| 기간 | 대회내용 | 결과 |
|---|---|---|
| 20.04.30 ~20.07.26 | 플레이리스트에 숨겨진 노래와 태그를 예측 | TOP 2% |
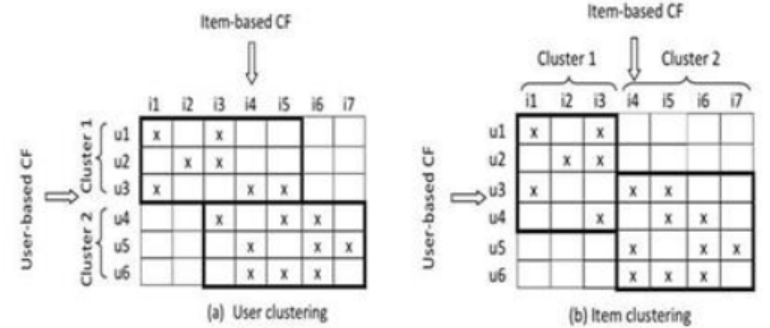
- Song의 개수가 70만개로 너무 크고, Item 기반 추천알고리즘은 매우 Sparse한 결과와 Memory Error를 낳았음 (RAM 20GB 사용시)
- 따라서 CF 진행 전 Clustering을 KNN으로 진행하고, 이 후 CF를 적용하여 각 Active user와 유사한 song_id를 출력함 (유사도는 cosine 사용)
- If-Else로 Song만 있는 경우, Tag만 있는 경우, 둘 다 있/없는 경우를 나누어 모델링
- 이 후 대회 마지막 과정에서 다양한 K를 설정하여 그 결과를 앙상블
- 플레이리스트의 제목, 발매 일자, 가수명, 앨범이름, 장르 등의 song_meta data에 있는 song의 side information을 자유롭게 CF에 첨가함
- 특히 제목은 Sentencepiece를 이용해 벡터화하였음
- 이들의 정보를 담은 Sind-info 행렬을 만들고 모두 곱하여 최종 추천에 이용함
vali = val_song * val_tag * val_title_genre * val_genre
cand_song = tra_song_sp_T.dot(vali) # 기존 행렬에 dot 연산으로 곱함-
자주 등장하지 않는 Minor 한 곡들의 Similarity에 가중치를 주기 위함
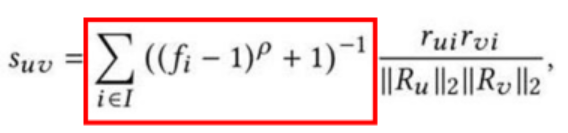
-
하지만 그리 좋은 성능은 보이지 못했음
- VAE, NCF, LightGBM을 팀원과 시도했지만 CF보다 성능이 좋지 못했음
- Reranking과 Denoising의 중요성을 너무 늦게 깨달아서 이에 집중하지 못했음