[TOC]
每个请求按时间逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
权重越高,在被访问的概率越大。
上述存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。
我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自定定位到该服务器。
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session共享问题
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
按照访问的url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。

JVM自带的类加载器包括启动类加载器、扩展类加载器和应用程序类加载器,此外还可以自定义类加载器。每个类加载器的作用都不一样。
启动类加载器(Bootstrap ClassLoader)
负责加载 JAVA_HOME\lib 目录下的类库,也就是JDK核心类库。
扩展类加载器(Extension ClassLoader)
负责加载 JAVA_HOME\lib\ext 这个子目录下的类库。
应用程序类加载器(Application ClassLoader)
负责加载用户类路径 Classpath 上的类库。
自定义类加载器
通过继承 java.lang.ClassLoader,根据不同的需求来实现自定义的类加载器,可以用来加载用户指定目录下的Class。在实际开发中,通过继承JDK中的类或者实现JDK中的接口来实现自定义类加载器。
这些类加载器在加载某一个类的时候,具体的工作流程是怎样的?这里就要开始介绍重点:双亲委派模型(Parent Delegation Model)。
双亲委派模型包括两个过程,向上委派和向下委派。
双亲委派模型

向上委派
一个类在收到类加载请求后,不会自己马上加载这个类,而是把这个类的加载请求委派给它的父类去完成。父类收到这个请求后又会继续向上委派给父类的父类。以此类推,直到所有的请求委派到Bootstrap ClassLoader。
向下委派
当Bootstrap ClassLoader在接收到类加载请求后,如果发现自己无法加载这个类,比如这个类的Class文件不在加载路径中,那么父类就会向下委派子类加载器来加载这个类,直到这个请求被成功加载。
如果一直到最底层的自定义加载器都没有找到这个类的Class文件,那么JVM就会抛出ClassNotFound异常。
双亲委派模型的主要作用是保证JVM加载类的一致性,尤其是一些JDK中最基础的类。
如果没有使用双亲委派模型,由各个类加载器自行加载的话,如果用户自己编写了一个称为 java.lang.Object 的类,并放在程序的ClassPath中,那系统将会出现多个不同的 Object 类,这样会导致Java类型的混乱。
双亲委派模型可以保证对于 Java.lang.Object 类,无论哪个类加载器要加载它,最终都会委派给Bootstrap ClassLoader,一定会加载 JAVA_HOME/lib 中的 Object 类。
另外双亲委派模型也可避免同一个类被加载多次,防止内存中出现多份同样的字节码。
面试中经常会问到的一个问题:可以不可以自己写个String类?
如果我们定义的完全类名是 java.lang.String, 我们知道基于双亲委派模型,会通过父加载器加载,那么最终到 Bootstrap ClassLoader 加载的就是标准JDK中的 String 类。其他加载器看到 String 类已经被加载,也就不会再重新加载 String 类了。
但是如果我们自定义的 String 类,包名不同的话,是可以重写的,在JVM看来,这其实是两个不同的类。

双亲委派模型就是将类加载器进行分层。在触发类加载的时候,当前类加载器会从低层向上委托父类加载器去加载。每层类加载器在加载时会判断该类是否已经被加载过,如果已经加载过,就不再加载了。这种设计能够避免重复加载类、核心类被篡改等情况发生。
双亲委派模型很好地解决了各个类加载器的基础类的统一问题,越基础的类由越上层的加载器进行加载。Java基础类一般都是被用户代码所调用的,那么是否存在基础类需要调用用户代码的情况呢?
