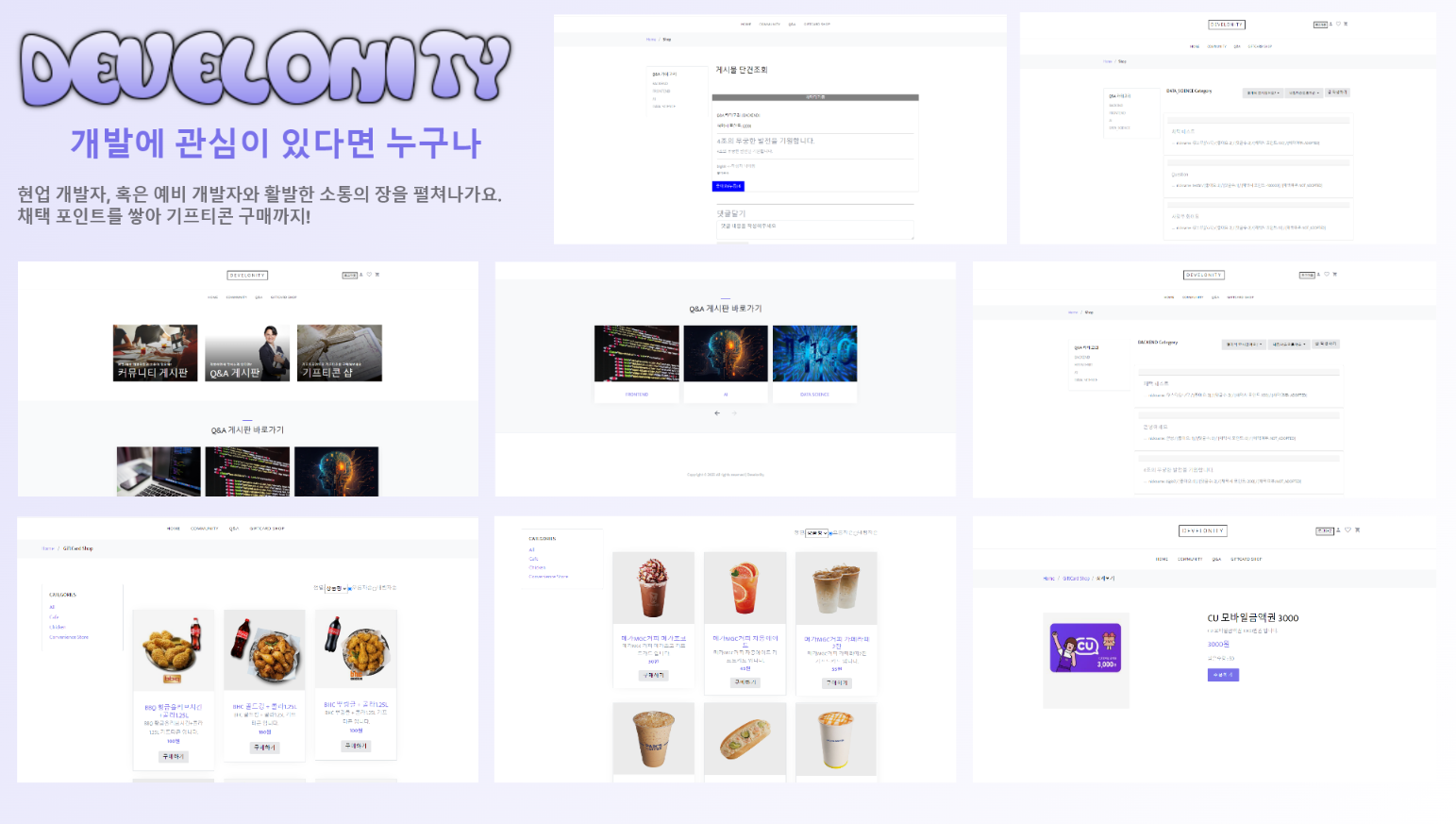
Develonity(Notion 링크✔️)
Developer+Community=Develonity
- 입문 & 주니어 & 시니어 개발자 모두에게 가치 있는 커뮤니티를 만들고자 했습니다.
