Go to 'Workbench -> Import Texts' and hit the import button.
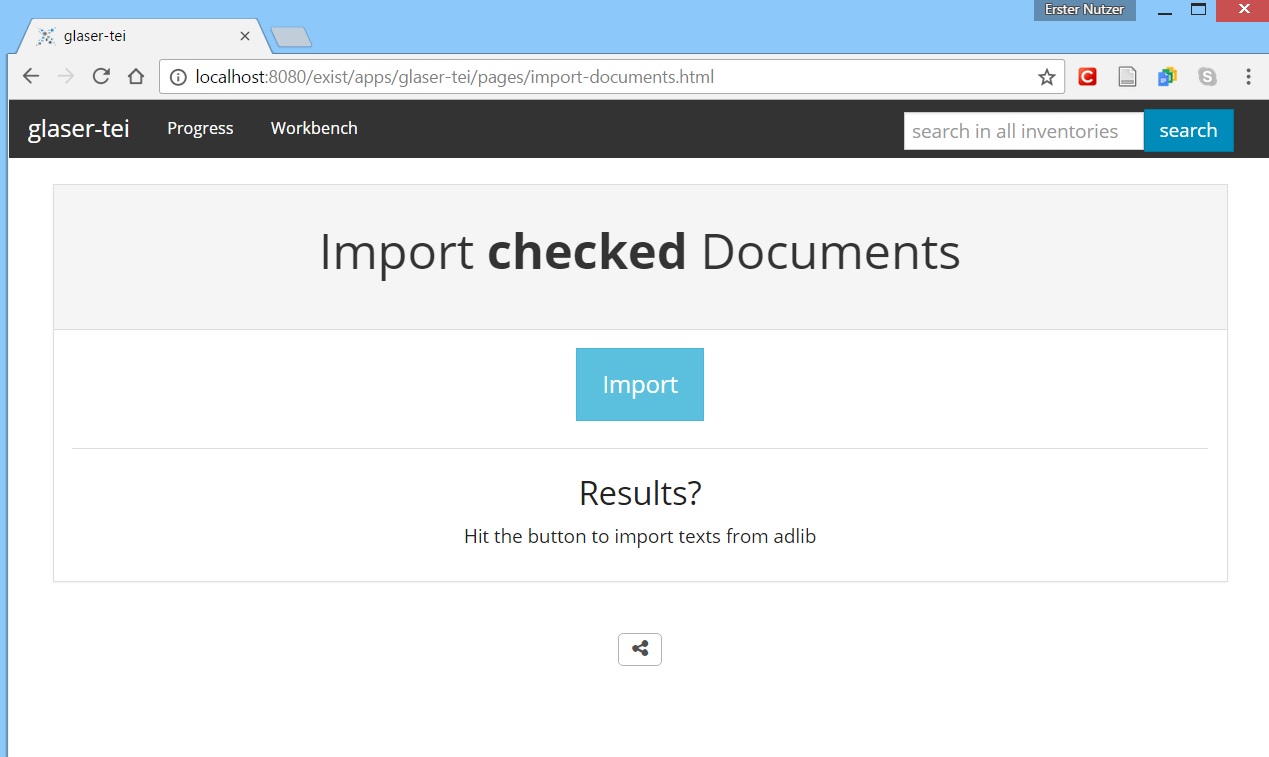 This will trigger a script called
This will trigger a script called totei:triggerBatchTrans. This script will
- read in the identifiers of those documents from this adlib-endpoint which have been marked as ready,
- check if this document is already stored in Glaser-TEI at
data/importedand if not, it will request the adlibXML, transform it with the stylesheetresources/xslt/adlibXMLtoTEI.xslinto a basic XML/TEI document, - and finally stores it in
data/imported.
resources/xslt/adlibXMLtoTEI.xsl does not much more then mapping (some) fields of adlibXML to the TEI (epidoc) data model but doesn't do anything with the actual transcribed texts. To parse the transcribed and partially annotated texts of the glaser squeezes which can be located at <div type="edition">:
- Go to 'Workbench -> Check and Process'.
- There you find an overview of all imported texts and a check, if the annotated transcriptions are valid.