主要场景就是JDK自身只提供接口规范,然后让第三方厂商去提供接口的具体实现,这样就会出现基础类调用厂商代码的情况,比如JDBC驱动类的加载,这类接口统称为服务提供者接口(SPI)。
服务提供者接口(SPI)
我们系统里抽象的各个模块,往往有很多不同的实现方案,比如日志模块、XML解析模块、JDBC模块等。为了实现模块实现的可插拔,在模块装配的时候就需要一种服务发现机制。Java SPI就是一种为某个接口寻找实现的机制。
Java 提供了很多服务提供者接口(SPI:Service Provider Interface),允许第三方为这些接口提供实现。常见的 SPI 包括 JDBC、JCE、JNDI、JAXP 和 JBI 等。
SPI机制允许Java程序在运行时才来加载具体的接口实现类,使用者只需要按照SPI规范指定具体的接口实现即可。通过这种方式,就实现策略模式和热拔插效果。
这些 SPI 接口在Java 核心库中,而实现代码则是在类路径(ClassPath)下的Jar包中。核心库中涉及到SPI接口的代码需要加载接口实现类。
以JDBC为例,它的代码在rt.jar中,由启动类加载器去加载,但它需要调用厂商实现的SPI代码,这些代码部署在ClassPath下面。
根据双亲委派模型,启动类加载器无法直接委派应用程序类加载器(Application ClassLoader)来加载SPI的实现代码。那么启动类加载器如何找到这些代码呢?
JDK引入了线程上下文类加载器(TCCL:Thread Context ClassLoader),线程上下文类加载器破坏了“双亲委派模型”,可以在执行线程中抛弃双亲委派加载链,利用线程上下文类加载器去加载所需要的SPI代码。
TCCL是从JDK1.2开始引入的,可以通过 java.lang.Thread 类中的 getContextClassLoader()和 setContextClassLoader(ClassLoader cl) 方法来获取和设置线程的上下文类加载器。如果没有手动设置上下文类加载器,线程将继承其父线程的上下文类加载器,初始线程的默认上下文类加载器是 Application ClassLoader。

连接Mysql数据库时需要加载Mysql的JDBC驱动 com.mysql.jdbc.Driver。
DriverManager调用 getConnection() 连接数据库时,会触发 ServiceLoader.load(Driver.class)。
load() 函数会通过 Thread.currentThread().getContextClassLoader()获得当前线程的上下文类加载器,完成驱动类加载。

接下来在Classpath的jar包中查找,如存在 META-INF/services/java.sql.Driver 文件,则加载其实现类,比如 mysql-connector-java-5.1.44.jar。从上图的调用链中,可以知道此时使用的类加载器是线程上下文类加载器,这就是SPI机制的核心原理。
Spring框架也用到了线程上下文类加载器(TCCL),来加载WEB-INF下的用户代码,同样也是打破了双亲委派模型的加载链。
binlog 日志有三种格式
- Statement:基于SQL语句的复制((statement-based replication,SBR))
- Row:基于行的复制。(row-based replication,RBR)
- Mixed:混合模式复制。(mixed-based replication,MBR)
Statement格式
每一条会修改数据的 SQL 都会记录在 binlog 中
- 优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。
- 缺点:由于记录的只是执行语句,为了这些语句能在备库上正确运行,还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在备库得到和在主库端执行时候相同的结果。
Row格式
不记录 SQL 语句上下文相关信息,仅保存哪条记录被修改。
- 优点:binlog 中可以不记录执行的 SQL 语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。不会出现某些特定情况下的存储过程、或 function、或trigger的调用和触发无法被正确复制的问题。
- 缺点:可能会产生大量的日志内容。
Mixed格式
实际上就是 Statement 与 Row 的结合。一般的语句修改使用 statment 格式保存 binlog,如一些函数,statement 无法完成主从复制的操作,则采用 row 格式保存 binlog,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式。
cgroups其名称源自控制组群(control groups)的简写,是Linux内核的一个功能,用来限制、控制与分离一个进程组(如CPU、内存、磁盘输入输出等)。