- Q&A 게시판 활동(답변)을 통해
Gift Point를 쌓고, 포인트로Gift Card를 살 수 있습니다. - [미구현] Q&A 게시판 활동(답변)을 통해 단순히
Gift Point뿐만 아니라Respect Point가 쌓이게 되고,Respect Point를 기반으로외주, 과외 등의 서비스를 제공하고자 했습니다.
| 조성현 | 이솔 | 김태웅 | 배지호 | 송성원 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| 리더 | 부리더 | 팀원 | 팀원 | 팀원 |
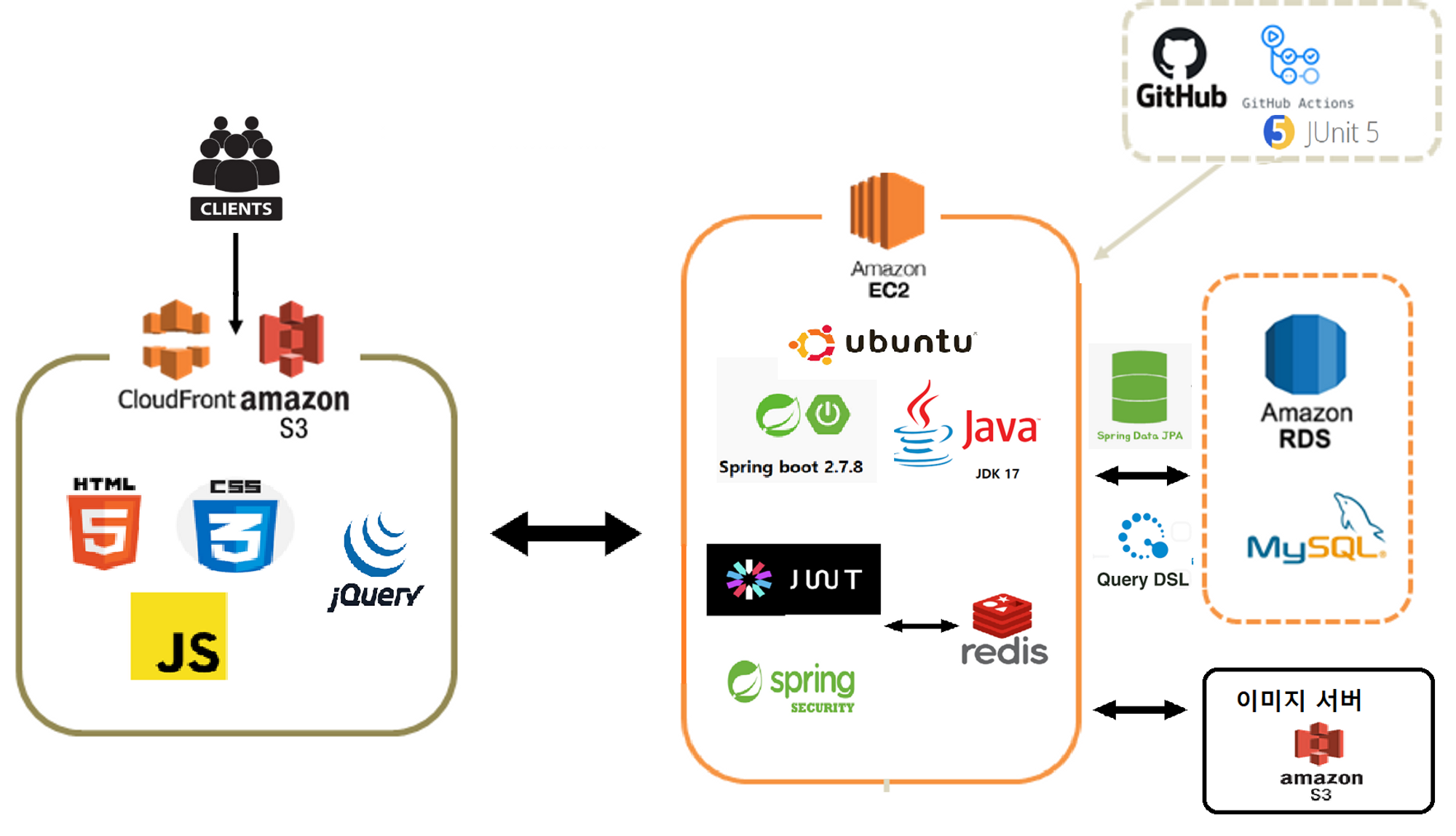
Front-End


Back-End











Server



Etc



Session vs Token(JWT)
- 보안 vs 효율&확장성
- 서비스의 특성상(커뮤니티) 보안적으로 매우 민감한 주제는 아니라고 판단
- HTTP의 비상태성(Stateless)를 그대로 활용할 수 있고, 따라서 높은 확장성을 가질 수 있는 Token방식을 채택
문제점
- 보안 이슈 발생
해결책
- refresh token을 도입하여 access token의 유효기간을 짧게 가져감
- RTR(refresh token rotation)을 도입하여 refresh token 탈취 시 문제점 완
- 계정정보 or 회원탈퇴 등 중요한 기능들은 ‘비밀번호 검증'을 1회 더 하는 방식으로 보안 강화
➕access token과 refresh token이 모두 탈취 당했을 경우에 대한 고민🤷
📋 참고자료
📌 현재 프로젝트에서 대응 가능한 방법들
-
사용자가 서비스를 지속적으로 이용중인 상황
- RTR(refresh token rotation)을 적용하고 access token의 유효시간을 30분으로 짧게 설정
[reissue 실패 → 재로그인 → 탈취된 refresh token 무효화]가능
