This repository aims to provide a backbone of high geographic resolution administrative data to support analysis of and the policy response to the COVID-19 pandemic in India.
The current version includes estimates of hospital and clinic doctor and bed capacity (district level, and soon subdistrict), CFR predictions based on variation in local population age distribution (subdistrict level), urbanization rates and population density (subdistrict level and lower), as well as deaths and infections at the highest resolution possible. Crucially, all of these are described with common location identifiers, making it easy to link them together and to external data sources. Data are disaggregated by urban/rural where possible.
We have phone surveys on economic conditions in the field, which we will include here as they arrive. We will also harmonize and include data from as many other teams' surveys as possible, given data availability.
We are updating and adding to this repo as quickly as possible. If you are part of a team working with policymakers or researchers on the COVID-19 response in India and need administrative data not in this repository, please contact us (covid@devdatalab.org) and we will add it to our list if we can obtain it.
This is an effort by Development Data Lab, led by Professors Sam Asher (Johns Hopkins SAIS) and Paul Novosad (Dartmouth College). If you use these data, please reference the source. This helps us continue to provide and develop this service. If you are interested in funding more rapid development of this data platform, please contact us at covid@devdatalab.org.
Please cite these data as the "SHRUG COVID platform", referring to the SHRUG paper:
@unpublished{ almn2020,
author = {Asher, Sam and Lunt, Tobias and Matsuura, Ryu and Novosad, Paul},
note = {World Bank Economic Review (Revise and Resubmit)},
title = {{The Socioeconomic High-resolution Rural-Urban Geographic Dataset on India (SHRUG)}},
year = {2020}
}

Relative paths here refer to paths in the data folder. Most district-level data are available with both PC11 and LGD identifiers. CSV files are
in a csv/ subfolder in each path, while PC11 identified data are in a pc11/ subfolder.
| Folder | Description | Data Files | Metadata |
|---|---|---|---|
| mortality/ | Total deaths by district and state, aggregated by month and year | mortality/district_mort_month, mortality/district_mort_year, mortality/state_mort_month, mortality/state_mort_year |
Link |
| covid/ | Number of confirmed cases and deaths, and cumulative vaccination data by date, district | covid/covid_infected_deaths, covid/covid_vaccination |
Link , Link |
| demography/ | Age pyramid of every district and subdistrict | demography/age_bins_(sub)district_t |
Link |
| (Sub)district level slum populations, pop density, urbanization rates (PC) | demography/pc11_demographics_(sub)district |
Link | |
| estimates/ | Modeled district hospital/clinic bed and doctor counts (EC,PC,DLHS) | estimates/hospitals_dist |
Link |
| Modeled age-structured based fatality rate predictions | estimates/(sub)district_age_dist_cfr |
||
| hospitals/ | District-level public hospital/clinic bed and doctor counts from DLHS | hospitals/dlhs4_hospitals_dist |
Link |
| (Sub)district-level public hospital/clinic bed and doctor counts from Pop Census | hospitals/pc_hospitals_(sub)dist |
Link | |
| District- and town/village-level hospital public/private hospital employment (EC) | hospitals/ec_hospitals_(dist,tv) |
Link | |
| migration/ | District-level temporary and permanent migration data | migration/district_migration |
Link |
| District-level temporary and permanent migration data (PC11 identified) | migration/pc11/district_migration_pc11 |
Link | |
| agmark/ | Farm product data reported by different Mandis (Markets) across India. | agmark/agmark_clean |
Link |
| hmis/ | Data on child immunisations, maternal health, hospitalisations and lab testing among others across all years of available data. | hmis/hmis_dist_clean |
Link |
| nfhs/ | All India Health Centres Directory | nfhs/ddl_health_infra_lgd |
Link |
| National Family Health Survey (NFHS-IV) | nfhs/ddl_nfhs_lgd |
Link | |
| PM 2.5 Air Pollution | nfhs/ddl_pollution_sedac_lgd |
Link | |
| keys/ | Correspondences to link different datasets |
| Data | Description | Geographic level | Scope |
|---|---|---|---|
| Comorbidity rates | Local mortality multipliers based on rates of common conditions known to correlate with Covid-19 morbidity, such as diabetes. Source: NSS | District | |
| Gender composition | Sex ratios in five year age bins | State/District/Subdistrict | |
| Lockdown policies | Government-imposed restrictions/social distancing with details and dates | State/District | |
| Slums | Slum populations, areas, proportions | State/District/Town | |
| Poverty | Small area estimation consumption per capita and poverty rate estimates based on the Socioeconomic and Caste Census | State/District/Subdistrict | |
| Health staff | Number of doctors, nurses, employees of health centers, etc. | State/District/Subdistrict | Total/Urban/Rural |
| Sectoral composition | Share of employment in important sectors of the economy | State/District/Subdistrict |
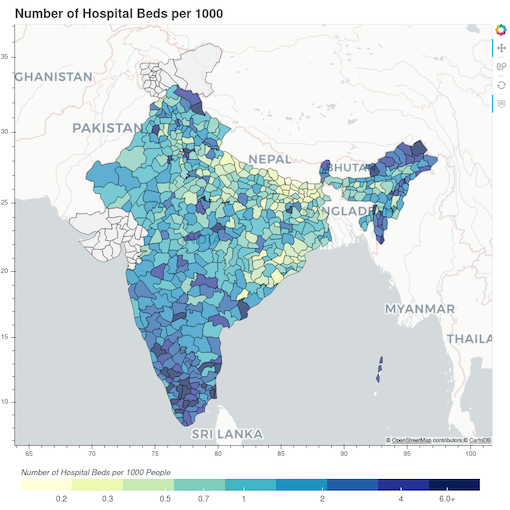 |
|---|
| Hospital Bed Availability by District |
| Directory | Explanation |
|---|---|
| a/ | Analysis file with material used in the current version of the data build. |
| b/ | Build folder. |
| e/ | Explore folder. |
| assets/ | Various web assets, such as images embedded in README.md. |
The root path of the folder only has one code file:
make_covid.do, which runs the full build and the full analysis.
This repository's build refers to locations of code and data using Stata global variables. You will need to set the following globals to run the code:
| Global | Explanation |
|---|---|
$tmp |
A temporary folder for intermediate data and outputs. |
$ccode |
Root folder for this repository. |
$covidpub |
Root data folder for this repo. |
A global can be set in Stata with e.g. global tmp temporary/directory/location.
The full build, including both code and data, is diagrammatically described here.
This repository is structured such that the first half runs on DDL servers to produce datasets that serve as inputs for the COVID-related analytics, like the EC microdata file, the DLHS district-level aggregates, and a shortened VD/TD/PCA. The second half then needs to run on those files to produce the final outputs, like the hospital bed estimates.
You can download the data here:

While we don't have a real API for these data (yet), you can access all files and directories programmatically using curl or wget. To do this, follow the dropbox links and right-click on the file or folder you wish to access, and copy the link location. Use this link location with curl or wget, e.g. curl -L https://www.dropbox.com/sh/y949ncp39towulf/AADbSeZWSG1xjPHXNMTyhmoba/covid?dl=0 > download.zip
If you come across bugs in the data or have a specific data request that we are likely to have, you can email covid@devdatalab.org or email Paul, Sam or Toby directly.
We invite researchers and data asset holders to contribute data to the public good by adding it to this platform. To contribute your data, please get in touch. You can view the format requirements here.
This repo is a collaborative effort led by the Development Data Lab, co-founded by Sam Asher, Toby Lunt, and Paul Novosad. Additional contributors: Aditi Bhowmick, Ali Campion, Radhika Jain, Sam Besse, Kritarth Jha.