NNVM-Fusion is a module which implements GPU kernel fusion and runtime compilation based on NNVM. It can be easily used as a plugin of NNVM in different deep learning systems to gain a boost on performance.
GPU kernel fusion is an optimization method to reduce overhead of data transfer from global memory by fusing some sequential kernels into a single, large one, to improve performance and memory locality.
Fusion will generate the CUDA codes of fused kernel, which requires us to compile it during runtime. In this part, we wrap NVRTC to do this job.
This module is implemented based on the well defined concepts provided by NNVM. So we can implement this module as three passes on the computation graph: {Fusion, CodeGen, RTCGen}.
- Fusion Pass: detects patterns can be fused in computation graph, and generates the ASTs(Abstract Syntax Tree) expressing the code structure.
- CodeGen Pass: uses the ASTs to generate real CUDA codes.
- RTCGen Pass: compiles the CUDA codes to functions can be called during runtime.
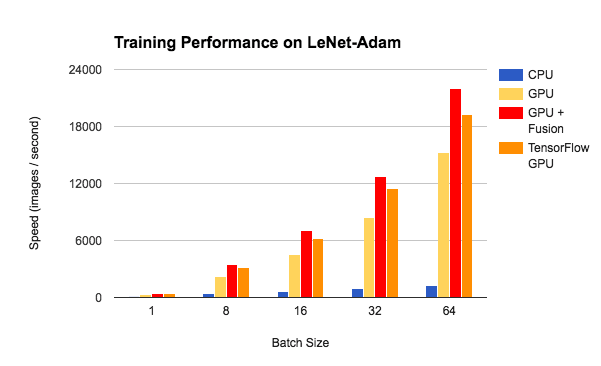
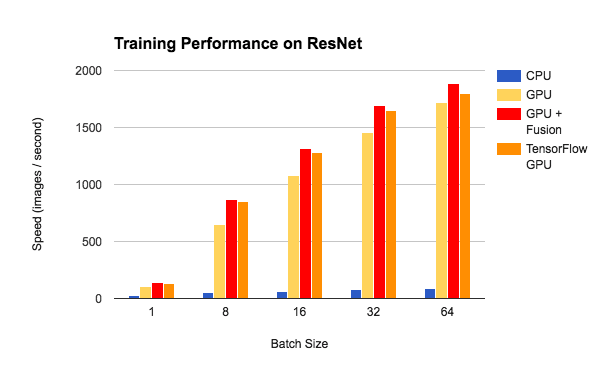
we have done some benchmark tests of the training performance on LeNet and ResNet, based on TinyFlow. We compared the training speed between CPU, GPU and GPU with NNVM-Fusion. It demonstrates that NNVM-Fusion can improve the GPU performance by 1.4x-1.5x on LeNet and 1.1x-1.3x on ResNet with medium batch size. We also compare the training speed with the same model on TensorFlow. With NNVM-Fusion, TinyFlow's performance is on par with TensorFlow on ResNet, and better on LeNet.