- If a text is not valid, report this to the annotators and delete this document (by clicking on delete).
- if a text is valid (this means you can see the transcribed text), then click on process.
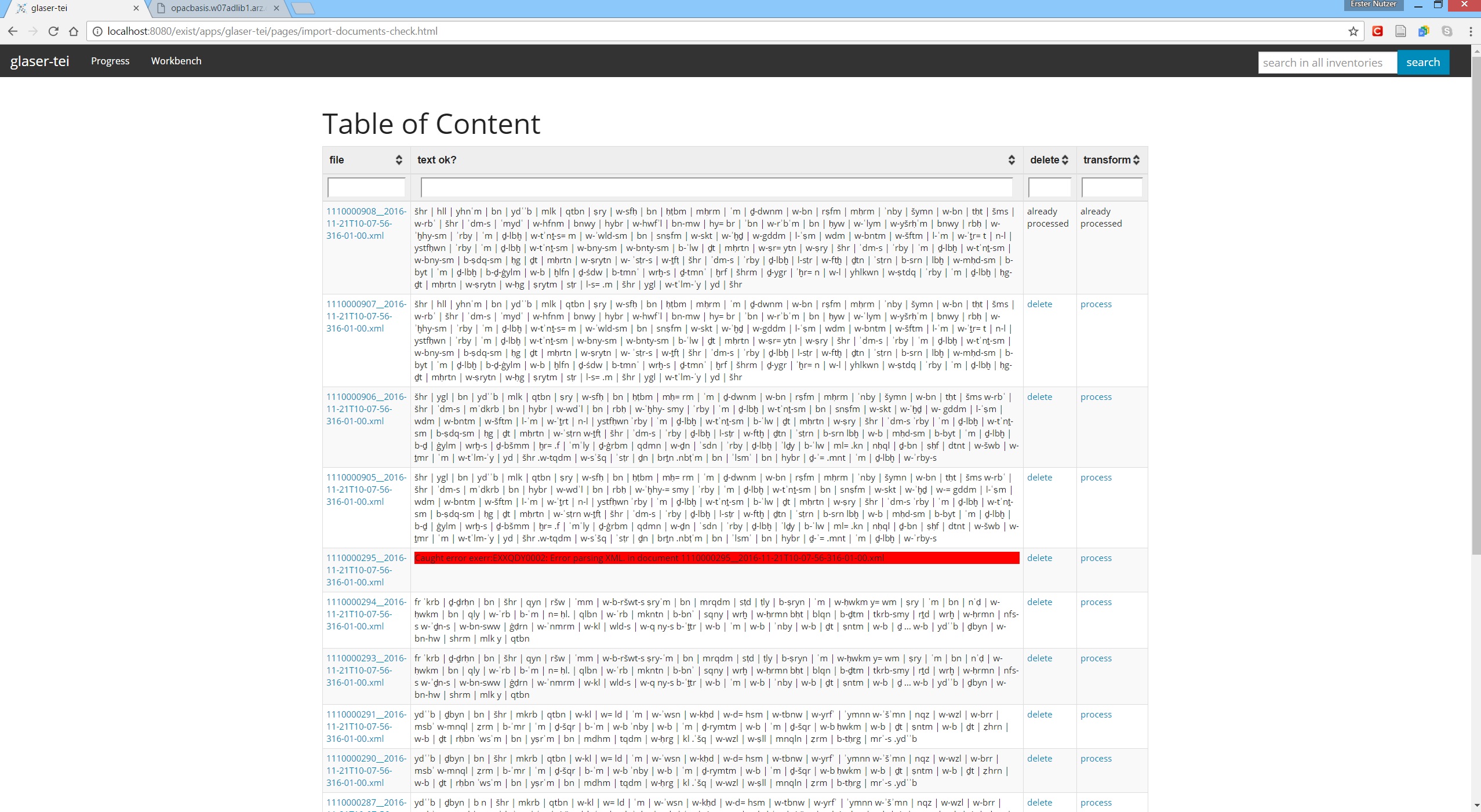
This will trigger the script totei:processDoc which will
- store a copy of the selected document and store it in
data/editions, and - transform the 'plain text markup' into XML/TEI valid markup.
