主要是对多模态视觉图像的网络架构进行综述,同时对大家当前使用的模型结构进行总结,方便今后的使用。
综述文章指的是多模态机器学习方法的综述文章。
下面是多模态融合的综述文章:
-
Ramachandram D, Taylor G W. Deep multimodal learning: A survey on recent advances and trends[J]. IEEE Signal Processing Magazine, 2017, 34(6): 96-108. 深度学习提供了方便的融合机制,这篇文章将多模态信息融合分为early fusion,intermediate fusion 和late or decision-level fusion。
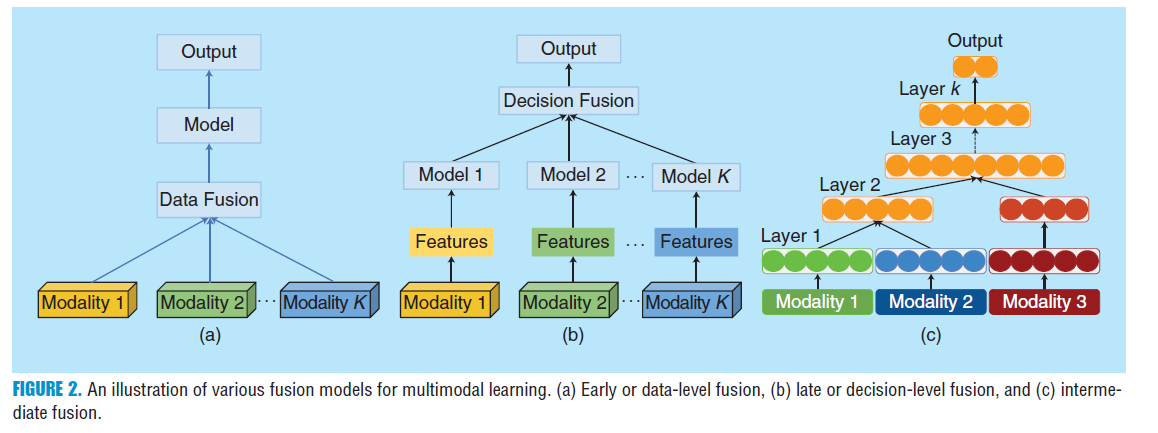
-
James A P, Dasarathy B V. Medical image fusion: A survey of the state of the art[J]. Information Fusion, 2014, 19: 4-19. 这篇文章综述了医学图像融合的方法,主要按照Morphology(形态,纹理,颜色等),Knowledge, Wavelets, Artificial neural networks, Fuzzy logic 这样进行分类。
像素级图像融合指的是直接对各幅图像的像素点进行信息综合的过程,算法简单、融合速度快,但减弱了图像的对比度。
常用的融合方法:平均和加权平均法、逻辑滤波法、彩色空间法、多分辨塔式算法、小波变换法。
1)平均的方法就是直接求各图像对应像素点的平均值,它可以增加图像的信噪比,但是会降低互补信息的对比度。加权平均法是对各图像像素点进行加权求和,权值的选择可以利用主成分分析法(PCA),PCA通过求输入图像协方差矩阵的特征向量挑选出最大特征值对应的特征向量,这个特征向量就是各幅图像对应的权值。
2)逻辑滤波方法有:“与”、“或”、用一种数据增强另一种数据、用一种数据抑制另一种数据。
3)彩色空间变换法利用彩色空间RGB(红、绿、蓝)模型和IHS(明度、色调、饱和度)模型各自在显示与定量计算方面的优势,将RGB空间模型转换到HIS空间,进行融合后再反变换回RGB空间进行显示。
4)多分辨率塔式融合算法较为常见,将原图像不断滤波形成一个塔状结构,在塔的每一层都用一种融合算法进行融合,然后将合成的塔式结构重构得到合成图像。
5)小波变换法将图像分解在不同频段的不同特征域上,然后在不同的特征域内进行融合,构成新的小波金字塔结构,再用小波逆变换得到合成图像。
前端融合指的是经过一定的特征提取过程进行的特征融合,或者是完全不做处理进行特征融合。
- Dong H, Yang G, Liu F, et al. Automatic brain tumor detection and segmentation using U-Net based fully convolutional networks[C]//Annual Conference on Medical Image Understanding and Analysis. Springer, Cham, 2017: 506-517.github 这篇文章将MRI的不同模态看作是图片不同的通道,可以看作是前端融合。
经过了一些神经网络的层,比如卷积层池化层后进行融合。
- Liu J, Zhang S, Wang S, et al. Multispectral Deep Neural Networks for Pedestrian Detection[J]. (BMVC, 2016)
这篇是讲双谱行人检测的,基于fasterrcnn方法,提出了4种将红外图像和彩色图像融合的方法,最终实验得出结论,在特征提取的中期,也就是在vgg16的第四层卷积层的时候融合效果最佳。 - Hazirbas C, Ma L, Domokos C, et al.FuseNet:Incorporating Depth into Semantic Segmentation via Fusion-based CNN Architecture. (ACCV,2016)
这篇文章强调了在浅层网络提取边缘特征的重要性,因此采用文中提出的Sparse Fusion方法,在池化层之前将深度网络的部分特征融合到RGB网络中。网络类型使用编码解码器架构,在SUN RGB-D上得到了76.27%的全局准确率。


在进行决策之前进行融合,通过对融合的信息进行处理,最后得到分类分割或者检测的结果。
- Wagner J, Fischer V, Herman M, et al. Multispectral Pedestrian Detection using Deep Fusion Convolutional Neural Networks (ESANN, 2016)
这篇是讲双谱行人检测的,基于caffenet提取特征,实验对比了前端融合和后端融合,得出结论,在全连接层(f7)之后对红外图像和彩色图像融合效果最佳。
- Andreas Eitel et al.Multimodal Deep Learning for Robust RGB-D Object Recognition.(IROS,2015)
这篇用于对象识别的RGB-D图像融合方法与上一篇提到的后端融合的方法相似,也是利用在ImageNet数据集上预训练的参数来初始化CaffeNet,然后在全连接层(f7)之后进行融合。