- RTR(refresh token rotation)을 적용하고 access token의 유효시간을 30분으로 짧게 설정
-
토큰이 지속적으로 탈취되는 상황
- 해당 회원을 일단
탈퇴처리, 해커의 나쁜 행동을 막고, - 개인적으로 네트워크와 컴퓨터를 리셋(포맷)한 이후 다시
계정 복구(soft delete 방식으로 회원 탈퇴 기능 구현)
- 해당 회원을 일단
-
특정 상황이 발생하여 회원 다수의 token이 탈취된 경우
- 30분여 서비스 점검 실시(access token 유효기간 만료를 위함) 및
redis(refresh token 저장소)를 재가동하는 방법 고려. (서비스 점검기간동안 보안적인 대처도 병행)
- 30분여 서비스 점검 실시(access token 유효기간 만료를 위함) 및
-
현재 계정정보 접근, 회원탈퇴 등 민감한 서비스들에는
패스워드 재검증 로직을 포함하고 있으므로 개인정보 유출, 금전적 피해가 발생 가능한 경우는 예방하고 있다.
Redis - Token 저장소로 Redis를 선정한 이유
- Key(LoginId)-Value(Refresh Token) 외의 다른 필드가 필요하지 않음
- I/O가 빈번하게 발생하는 환경
- 저장된 데이터의 개수와 무관하게
O(1)의 수행시간을 가짐- 저장된 모든 token을 조회하는 등의 싱글 스레드의 단점이 부각 될 상황이 없음
Admin과 User 분리
기존 방식
- 동일한 User Entity에서
Role Enum으로 Admin과 User를 구분 - 동일한 security filter와 Authentication Service를 사용
문제점
- 근본적으로 User와 Admin의 생명주기가 다름
- User와 Admin의 역할과 그에 따른 기능들이 다름
- User와 Admin의 인증과정을 분리할 수 없음.
