{kind=link}
{kind=link}
A speedy and reliable word indexing application designed to quickly index each word in large text files, providing instant access to the most frequent words in the directory.
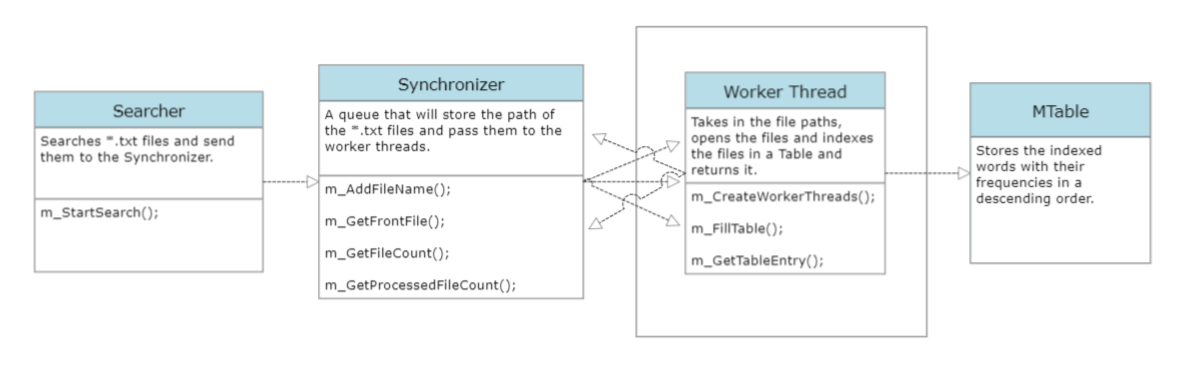
A multi-threaded text file indexing command line application in C++ that works as follows: The project is a C++ command-line application for indexing text files in a directory tree and finding the top 10 most frequent words. Users input a directory path through the command line as the starting point for the search.
A single thread searches through the specified directory and its sub-directories. Text files with a '.txt' extension are identified and handed off for processing. The search thread continues searching while processing is ongoing for efficiency.
A fixed number (N) of worker threads, for instance, N=3, process the text files concurrently. Worker threads handle the content processing of the text files.
Worker threads open each text file and read its content. Content is processed word by word, delimited by non-alphanumeric characters. This approach normalizes words, making comparisons case-insensitive and removing punctuation.
A shared table in memory is used to track unique words and their occurrence counts. Words encountered are updated in this master table. Threads access the same table, preventing data inconsistencies.
Worker threads update the master table with encountered words and their counts. The synchronized approach avoids conflicts among threads.
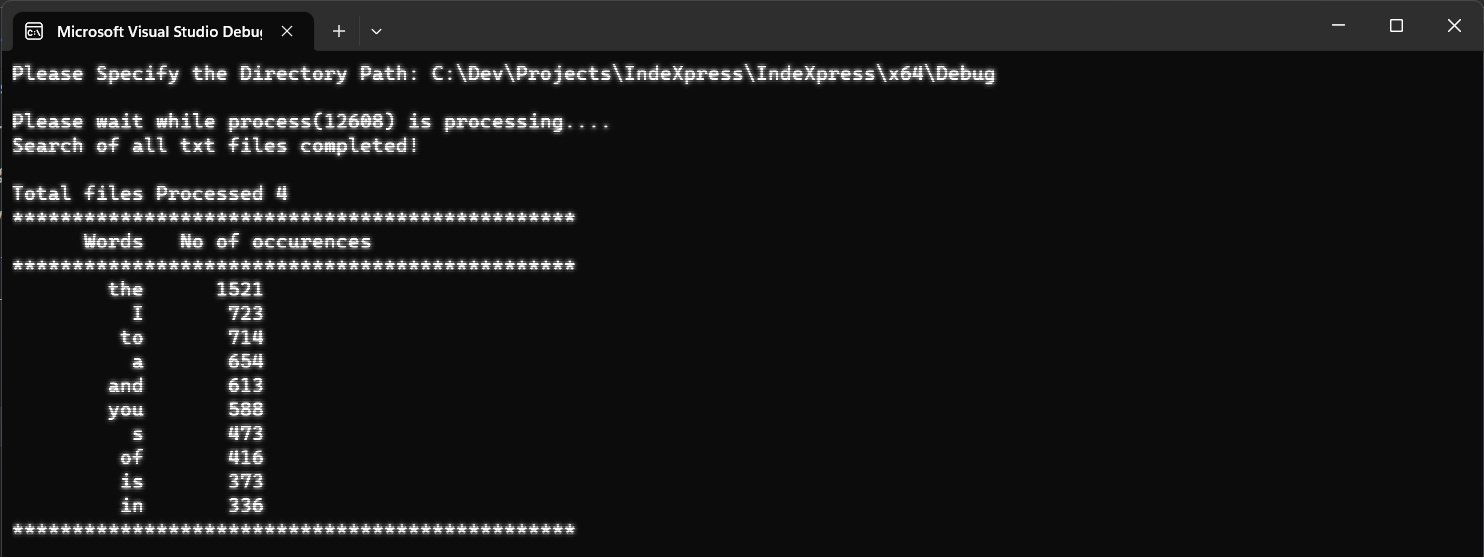
Once all text files are processed, the application extracts the top 10 most frequent words. These words, along with their counts, are displayed as the final output. In essence, this project creates a multi-threaded C++ application that efficiently traverses directories, processes text files, and maintains a shared data structure to count and rank words. The application's end result is a list of the top 10 words and their counts, offering insights into the textual content across the specified directory tree.
Developed in Microsoft Visual Studio 2022
IndeXpress -> |
| -- IndeXpress -> |
| -- IndeXpress.cpp
| -- IndeXpress.vcxproj
| -- IndeXpress.vcxproj.filters
| -- Searcher.cpp
| -- Searcher.hpp
| -- Synchronizer.cpp
| -- Synchronizer.hpp
| -- WorkerThread.cpp
| -- WorkerThread.hpp
| -- IndeXpress.sln
| -- README.md\
You must have a 64 bit system
Setup GCC 8.x (Latest MingW-64 release if building on Windows).
Clone the repo $ git clone https://github.com/deepencoding/IndeXpress.git
Change directory $ cd IndeXpress/IndeXpress
Compile all source files using gcc/mingW as
$ g++ IndeXpress.cpp Searcher.cpp Synchronizer.cpp WorkerThread.cpp -o IndeXpress and then
$ ./IndeXpress.exe OR run it just like a prebuilt binary OR just use your favourite IDE for C/C++.
(optional) Install CLion from JetBrains and build & run the project.
This is licensed under GPL v3. All feedback are welcome and you're free to create issues/pull requests on this repository.