默认情况下,Docker容器是没有资源限制的,它会尽可能地使用宿主机能够分配给它的资源。如果不对容器资源进行限制,容器之间就会相互影响,一些占用硬件资源较高的容器会吞噬掉所有的硬件资源,从而导致其它容器无硬件资源可用,发生停服状态。 Docker提供了限制内存,CPU或磁盘IO的方法, 可以对容器所占用的硬件资源大小以及多少进行限制,我们在使用docker create创建一个容器或者docker run运行一个容器的时候就可以来对此容器的硬件资源做限制。
Docker 通过 cgroup 来控制容器使用的资源配额,包括 CPU、内存、磁盘三大方面,基本覆盖了常见的资源配额和使用量控制。
默认设置下,所有容器可以平等地使用宿主机的CPU资源并且没有限制。
设置CPU资源的选项如下
- 共享式CPU资源
- 限制容器运行的核数
- 限制容器指定的CPU核心数
- c 或 --cpu-shares: 在有多个容器竞争 CPU 时我们可以设置每个容器能使用的 CPU 时间比例。这个比例叫作共享权值。共享式CPU资源,是按比例切分CPU资源;Docker 默认每个容器的权值为 1024。如果不指定或将其设置为0,都将使用默认值。 比如,当前系统上一共运行了两个容器,第一个容器上权重是1024,第二个容器权重是512, 第二个容器启动之后没有运行任何进程,自己身上的512都没有用完,而第一台容器的进程有很多,这个时候它完全可以占用容器二的CPU空闲资源,这就是共享式CPU资源;如果容器二也跑了进程,那么就会把自己的512给要回来,按照正常权重1024:512划分,为自己的进程提供CPU资源。如果容器二不用CPU资源,那容器一就能够把容器二的CPU资源所占用,如果容器二也需要CPU资源,那么就按照比例划分。那么第一个容器会从原来使用整个宿主机的CPU变为使用整个宿主机的CPU的2/3;这就是CPU共享式,也证明了CPU为可压缩性资源。
- --cpus: 限制容器运行的核数;从docker1.13版本之后,docker提供了--cpus参数可以限定容器能使用的CPU核数。这个功能可以让我们更精确地设置容器CPU使用量,是一种更容易理解也常用的手段。
- --cpuset-cpus: 限制容器运行在指定的CPU核心; 运行容器运行在哪个CPU核心上,例如主机有4个CPU核心,CPU核心标识为0-3,我启动一台容器,只想让这台容器运行在标识0和3的两个CPU核心上,可以使用cpuset来指定。
与内存限额不同,通过-c设置的cpu share 并不是CPU资源的绝对数量,而是一个相对的权重值。某个容器最终能分配到的CPU资源取决于它的cpu share占所有容器cpu share总和的比例。换句话说,通过cpu share可以设置容器使用CPU的优先级。
# containerA的cpu share 1024, 是containerB 的两倍。
# 当两个容器都需要CPU资源时,containerA可以得到的CPU是containerB 的两倍。
# 需要特别注意的是,这种按权重分配CPU只会发生在CPU资源紧张的情况下。
# 如果containerA处于空闲状态,这时,为了充分利用CPU资源,containerB 也可以分配到全部可用的CPU。
docker run --name "cont_A" -c 1024 ubuntu docker run --name "cont_B" -c 512 ubuntu
# 容器最多可以使用主机上两个CPU ,除此之外,还可以指定如 1.5 之类的小数。
docker run -it --rm --cpus=2 centos /bin/bash
# 表示容器中的进程可以在 CPU-1 和 CPU-3 上执行。
docker run -it --cpuset-cpus="1,3" ubuntu:14.04 /bin/bash
# 表示容器中的进程可以在 CPU-0、CPU-1 及 CPU-2 上执行。
docker run -it --cpuset-cpus="0-2" ubuntu:14.04 /bin/bash
通过-c 或 --cpu-shares是对CPU的资源进行相对限制。同样,我们可以进行CPU资源的绝对限制。
Linux 通过 CFS(Completely Fair Scheduler,完全公平调度器)来调度各个进程对 CPU 的使用。CFS 默认的调度周期是 100ms。
我们可以设置每个容器进程的调度周期,以及在这个周期内各个容器最多能使用多少 CPU 时间。
- --cpu-period 设置每个容器进程的调度周期
- --cpu-quota 设置在每个周期内容器能使用的 CPU 时间
例如:
docker run -it --cpu-period=50000 --cpu-quota=25000 Centos centos /bin/bash
表示将 CFS 调度的周期设为 50000,将容器在每个周期内的 CPU 配额设置为 25000,表示该容器每 50ms 可以得到 50% 的 CPU 运行时间。