해결
- Entity 및 Package 분리
- security filter와 Authentication Service 분리
- Authentication Service에
팩토리 패턴적용하여 OCP 원칙을 지키고자 노력
게시글 JPA 상속 관계 매핑(단일 테이블 전략)
JPA는 DB와 객체를 매핑해주는 자바 진영의 ORM 기술 표준이지만 객체의 상속 관계와 정확하게 일치하는 DB모델링은 존재하지 않음
따라서 차선책으로 상속 관계와 비교적 유사한 슈퍼타입-서브타입 모델링 기법으로 DB를 상속 객체에 매핑
슈퍼타입-서브타입 논리모델을 실제 DB 물리모델로 구현하는 방법으로 3가지 전략 중 ➕단일 테이블 전략➕을 사용
📌 단일 테이블 전략의 장점
- 조인이 필요 없으므로 조회 성능이 빠름
- 조회 쿼리가 단순
📌 단일 테이블의 단점
- 하위 엔티티의 필드값은 모두 Null을 허용
- 하나의 테이블에 칼럼이 많아져 복잡
📌 단일 테이블 전략을 선택한 이유
현재 게시글의 필드값을 최대한 적게 가져가는 방식을 사용 중이기 때문에
테이블 칼럼 수가 적기 때문에 단일 테이블 전략을 사용하더라도 복잡해지지 않음비록 데이터베이스에는 Null값을 허용하더라도 실제 객체가 Null값을 가지고 있는 것은 아님
만약 단일 테이블 전략이 아니라 각자 테이블을 가지는 조인 전략과 같은 방식을 사용했다면
Null값은 들어가지 않지만 조회 쿼리가 복잡해지고 INSERT QUERY를 2번 실행해야 하기 때문에
단일 테이블 전략을 사용하기로 결정
ID를 활용한 간접참조 방식 설계
직접 참조 : Entity 클래스를 설계할 때 @OneToOne, @OneToMany와 같은 어노테이션을 써서 Entity 간에 연관 매핑하는 것
간접 참조 : 객체를 직접 참조하지 않고, 식별값을 이용하는 것
📌 직접 참조 방식의 단점
- 의존 관계 형성
- 연관 관계 맺은 객체를 편하게 탐색할 수 있고 바뀌길 원하지 않는 참조 객체의 값이 손쉽게 바뀔 가능성 존재(직접 참조는 편한만큼 위험)
- 예를 들어 Board Entity안에 user라는 변수가 있다면 Board를 다룰 때 User를 변경할 수 있는 가능성과 여러 실수의 가능성이 존재
- 즉 User 라는 Entity 자체를 날것으로 가져오게 되면, Entity 가 오염이 될 수 도 있음
-> setter 를 통해서든, 도메인 서비스를 통해서든 어떤 일이 벌어질 수 있는 가능성을 열어둔 것
📌결론
User Entity도 안전하게 보호가 되고, Board Entity에만 집중할 수 있는 방법으로 간접 참조 방식을 이용하는 것이 나을 것이라고 판단,
간접 참조를 하면 의존 관계가 형성되지 않아서 추후 시스템을 확장할 때도 유리하기 때문에
간접 참조 방식을 이용해서 설계
이미지 서버로 AWS S3 선정한 이유
