format. EDN is currently the preferred format used internally as it offers more sophisticated data-structures as well as better extensibility.
A simple workflow definition may look as follows. It consists of two steps - first step makes a GET call to a specified URL, store the results in job's properties; the second job will load some data from a database:
{:name "sample-workflow",
:revision 14,
:properties {},
:first-step "http-client",
:steps [{:id "http-client",
:type :http-client,
:supertype :tasklet,
:next [["*" "load-data"]],
:workload-fn #titanoboa.exp/Expression{:value "titanoboa.tasklet.httpclient/request",
:type "clojure"},
:properties {:request-method :get,
:as :json,
:response-property-name :rest-response,
:url "https://jsonplaceholder.typicode.com/posts/1"}}
{:id "load-data",
:type :jdbc,
:supertype :tasklet,
:workload-fn #titanoboa.exp/Expression{:value "titanoboa.tasklet.jdbc/query",
:type "clojure"},
:next [],
:properties {:response-property-name :db-data,
:data-source-ks [:test-db :system :pool],
:query "select ordernumber, TotalAmount from orders"}}]}
A step is a node in a workflow graph - it can have its own properties and it consists of a workload function that is to be executed when the step is run. The workload is either defined as a library function that is supposed to be executed (e.g. as a package/method name that is on the classpath or in a library in specified maven repository/artifact) or as an anonymous function code (either in clojure or java at the moment; other languages are coming).
{:name "hello-world"
:revision 5
:properties {:name "World"}
:steps [{:id "clojure-hello-world"
:type :custom
:supertype :tasklet
:next []
:workload-fn #titanoboa.exp/Expression{:value "(fn [p] {\"greeting\" (str \"Hello \" (:name p) \"!\")})"
:type "clojure"}
:properties {}}]}workflow definitions can be stored in a repository. Since titanoboa follows immutability principles, any changes to a flow are stored as a new revision.
Job is an instance of a workflow that is being (or has been) executed. Job is basically yet another data structure (graph) that - apart from its workflow definition - contains mainly its properties, that are evaluated throughout the course of job's steps' execution. Job also contains other metadata in regards to its execution: its state, history, timestamps etc.
There can be maps of properties defined on the level of each step or for the entire job (i.e. on the workflow level). Properties can be literals, but can also be expressions (written in clojure or java) that will be evaluated during job execution. Jobs are executed in immutable fashion: first, job's properties are evaluated, then first step is identified, and all its properties are evaluated and merged onto existing job properties. Workflow function is then invoked and job's properties map is passed onto it as its argument. If the workflow function returns a map, it is treated as properties map and is again merged onto current job's properties map. Then, next step is identified (also based on result of the workflow function) and the cycle continues.
Job channel is basically a message queue in a message broker. It is used to distribute job graph for its processing to job processing threads (workers) and to other nodes in cluster. Job channel can be either entirely in-memory (this is a default set up for titanoboa community edition running on a single node) or can be based on a number of existing messaging protocols (AMPQ / JMS) and message brokers (Rabbit MQ / Active MQ / SQS).
Worker is a thread that processes job steps. It evaluates job's and step's properties and that invokes step's workload function with the properties as a parameter.
Systems are modules that can extend titanoboa server - they can be started and stopped during runtime and they are based on Stuart Sierra's Component library. If you are not familiar with clojure's ecosystem then systems can be thought of as Spring contexts with Spring beans that you would instantiate or destroy during runtime. Titanoboa's systems can be divided into core systems (that contain workers to process workflow jobs) and other systems that do not process jobs and provide some other functionality (job archival, DB connection pooling, authentication etc.).
Core system is a system that contain workers to process workflow jobs. For titanoboa server to actually process a workflow it has to have at least one core system with one worker active - that is its minimal setup:

Non-core systems do not process jobs and provide some other functionality (job archival, DB connection pooling, authentication etc.):

Configuration of the server - including http(s) protocol, port, workflow repository configuration and system catalogue - is defined in a .clj file and is loaded upon server startup.