Be aware that documents which have already been processed can't be deleted nor processed any more. This is made on purpose to avoid duplicates as well as to keep the data processing workflow replicable.
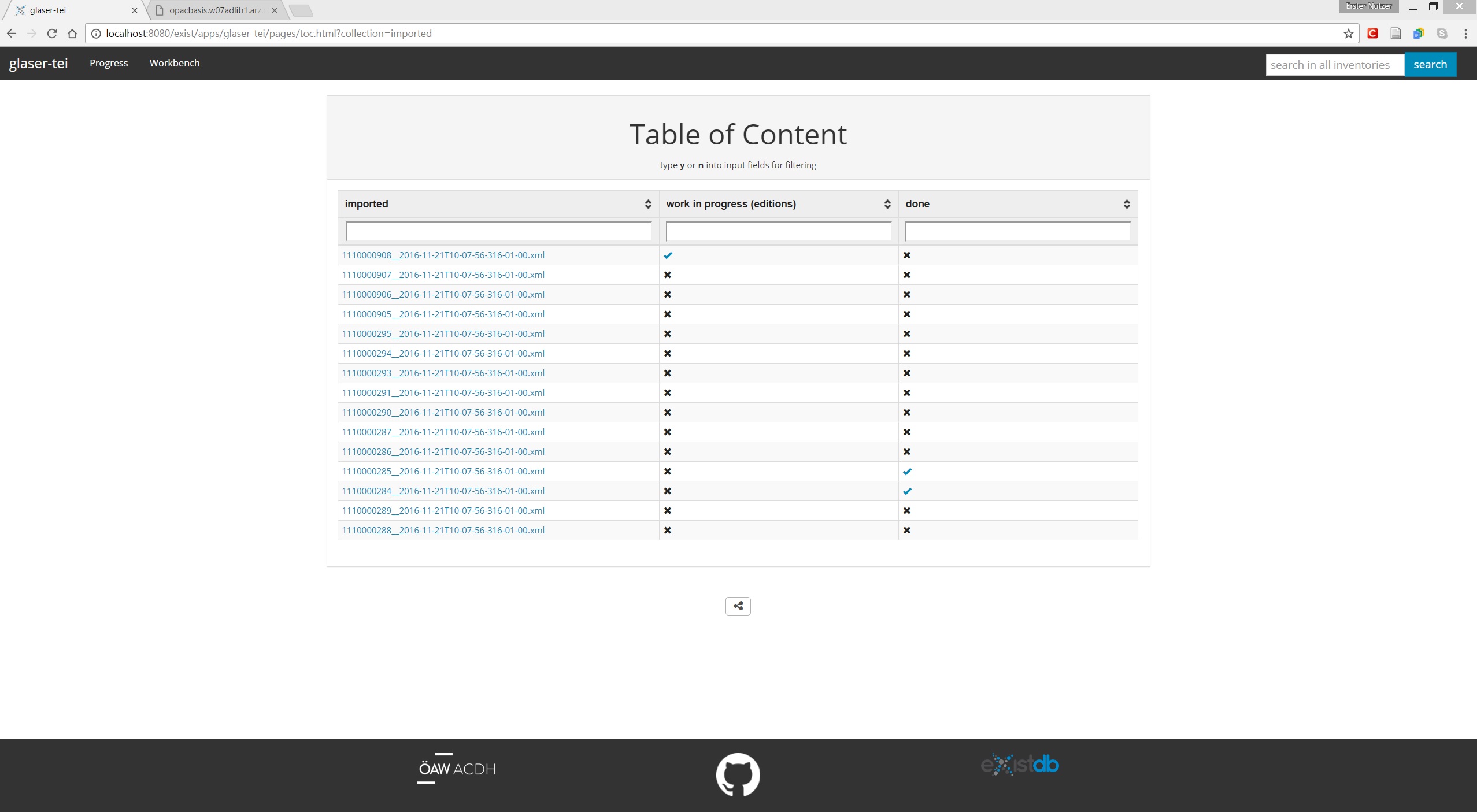
The status/progress of the annotation process can be checked at 'Progress -> Check Progress'. This overview lists all imported documents and shows, if those documents have been already processed or marked as done.