📌 이미지 서버의 필요성
만약 스프링 서버의 멀티파트 파일로 이미지를 받아서 DB에 저장하는 방식을 이용 한다면
서버 여러대 사용 시, 특정 서버에만 이미지가 존재하게 될 수 있음
따라서 별도의 이미지 서버를 둘 필요성을 느낌
📌 S3를 이미지 서버로 선유한 이유
커뮤니티 사이트처럼 서버에 많은 미디어 파일을 저장해야 하는 경우
EC2와 EBS만을 사용해서 저장을 하게 되면 용량에 따른 과금도 부담되고 (비용적인 문제, S3는 사용한 만큼만 비용 지불)
저장소를 구축해서 관리하는 것에도 문제 존재(성능 문제)하지만 S3를 사용하면 S3 한 곳에 모든 미디어 파일을 저장할 수 있고
비용적인 문제도 EC2와 EBS만을 사용해서 구축하는 것보다 훨씬 저렴하며
구축 후 확장이나 축소와 같은 DB를 관리하는 것에도 용이하다는 장점이 있어 사용📖 S3와 EBS 중 S3를 선택한 이유
- S3가 더 저렴함
- EBS는반드시 하나의 인스턴스에서만 접근 할 수 있음 -> 여러 Application이 하나의 EBS에 담겨있는 데이터에 동시 접근 불가능
- 생성 전에 반드시 그 크기를 지정해주어야 함
- 신청한 용량 중, 쓰지 않는 부분에 불필요한 cost를 내야함
- 쌓이는 데이터가 신청한 용량을 넘어서게 되는 경우, 대용량에 새로운 volume을 신청하여 데이터를 옮기고, 기존에 volume을 반납해야하는 번거로움이 생김
S3는 사용한 만큼만 비용을 지불하고, 무한대로 확장이 가능하며, EBS와는 다르게 여러개의 Application이 동시에 접근할 수 있다는 장점이 있으므로 S3을 선택함

4조가 트러블 슈팅 or 성능개선을 하는 방식
-
안건제시
-
문제분석
-
개선계획수립
-
코드 수정
-
PR을 통해 검토
-
반영
- 실제 예시 링크(23.02.22 보드,코멘트 관련 비상회의록)
CI - sub module & profile & embedded redis 기반의 배포, 테스트 환경 분리
Pre-signed URL 방식을 택한 이유
클라이언트에서 S3에 파일을 업로드 하는 방법은 크게 3가지 존재
1. AWS SDK를 이용해 직접 업로드
2. API 서버에 파일을 전달하고 API 서버에서 S3에 업로드(기존 적용 방법)
3. PreSignedURL을 이용한 클라이언트 -> S3 업로드(트러블 슈팅 후 적용 방법)

📌 1, 2번 방식의 단점
-
1번 방법
- 서버를 거치지 않지만, AWS SDK를 써서 S3이용이 가능해야 하기 때문에 클라이언트에서 AWS SDK를 사용하는 시점에는
결국 AWS Access Key와 Secret Key 정보를 알고 있어야 함
->Key 정보 노출 위험성 존재
- 서버를 거치지 않지만, AWS SDK를 써서 S3이용이 가능해야 하기 때문에 클라이언트에서 AWS SDK를 사용하는 시점에는
