🏗️ Install
⛏️ Usage
💡 How it Works
⚡ Inspiration
Follow these steps to get heaptruffle up and running:
-
Clone the Repository:
git clone https://github.com/devanshbatham/heaptruffle
-
Navigate to the Directory:
cd heaptruffle -
Build the Docker Image:
docker build -t heaptruffle . -
Make the script executable and move it to a directory in your PATH:
sudo chmod +x heaptruffle sudo mv heaptruffle /usr/local/bin/heaptruffle
Once done, you can invoke heaptruffle from any location in your terminal.
-
To run heaptruffle on single URL
docker run -it --rm -v "$PWD":/app/data --name heaptruffle-container heaptruffle --url http://example.com -
or, to run it on a file containing URLs.
docker run -it --rm -v "$PWD":/app/data --name heaptruffle-container heaptruffle --list urls.txt -
Save the output to a file (output.txt):
docker run -it --rm -v "$PWD":/app/data --name heaptruffle-container heaptruffle --url http://example.com --output /app/data/output.txt -
Increase concurrency to fetch URLs faster:
docker run -it --rm -v "$PWD":/app/data --name heaptruffle-container heaptruffle --list urls.txt --concurrency 10
-
To run heaptruffle:
heaptruffle --url https://example.com
-
or
heaptruffle --list urls.txt
-
Increase concurrency to fetch URLs faster:
heaptruffle --list urls.txt --concurrency 10
-
Save the output to a file (output.txt):
heaptruffle --url https://example.com --output output.txt
-
Use silent mode to suppress the ASCII banner:
heaptruffle --url https://example.com --silent
| Option | Alias | Type | Description |
|---|---|---|---|
--url |
-u |
string |
URL address |
--list |
-l |
string |
File containing list of URLs |
--concurrency |
-c |
number |
Number of URLs to fetch concurrently (default: 5) |
--silent |
-s |
boolean |
Silent mode, does not display the ASCII banner (default: false) |
--output |
-o |
string |
File to save the output |
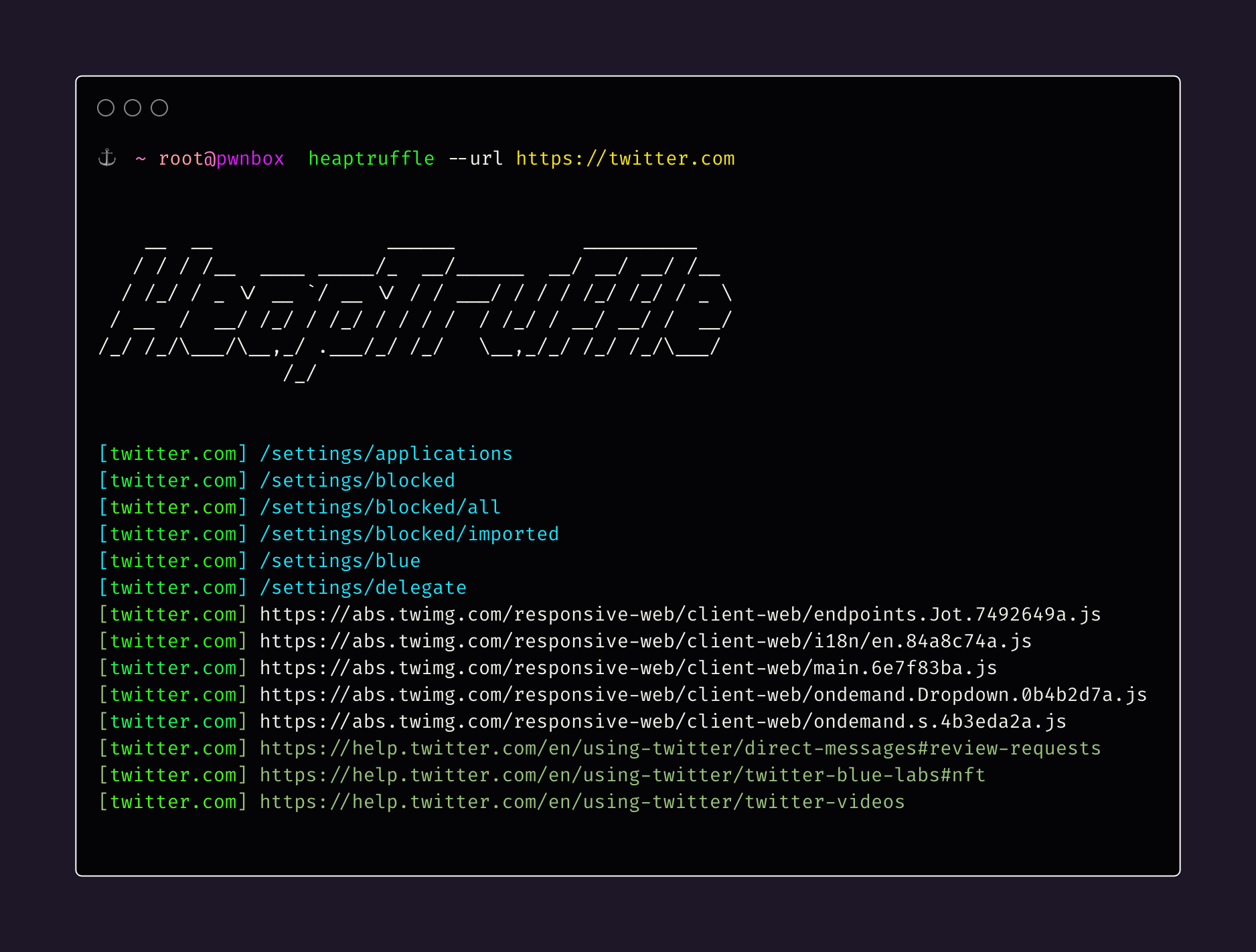
heaptruffle uses Puppeteer, a headless browser automation library, to load web pages and capture heap snapshots of the web pages' memory. These heap snapshots are then parsed using the heapsnapshot-parser library, allowing heaptruffle to extract URLs/endpoints from it.
The tool takes either a single URL or a file containing a list of URLs as input. It fetches each URL concurrently to speed up the process. For each URL, heaptruffle loads the web page, captures a heap snapshot, and then performs analysis to extract relevant paths from the snapshot. It identifies the URLs and paths accessed during the page's execution and outputs them to the console or a specified output file.
This tool was inspired by the project extract-relative-url-heapsnapshot by smiegles. I just improved it in my way and extended its functionality (concurrency, support for multiple URLs, pretty output, the ability to save the results in a file, dockerization, error handling, an easy-to-use setup script, etc).