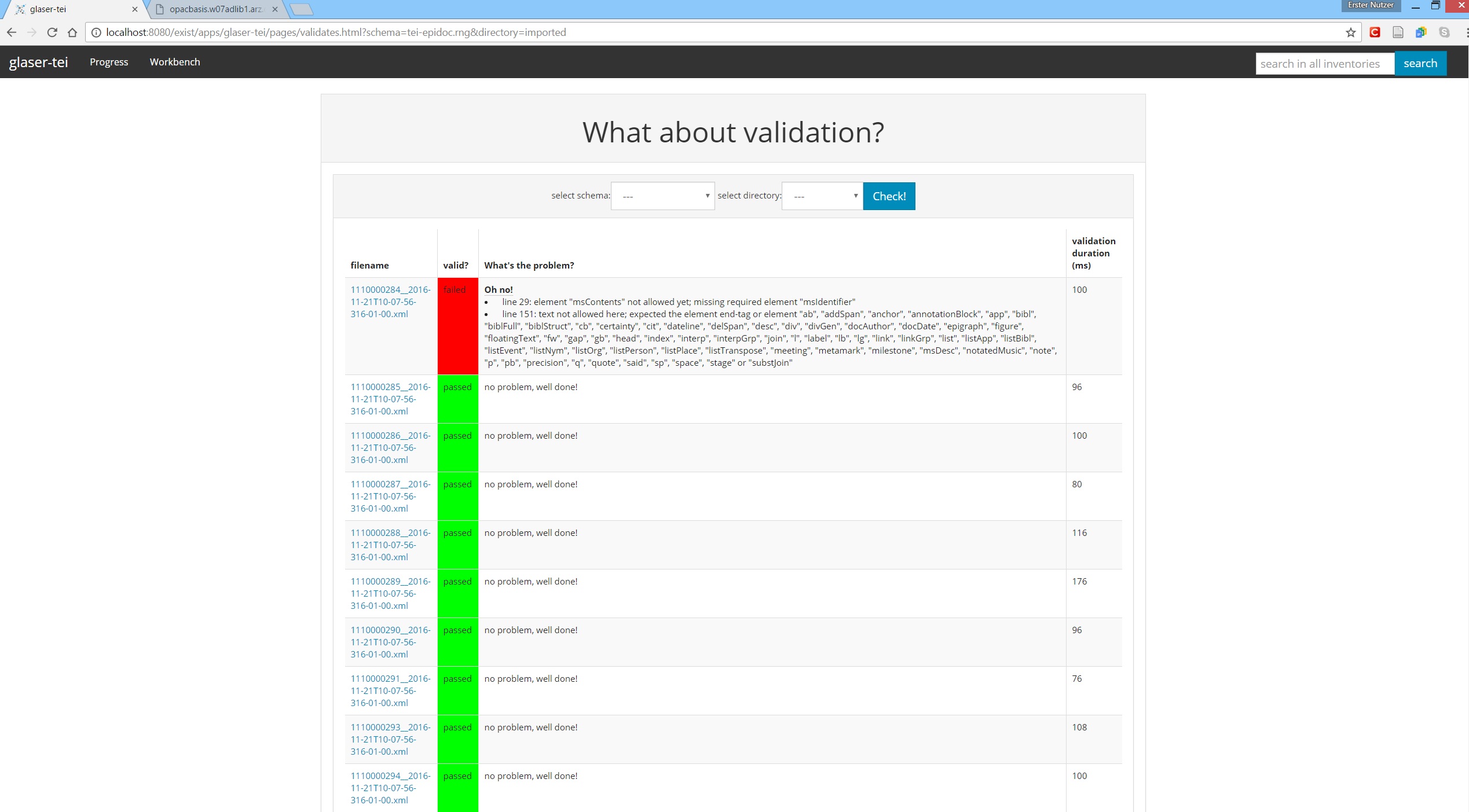
By browsing to 'Progress -> Valid?', you can quickly check all documents at any stage of the workflow if they validate against either the TEI or as well as the Epidoc schema. Simply select the schema and collection you would like to check and hit Check!. Ideally everything is green.
