{kind=link}
2017/12/18: Added new version which is Instance Normalization on top of Batch Normalization. Might be faster if CUDA and cuDNN are available.
This is a Chainer v2 implementation of Instance Normalization.
Note that this implementation will not work if your Chainer version is under 2.0.
Instance normalization is regarded as more suitable for style transfer task than batch normalization.
In Instance normalization, you normalize each mini batch using mean and variance of each tensor in one mini batch.
So the shapes of mean and variance should be (batch_size, n_channel).
The original paper is found here.
I'm looking forward to your review and/or correction.
This is comparison of InstanceNormalization layer and combination of chainer.functions and chainer.variable.Parameter.
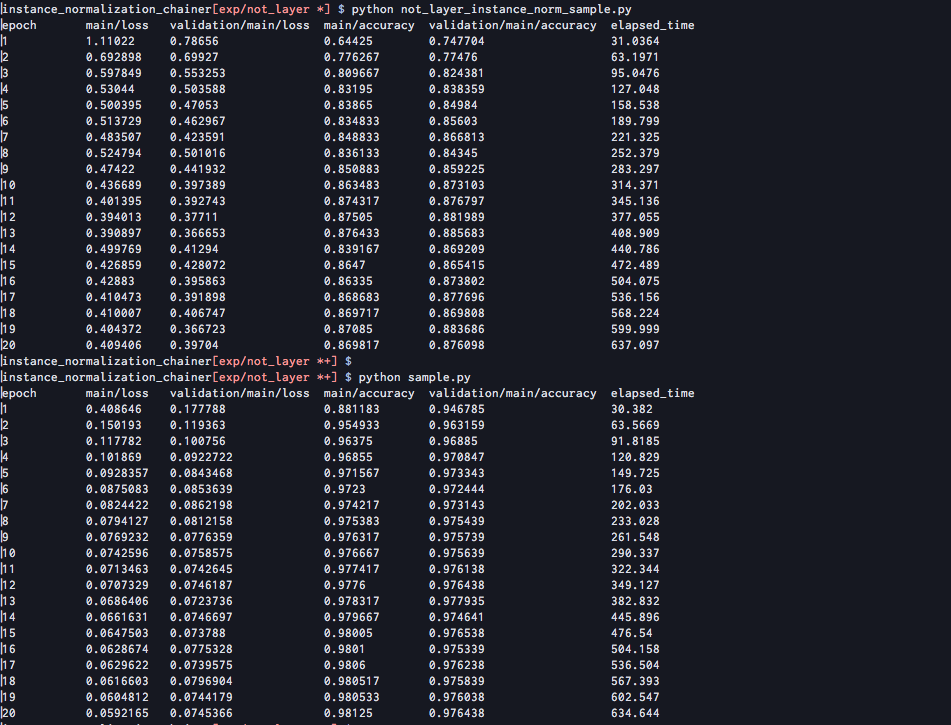
As in not_layer_instance_norm_sample.py, the latter implementation might be more naive than the other.
def prepare_beta(size, init=0, dtype=np.float32):
initial_beta = chainer.initializers._get_initializer(init)
initial_beta.dtype = dtype
beta = chainer.variable.Parameter(init, size)
return beta
def prepare_gamma(size, init=1, dtype=np.float32):
initial_gamma = chainer.initializers._get_initializer(init)
initial_gamma.dtype = dtype
gamma = chainer.variable.Parameter(init, size)
return gamma
def instance_norm(self, x, gamma=None, beta=None):
mean = F.mean(x, axis=-1)
mean = F.mean(mean, axis=-1)
mean = F.broadcast_to(mean[Ellipsis, None, None], x.shape)
var = F.squared_difference(x, mean)
std = F.sqrt(var + 1e-5)
x_hat = (x - mean) / std
if gamma is not None:
gamma = F.broadcast_to(gamma[None, Ellipsis, None, None], x.shape)
beta = F.broadcast_to(beta[None, Ellipsis, None, None], x.shape)
return gamma * x_hat + beta
else:
return x_hat