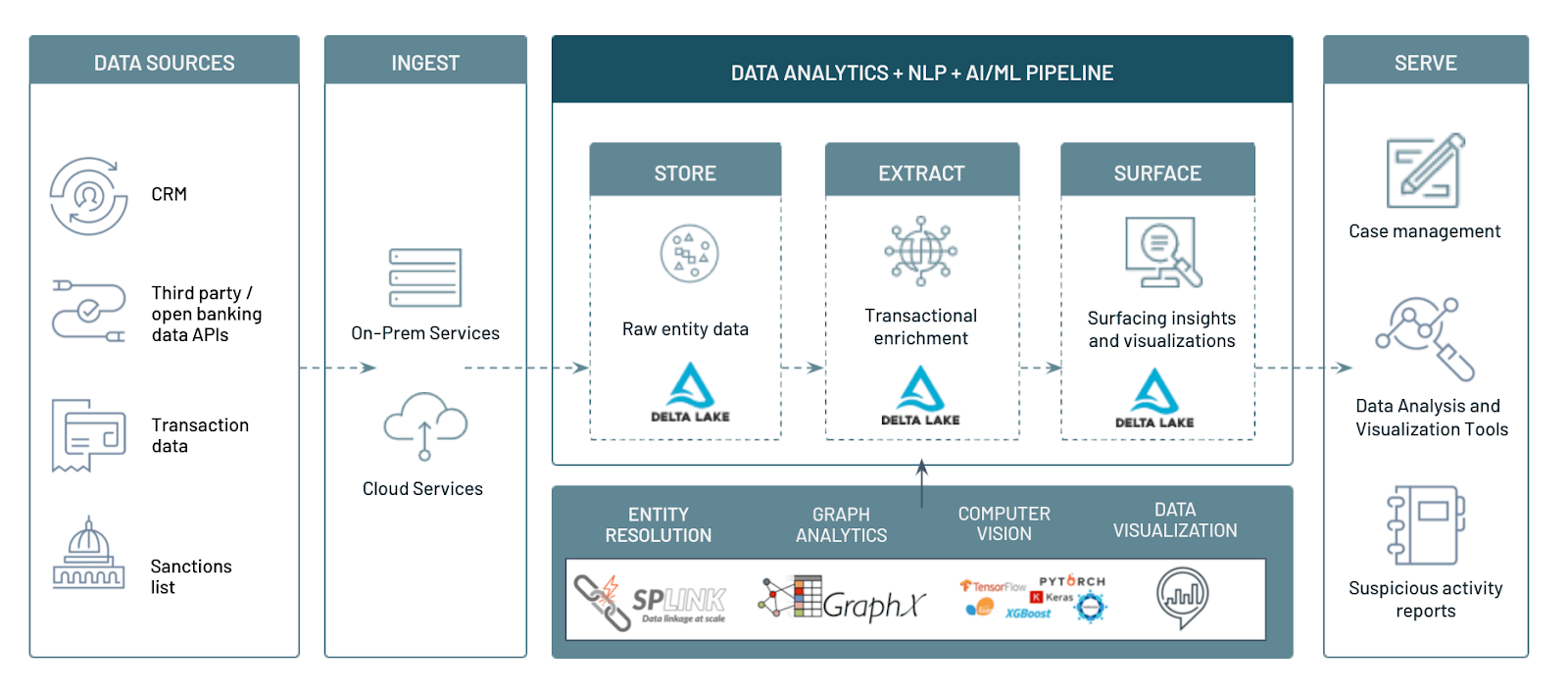
Anti-Money Laundering (AML) compliance has been undoubtedly one of the top regulatory agenda items in the United States and across the globe to provide oversight of financial institutions. Given the shift to digital banking, Financial Institutions process billions of transactions every day and the scope for money laundering grows every day even with stricter payment monitoring and robust Know Your Customer (KYC) solutions. In this solution, we would like to share our experiences working with our customers on how FSI can build an Enterprise-scale AML solution on a Lakehouse platform that not only provides strong oversight but also provides innovative solutions to scale and adapt to the reality of modern ways of online money laundering threats. Through the concept of graph analytics, natural language processing (NLP) as well as computer vision, we will be uncovering multiple aspects of AML prevention in a world of Data and AI.
anindita.mahapatra@databricks.com, ricardo.portilla@databricks.com, sri.ghattamaneni@databricks.com
© 2021 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| graphframes:graphframes | Graph library | Apache2 | https://github.com/graphframes/graphframes |
| torch | Pytorch library | BSD | https://pytorch.org/ |
| Pillow | Image processing | HPND | https://python-pillow.org/ |
| Splink | Entity linkage | MIT | https://github.com/moj-analytical-services/splink |
To run this accelerator, clone this repo into a Databricks workspace. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs.
The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.