![]()
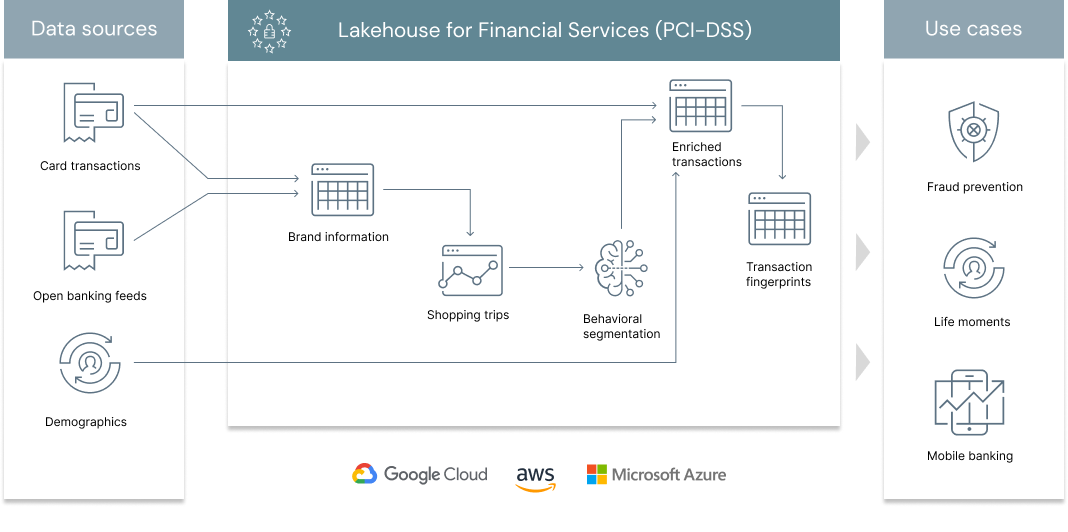
In a previous solution accelerator, we demonstrated the need for a Lakehouse architecture to address one of the key challenges in retail banking, merchant classification. With the ability to classify card transactions data with clear brands information, retail banks can leverage this data asset further to unlock deeper customer insights. Moving from a traditional segmentation approach based on demographics, income and credit history towards behavioral clustering based on transactional patterns, millions of underbanked users with limited credit history could join a more inclusive banking ecosystem. Loosely inspired from the excellent work from Capital One and in line with our previous experience in large UK based retail banking institutions, this solution focuses on learning hidden relationships between customers based on their card transaction pattern. How similar or dissimilar two customers are based on the shops they visit?
© 2022 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License [https://databricks.com/db-license-source]. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| PyYAML | Reading Yaml files | MIT | https://github.com/yaml/pyyaml |
To run this accelerator, clone this repo into a Databricks workspace. Switch to the web-sync branch if you would like to run the version of notebooks currently published on the Databricks website. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs. The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.