docker run -it --cpu-period=10000 --cpu-quota=20000 Centos centos /bin/bash 表示将容器的 CPU 配额设置为 CFS 周期的两倍,CPU 使用时间怎么会比周期大呢?其实很好解释,给容器分配两个 CPU 就可以了。该配置表示容器可以在每个周期内使用两个 CPU 的 100% 时间。
CFS 周期的有效范围是 1ms~1s,对应的--cpu-period的数值范围是 1000~1000000。
而容器的 CPU 配额必须不小于 1ms,即--cpu-quota的值必须 >= 1000。可以看出这两个选项的单位都是 us。
--cpu-quota 设置容器在一个调度周期内能使用的 CPU 时间时实际上设置的是一个上限。 并不是说容器一定会使用这么长的 CPU 时间。
启动一个容器,将其绑定到 cpu 1 上执行,给其 --cpu-quota 和 --cpu-period 都设置为 50000。表示每个容器进程的调度周期为 50000,容器在每个周期内最多能使用 50000 CPU 时间。
docker run -d --name mongo1 --cpuset-cpus 1 --cpu-quota=50000 --cpu-period=50000 docker.io/mongo
再docker stats mongo-1 mongo-2可以观察到这两个容器,每个容器对 cpu 的使用率在 50% 左右。说明容器并没有在每个周期内使用 50000 的 cpu 时间。
使用docker stop mongo2命令结束第二个容器,再加一个参数-c 2048 启动它:
docker run -d --name mongo2 --cpuset-cpus 1 --cpu-quota=50000 --cpu-period=50000 -c 2048 docker.io/mongo
再用docker stats mongo-1 mongo-2命令可以观察到第一个容器的 CPU 使用率在 33% 左右,第二个容器的 CPU 使用率在 66% 左右。因为第二个容器的共享值是 2048,第一个容器的默认共享值是 1024,所以第二个容器在每个周期内能使用的 CPU 时间是第一个容器的两倍。
- CPU份额控制:-c或--cpu-shares
- CPU核控制:--cpuset-cpus、--cpus
- CPU周期控制:--cpu-period、--cpu-quota
与操作系统类似,容器可以使用的内存包括两部分:物理内存和Swap。
Docker通过下面两组参数来控制容器内存的使用量。
- -m 或 --memory:设置内存的使用限额,例如:100MB,2GB。
- --memory-swap:设置内存+swap的使用限额。
默认情况下,上面两组参数为-1,即对容器内存和swap的使用没有限制。如果在启动容器时,只指定-m而不指定--memory-swap, 那么--memory-swap默认为-m的两倍。
# 允许该容器最多使用200MB的内存和100MB 的swap。
docker run -m 200M --memory-swap=300M ubuntu
# 容器最多使用200M的内存和200M的Swap
docker run -it -m 200M ubuntu
Block IO 是另一种可以限制容器使用的资源。Block IO 指的是磁盘的读写,docker 可通过设置权重、限制 bps 和 iops 的方式控制容器读写磁盘的带宽
注:目前 Block IO 限额只对 direct IO(不使用文件缓存)有效。
默认情况下,所有容器能平等地读写磁盘,可以通过设置 --blkio-weight 参数来改变容器 block IO 的优先级。 --blkio-weight 与 --cpu-shares 类似,设置的是相对权重值,默认为 500。在下面的例子中,container_A 读写磁盘的带宽是 container_B 的两倍。
docker run -it --name container_A --blkio-weight 600 ubuntu
docker run -it --name container_B --blkio-weight 300 ubuntu
bps 是 byte per second,表示每秒读写的数据量。
iops 是 io per second,表示每秒的输入输出量(或读写次数)。
可通过以下参数控制容器的 bps 和 iops:
- --device-read-bps,限制读某个设备的 bps。
- --device-write-bps,限制写某个设备的 bps。
- --device-read-iops,限制读某个设备的 iops。
- --device-write-iops,限制写某个设备的 iops。
限制容器写 /dev/sda 的速率为 30 MB/s。
docker run -it --device-write-bps /dev/sda:30MB centos:latest
