This is the source code for the second place solution to the RSNA2019 Intracranial Hemorrhage Detection Challenge.
Video overview: link
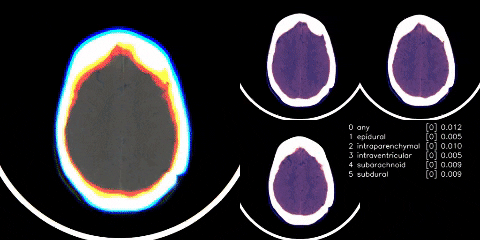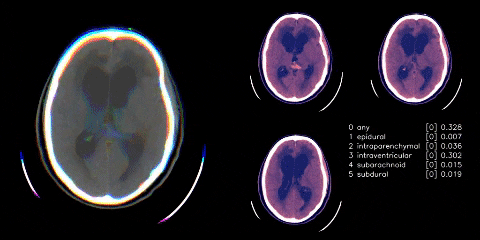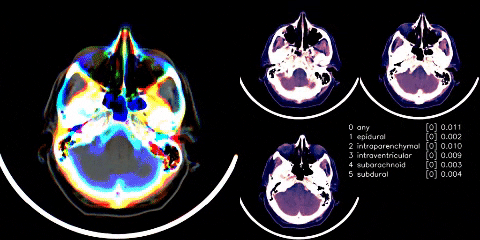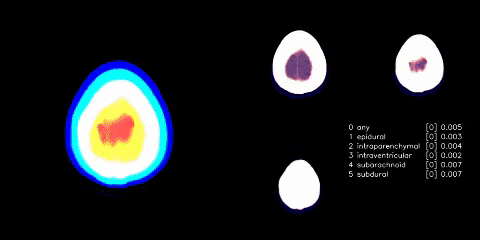
{kind=link}
We have a single image classifier (size 480 images with windowing applied), where data is split on 5 folds, but only trained on 3 of them. We then extract the GAP layer (henceforth, we refer to it as the embedding) from the classifier, with TTA, and feed into an LSTM. The above is run with and without preprocessed crop of images; however, just with preprocessed crop achieves same score.

Ubuntu 16.04 LTS (512 GB boot disk)
Single Node of 4 x NVIDIA Tesla V100
16 GB memory per GPU
4x 1.92 TB SSD RAID 0
Dual 20-core Intel® Xeon®
E5-2698 v4 2.2 GHz
Please install docker and run all within a docker environement.
A docker file is made available RSNADOCKER.docker to build.
Alternatively you can call dockerhub container darraghdog/kaggle:apex_build.
- Install with
git clone https://github.com/darraghdog/rsna && cd rsna - Download the raw data and place the zip file
rsna-intracranial-hemorrhage-detection.zipin subdirectory./data/raw/. - Run script
sh ./bin/run_01_prepare_data.shto prepare the meta data and perform image windowing.
Note: Hosted pretrained weights are downloaded here. The same weights can be obtained by running the below in the docker.
import torch
model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x8d_wsl')
torch.save(model, 'resnext101_32x8d_wsl_checkpoint.pth')
These steps create the below directory tree.
.
├── bin
├── checkpoints
├── data
│ └── raw
│ ├── stage_2_test_images
│ └── stage_2_train_images
├── docker
├── documentation
├── preds
└── scripts
├── resnext101v01
│ └── weights
├── resnext101v02
│ └── weights
└── resnext101v03
│ └── weights
└── resnext101v04
└── weights
- fast lstm train and prediction
a) runs in 3 hours
b) only trains lstm, used pretrained embeddings
c) only stage 1 test available for download
b) uses precomputed resnext embeddings for a single fold - single run on all training data
a) expect this to run for 2 days
b) produces single model on all data from scratch - retrain models
a) expect this to run about 10 days on a single node
b) trains all models from scratch
c) makes full bagged submission prediction. Note: each time you run/rerun one of the above, you should ensure the/predsdirectory is empty.
- Run script
./bin/run_31_fastprediction_only.shto download embeddings for a single fold (stage 1 only). This model will achieve a top20 stage 1 result.
... if you wish to download stage 2 embeddings runwget gdown https://drive.google.com/uc?id=1YxCJ0mWIYXfYLN15DPpQ6OLSt4Y54Hp0
... when you rerun you will need to replace the embeddings & torch dataloaders with the above downloaded, and also change the lstm step datapath to--datapath datain the lstm run.
- Run script
./bin/run_21_trainsngl_e2e.shto train on all data and for 3 epochs only. This was tested end to end and scored0.04607on private stage 2 leaderboard.
- Run script
sh ./bin/run_12_trainfull_imgclassifier.shto train the image pipeline. - Run script
sh ./bin/run_13_trainfull_embedding_extract.shto extract image embeddings. - Run script
sh ./bin/run_14_trainfull_sequential.shto train the sequential lstm. - Run script
python ./scripts/bagged_submission.pyto create bagged submission.
Preprocessing:
- Used Appian’s windowing from dicom images. Linky
- Cut any black space back to edges of where non-black space begins; although keep the square aspect ratio. Linky
- Albumentations as mentioned in visual above. Linky
Image classifier
- Resnext101 - did not spend a whole lot of time here as it ran so long. But tested SeResenext and Efficitentnetv0 and they did not work as well.
- Extract GAP layer at inference time Linky
Create Sequences
- Extract metadata from dicoms (taken from public kernels) : Linky
- Sequence images on Patient, Study and Series - most sequences were between 24 and 60 images in length. Linky
LSTM
- Feed in the embeddings in sequence on above key - Patient, Study and Series - also concat on the deltas between current and previous/next embeddings ( and ) to give the model knowledge of changes around the image. Linky
- LSTM architecture lifted from the winners of first stage toxic competition. This is a beast - only improvements came from making the hiddens layers larger. Oh, we added on the embeddings to the lstm output and this helped a bit also. Linky
- For sequences of different length, padded them to same length, made a dummy embedding of zeros, and then threw the results of this away before calculating loss and saving the predictions.
What did not help...
Too long to do justice... mixup on image, mixup on embedding, augmentations on sequences (partial sequences, reversed sequences), 1d convolutions for sequences (although SeuTao got it working)
Given more time
Make the classifier and the lstm model single end-to-end model.
Train all on stage2 data, we only got to train two folds of the image model on stage-2 data.