
This case study is from Danny Ma's Serious SQL course. We’ve just received a request from the General Manager of Analytics at Health Co requesting assistance with their analysis of the health.user_logs dataset. We’ve been asked to debug their SQL script and use the resulting query outputs to quickly answer a few questions that the GM has requested for a board meeting about their active users.
The data we will be using is from the following health.user_logs table (first 10 rows displayed):
| id | log_date | measure | measure_value | systolic | diastolic |
|---|---|---|---|---|---|
| fa28f948a740320ad56b81a24744c8b81df119fa | 2020-11-15T00:00:00.000Z | weight | 46.03959 | ||
| 1a7366eef15512d8f38133e7ce9778bce5b4a21e | 2020-10-10T00:00:00.000Z | blood_glucose | 97 | 0 | 0 |
| bd7eece38fb4ec71b3282d60080d296c4cf6ad5e | 2020-10-18T00:00:00.000Z | blood_glucose | 120 | 0 | 0 |
| 0f7b13f3f0512e6546b8d2c0d56e564a2408536a | 2020-10-17T00:00:00.000Z | blood_glucose | 232 | 0 | 0 |
| d14df0c8c1a5f172476b2a1b1f53cf23c6992027 | 2020-10-15T00:00:00.000Z | blood_pressure | 140 | 140 | 113 |
| 0f7b13f3f0512e6546b8d2c0d56e564a2408536a | 2020-10-21T00:00:00.000Z | blood_glucose | 166 | 0 | 0 |
| 0f7b13f3f0512e6546b8d2c0d56e564a2408536a | 2020-10-22T00:00:00.000Z | blood_glucose | 142 | 0 | 0 |
| 87be2f14a5550389cb2cba03b3329c54c993f7d2 | 2020-10-12T00:00:00.000Z | weight | 129.060012817 | 0 | 0 |
| 0efe1f378aec122877e5f24f204ea70709b1f5f8 | 2020-10-07T00:00:00.000Z | blood_glucose | 138 | 0 | 0 |
| 054250c692e07a9fa9e62e345231df4b54ff435d | 2020-10-04T00:00:00.000Z | blood_glucose | 210 |
- Buggy Code:
SELECT
COUNT DISTINCT user_id
FROM health.user_logs;
This code isn't working because parentheses are missing after COUNT, and the column user_id does not exist. The correct column is id.
- Debugged Code:
SELECT
COUNT(DISTINCT id) AS row_count
FROM health.user_logs;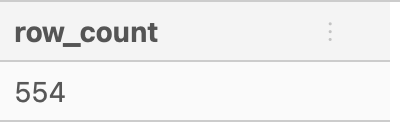
- Buggy Code:
DROP TABLE IF EXISTS user_measure_count;
CREATE TEMP TABLE user_measure_cout
SELECT
id,
COUNT(*) AS measure_count,
COUNT(DISTINCT measure) as unique_measures
FROM health.user_logs
GROUP BY 1; 
There are 2 errors here. There is a spelling mistake in the 2nd line. user_measure_cout should be user_measure_count. Also, we need to use AS before SELECT when creating a temporary table.
- Debugged Code:
DROP TABLE IF EXISTS user_measure_count;
CREATE TEMP TABLE user_measure_count
AS
SELECT
id,
COUNT(*) AS measure_count,
COUNT(DISTINCT measure) as unique_measures
FROM health.user_logs
GROUP BY 1;
--check the output of the temp table:
SELECT * FROM user_measure_count
LIMIT 20;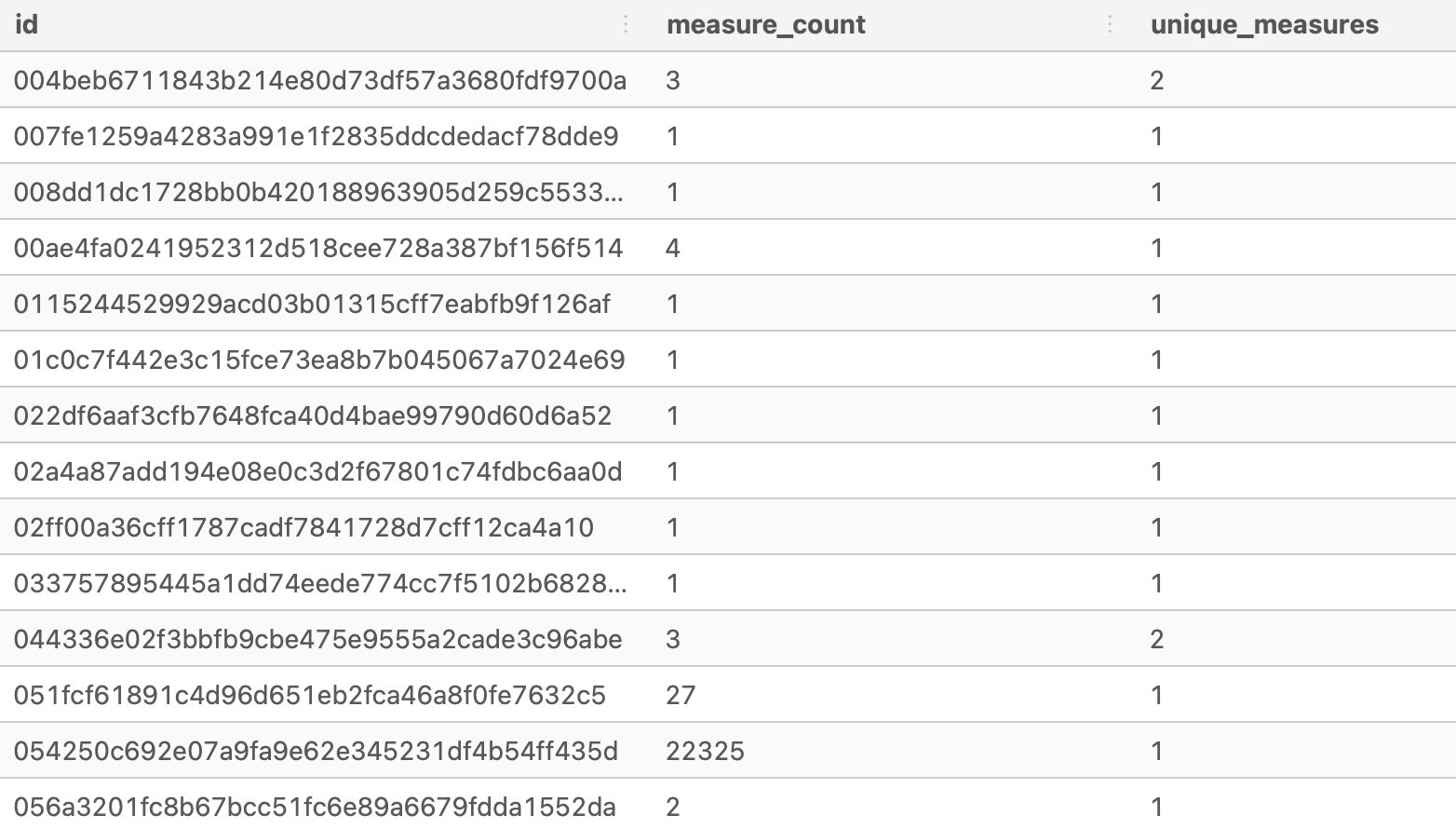
- Buggy Code:
SELECT
ROUND(MEAN(measure_count))
FROM user_measure_count;
The mistake here is that MEAN does not exist as a function in PostgreSQL. We need to use the AVG function to find the mean here. It is not necessary, but I also used avg_measure_count as an alias. Without an alias, the column heading for the average will default to "round," and that can be confusing to anyone interpreting the output.