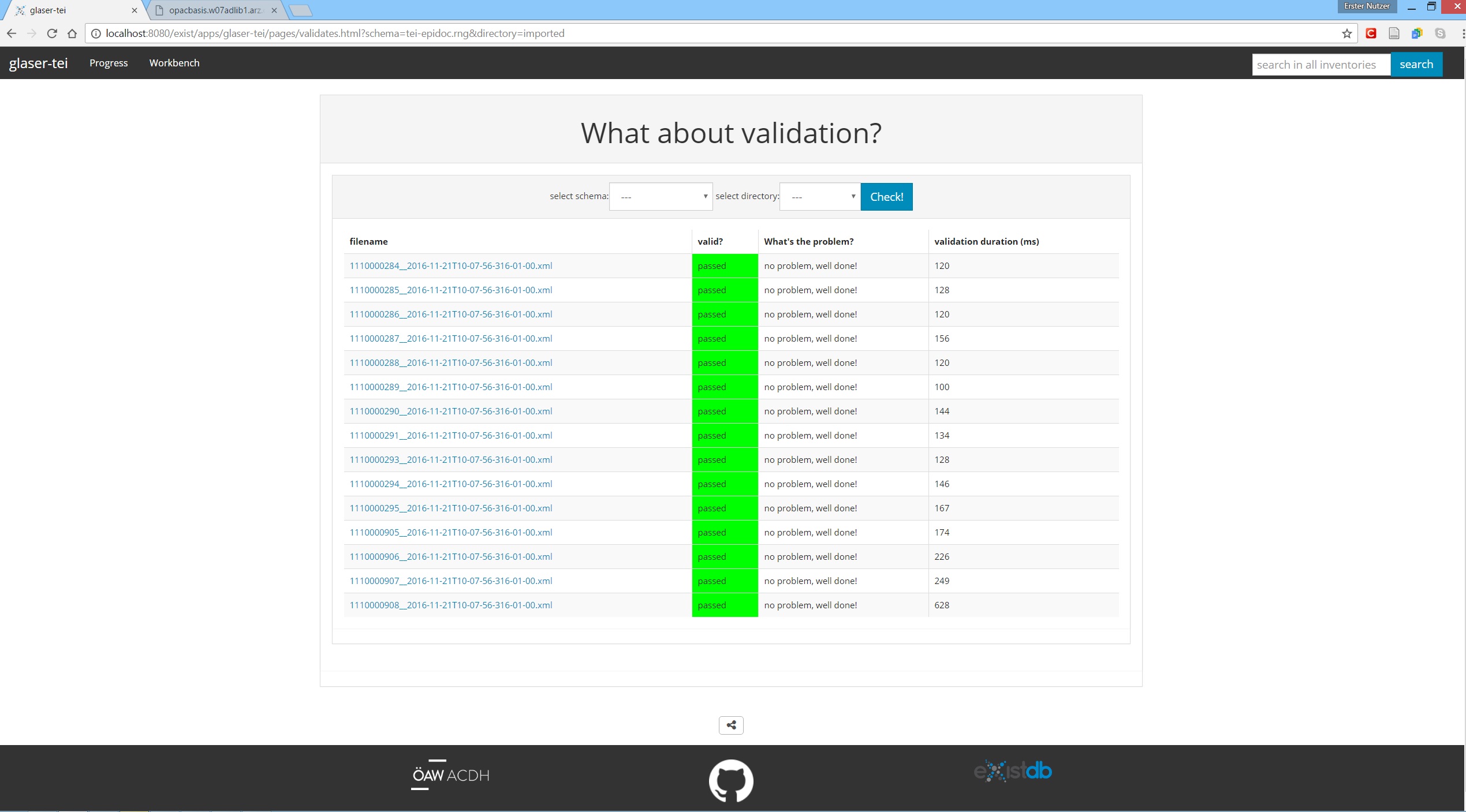
In case a document is not valid, the first few (in case there are more) errors will be listed.
After a document was successfully imported and process further, human annotators can start working with the processed documents adding e.g. semantical markup (tagging person, places...). This can be accomplished by