-
2번 방법 (기존 프로젝트 진행 방식)
- API서버에서 파일을 업로드하기 때문에 AWS Access Key와 Secret Key 정보를 서버가 가지고 있어 Key 정보가 노출되는 위험 없음
- 하지만 파일 업로드 시, 파일 전달 흐름이 클라이언트 -> 서버 -> S3 순으로 되게 되는데
- 이는 저장하지도 않을 파일들이 서버를 통해가면서 불필요한 서버의 리소스를 사용하게 됨
- 또한 과도한 업로드 작업이 생기면 서버에 과부하가 걸리게 되고 서버를 거쳐가는 지연시간이 생기게 됨
- API서버에서 파일을 업로드하기 때문에 AWS Access Key와 Secret Key 정보를 서버가 가지고 있어 Key 정보가 노출되는 위험 없음
위 방법들의 단점을 보완하기 위해 Pre-signed URL 기능을 사용하여 성능을 개선

📋 하나의 파일을 S3에 업로드하기 위한 Pre-signed URL 과정은 다음과 같음
- 클라이언트에서 서버에 pre-signed URL를 받기 위한 API 호출 (POST 요청)
- 서버에서 AWS S3에 pre-signed URL요청 3. AWS에서 pre-signed URL을 서버에 반환
- 서버는 반환받은 pre-signed URL를 클라이언트에 전달
- 클라이언트에서 AWS pre-signed URL로 이미지 upload (S3에 직접 업로드) (PUT 요청)
- 서버에게 해당 요청이 종료 되었음을 알림
서버의 역할이 파일 업로드를 처리하는 것에서 문자열을 주고받는 식으로 바뀌었기 때문에
프로세스가 훨씬 가벼워지고 브라우저에서 Key를 직접 만지지도 않아 보안성이 우수해짐
QueryDSL
📌 QueryDSL을 적용한 이유 (개선 전)

위와 같이
Spring Data Jpa를 이용해서 조회 기능을 구현 하기에는 검색 조건 등 여러 부분에서 작동이 효율적으로 되지 않았고,여러 조건의 검색 방식을 구현하기 위해서는 비슷한 메소드들을 추가로 작성 해줘야 해서
비효율적이었음
📌QueryDSL을 적용한 이유 (개선 후)
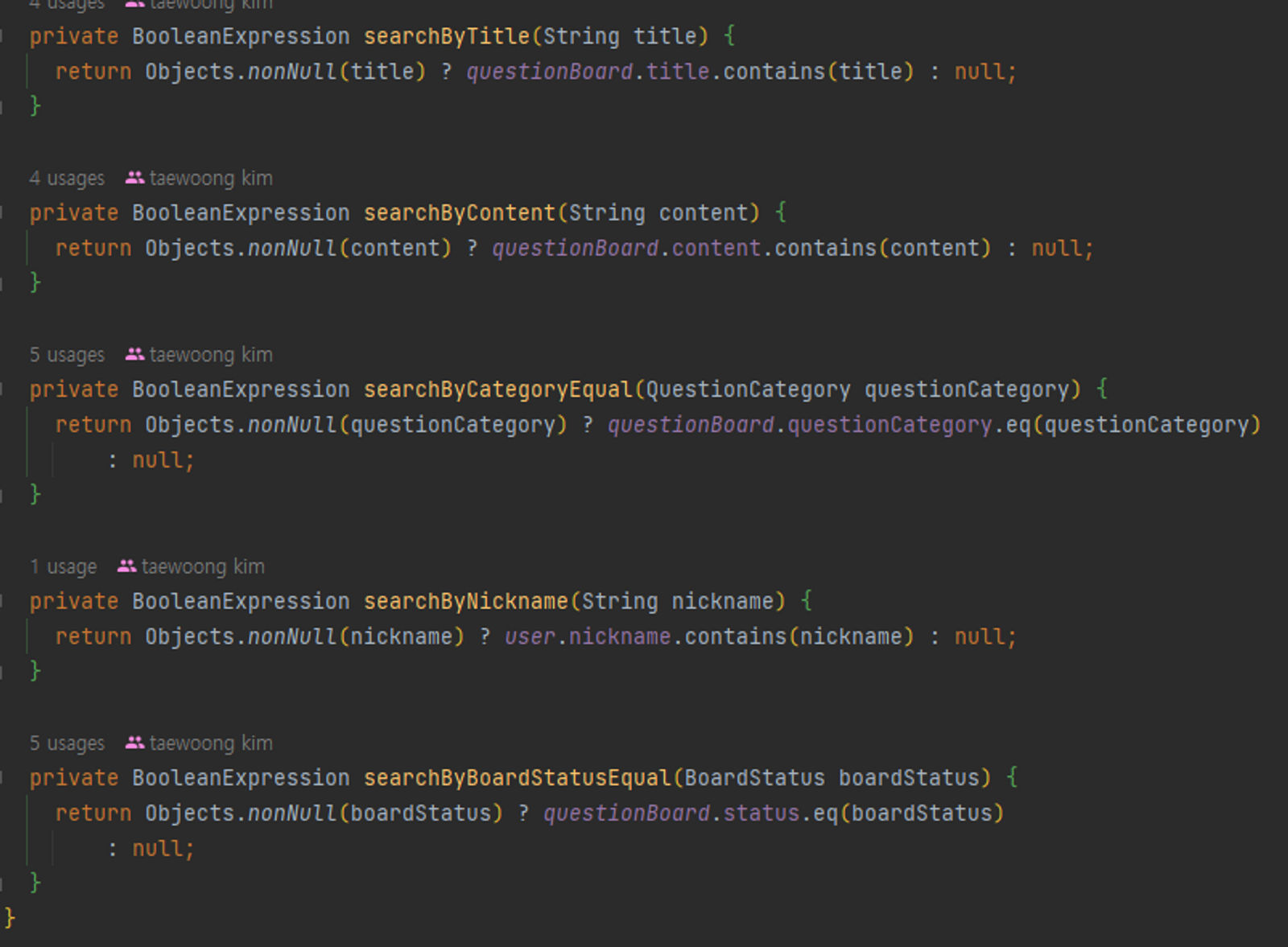

하지만 QueryDSL을 활용, 동적 쿼리를 작성해서 편하게 구현이 가능해짐
동적 쿼리란 상황에 따라 다른 문법의 SQL을 적용하는 것을 의미
예를 들면 DB에서 값을 조회할 때 조회 조건이 위와 같이 동적으로 바뀌어야 하는 경우가 많음
이런 상황을 Querydsl을 사용해서 손쉽게 해결
Querydsl은 아래 2가지 기능을 제공
where()에null이 들어오면 무시where()에 **,**을and조건으로 사용
🔓 BooleanExpression**을 사용해서 삼항 연산자를 통해 위 기능을 활용 했고, 한개의 메소드로 여러 검색 조건을 활용할 수 있게 하였음