- Debugged Code:
SELECT
ROUND(AVG(measure_count)) AS avg_measure_count
FROM user_measure_count;
- Buggy Code
SELECT
PERCENTILE_CONTINUOUS(0.5) WITHIN GROUP (ORDER BY id) AS median_value
FROM user_measure_count;
Here, PERCENTILE_CONTINUOUS does not exist as a function in SQL. We need to use PERCENTILE_CONT to find the 50th percentile AKA the median. Also, measure_count should come after ORDER BY, since we are finding the median of the measure counts.
- Debugged Code:
SELECT
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY measure_count) AS median_measure_count
FROM user_measure_count;
- Buggy Code:
SELECT
COUNT(*)
FROM user_measure_count
HAVING measure >= 3;
The column measure does not exist. We need to use measure_count. Also, the HAVING clause needs to be replaced with WHERE since we are filtering records from a table and not from a group.
- Debugged Code:
SELECT
COUNT(*)
FROM user_measure_count
WHERE measure_count >= 3;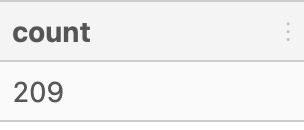
- Buggy Code:
SELECT
SUM(id)
FROM user_measure_count
WHERE measure_count >= 1000;
Here, we need to use COUNT instead of SUM to count the rows. It is ok here to use COUNT(id) or COUNT(*).
- Debugged Code:
SELECT
COUNT(*)
FROM user_measure_count
WHERE measure_count >= 1000;
- Buggy Code:
SELECT
COUNT DISTINCT id
FROM health.user_logs
WHERE measure is 'blood_sugar';
blood_sugar does not exist as one of the measures in our data. The correct measure is blood_glucose. Parentheses are required after COUNT.
- Debugged Code:
SELECT
COUNT(DISTINCT id)
FROM health.user_logs
WHERE measure = 'blood_glucose';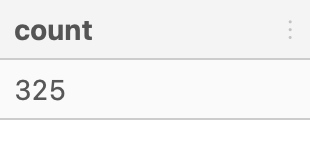
- Buggy Code:
SELECT
COUNT(*)
FROM user_measure_count
WHERE COUNT(DISTINCT measures) >= 2;
measures does not exist as a column heading. There is already a column for unique_measures in our temporary table that we can use.
- Debugged Code:
SELECT
COUNT(*)
FROM user_measure_count
WHERE unique_measures >= 2;
- Buggy Code:
SELECT
COUNT(*)
FROM usr_measure_count
WHERE unique_measures = 3;
This simply has a spelling error. usr_measure_count should be user_measure_count.
- Debugged Code:
SELECT
COUNT(*)
FROM user_measure_count
WHERE unique_measures = 3;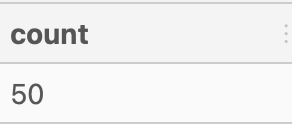
- Buggy Code:
SELECT
PERCENTILE_CONT(0.5) WITHIN (ORDER BY systolic) AS median_systolic
PERCENTILE_CONT(0.5) WITHIN (ORDER BY diastolic) AS median_diastolic
FROM health.user_logs
WHERE measure is blood_pressure;
GROUP needs to be used after WITHIN here, and blood_pressure should be in parentheses. The word "is" should be replaced with =.
- Debugged Code:
SELECT
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY diastolic) AS median_diastolic,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY systolic) AS median_systolic
FROM health.user_logs
WHERE measure = 'blood_pressure';
Excel-to-Mardown Converter (For making tables in Markdown)