В качестве интерфейса к полученной нейронной сети выступает телеграм бот.

https://drive.google.com/file/d/1OdMsht9yxQMAfLNkoebZCSQmyz05CRRc/view?usp=share_link
В данной работе рассмотрены несколько архитектур сверточных нейронных сетей для решения задачи восстановления знаков препинания в неструктурированном тексте, при моделировании задачи как проблемы многоклассовой классификации.
Важность решения задачи расстановки знаков препинания в сплошном неструктурированном тексте заключается в практической пользе, которое оно принесет для различных направлений обработки естественных языков. К примеру, в настоящее время задача распознавания человеческой речи решается множеством различных способов, но большинство из них на выходе выдают сырой сплошной текст, состоящий из набора распознанных слов. Такоq текст трудно читаем для человека, привыкшего к тексту, разбитому на отдельные предложения. Характерным примером такого сервиса является Youtube, который способен распознавать произносимый на видео текст, но не расставляет знаки препинания. К тому же отсутствие структуры в распознанном тексте затрудняет работу с ним систем автоматического перевода.
Текст разбивается на отдельные токены, каждому из которых присваивается класс, соответствующий знаку пунктуации, идущему после него. Имея на входе набор из n токенов, нужно предсказать знак препинания, стоящего по середине. То есть предсказания делаются не для каждого отдельного, а лишь для слова стоящего в середине окна, поданного на вход как показано ниже. Для предсказания знаков для всего текста используется обход скользящим окном.
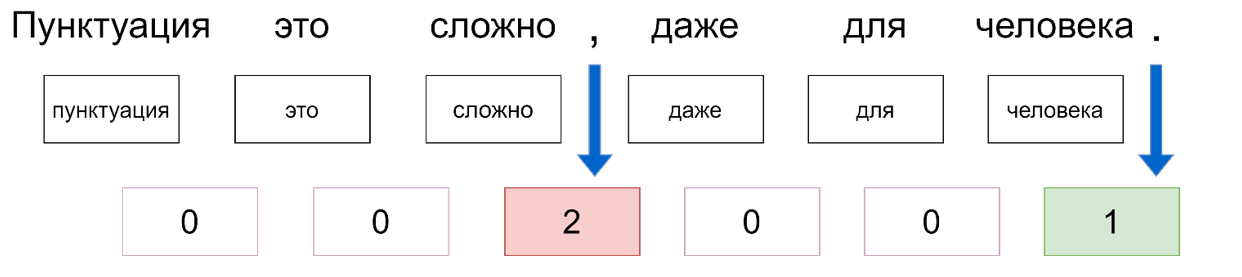
Постановка задачи приведенная выше неизбежно ведет к проблеме несбалансированности классов. В особенности это заметно для классов вопросительного и восклицательного знака, их суммарное количество составляет меньше одного процента от общего объема данных, что делает затруднительным их предсказание с помощью машинного обучения. Поэтому было решено объединить все классы, означающие конец предложения в один общий класс END – конец предложения.
Модель основана на переносе знаний от языковом модели ruBERT методом feature extraction и использовании сверточной сети для выполнения прогноза знака препинания по контексту окружающих его слов. Обучение модели проводилось на датасете SynTagRus. Достигаемая метрика качества F1 достигает 0.81 на тестовом датасете и 0.88 на новостном lenta.ru.
Более подробно все описано в приложенной статье.
Результат работы сети представлен ниже

Для тестирование нейронной сети приложен jupyter notebook CNN_Punctuation_Restoration_Demo с описанием работы и взаимодействия с сетью.
Также доступен python script - punctRest.py
Сеть использует модель ruBert для создания эмбеддингов. Скачивание в тетрадке происходит автоматически.
Для использование консольного скрипта скачайте модель ruBert с официалного сайта.
Ссылка на официальный сайт - http://docs.deeppavlov.ai/en/master/features/models/bert.html
Видео демонстрация работы скрипта - https://drive.google.com/file/d/1_gTkOZ_omy4ntoIRXCyUTXFF2c7B9mTz/view?usp=sharing
--model-path / -m - Локальный путь до модели punctRestorationModel.pth
default='./models/punctRestorationModel.pth'
--bert-path / -b - Локальный путь до модели ruBERT. Модель должна быть скачана и распокована по указанному пути.
default='./models/bert'
--text / -t - Текст для обработки
default="Пусто"
--device / -d - Использовать CPU или GPU для обработки
default="cpu"
train_1 - https://drive.google.com/file/d/1-0O_y6pFl0f3lPI18_PjGGdc_pzcV5-9/view?usp=sharing
train_2 - https://drive.google.com/file/d/1-3YCabppT0G3a1luQWpa0L0Z-bHUGRYa/view?usp=sharing
train_3 - https://drive.google.com/file/d/1-3c4saBL_0ClH2nlEEClChEVvJM5Dl8g/view?usp=sharing
test - https://drive.google.com/file/d/1--yQ465xpCmB_z61q1XqbQEaH9G4bRdi/view?usp=sharing
validation - https://drive.google.com/file/d/1-GMghRdG9SDvKBMT7LVlTCIOKT2Ci_NF/view?usp=sharing