通过 dd 测试在容器中写磁盘的速度。因为容器的文件系统是在宿主机的 /dev/sda 上的,在容器中写文件相当于对宿主机 /dev/sda 进行写操作。另外,oflag=direct 指定用 direct IO 方式写文件,这样 --device-write-bps 才能生效。
time dd if=/dev/zero of=test.out bs=1M count800 oflag=direct
参数说明如下:
- if=file:输入文件名,缺省为标准输入
- of=file:输出文件名,缺省为标准输出
- ibs=bytes:一次读入 bytes 个字节(即一个块大小为 bytes 个字节)
- obs=bytes:一次写 bytes 个字节(即一个块大小为 bytes 个字节)
- bs=bytes:同时设置读写块的大小为 bytes ,可代替 ibs 和 obs
- count=
blocks:仅拷贝blocks个块,每个块大小等于 ibs 指定的字节数
Docker中针对GPU资源与CPU、内存和磁盘IO资源不同。如果Docker要使用GPU,需要docker支持GPU,在docker19以前都需要单独下载nvidia-docker1或nvidia-docker2来启动容器,但是docker19中后需要GPU的Docker只需要加个参数-–gpus即可(-–gpus all表示使用所有的gpu;要使用2个gpu:–-gpus 2即可;也可直接指定使用哪几个卡:--gpus '"device=1,2"'),Docker里面想读取nvidia显卡再也不需要额外的安装nvidia-docker了。
docker run --help | grep -i gpus
运行nvidia官网提供的镜像,并输入nvidia-smi命令,查看nvidia界面是否能够启动。
docker run --gpus all nvidia/cuda:9.0-base nvidia-smi
# 使用所有GPU
docker run --gpus all nvidia/cuda:9.0-base nvidia-smi
# 使用两个GPU
docker run --gpus 2 nvidia/cuda:9.0-base nvidia-smi
# 指定GPU运行
docker run --gpus '"device=2"' nvidia/cuda:9.0-base nvidia-smi
docker run --gpus '"device=1,2"' nvidia/cuda:9.0-base nvidia-smi
docker run --gpus '"device=UUID-ABCDEF,1"' nvidia/cuda:9.0-base nvidia-smi
1、第一次握手:客户端给服务器发送一个 SYN 报文。
2、第二次握手:服务器收到 SYN 报文之后,会应答一个 SYN+ACK 报文。
3、第三次握手:客户端收到 SYN+ACK 报文之后,会回应一个 ACK 报文。
4、服务器收到 ACK 报文之后,三次握手建立完成。
作用是为了确认双方的接收与发送能力是否正常。
这里我顺便解释一下为啥只有三次握手才能确认双方的接受与发送能力是否正常,而两次却不可以:
第一次握手:客户端发送网络包,服务端收到了。这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。 第二次握手:服务端发包,客户端收到了。这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。不过此时服务器并不能确认客户端的接收能力是否正常。 第三次握手:客户端发包,服务端收到了。这样服务端就能得出结论:客户端的接收、发送能力正常,服务器自己的发送、接收能力也正常。
因此,需要三次握手才能确认双方的接收与发送能力是否正常。
这样回答其实也是可以的,但我觉得,这个过程的我们应该要描述的更详细一点,因为三次握手的过程中,双方是由很多状态的改变的,而这些状态,也是面试官可能会问的点。所以我觉得在回答三次握手的时候,我们应该要描述的详细一点,而且描述的详细一点意味着可以扯久一点。加分的描述我觉得应该是这样:
刚开始客户端处于 closed 的状态,服务端处于 listen 状态。然后 1、第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c)。此时客户端处于 SYN_Send 状态。
2、第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s),同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_REVD 的状态。
3、第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 establised 状态。
4、服务器收到 ACK 报文之后,也处于 establised 状态,此时,双方以建立起了链接。
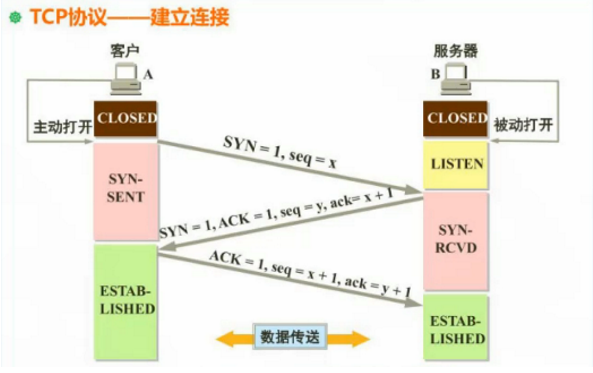
Ps:(1)SYN=1 表示该报文不携带数据,但消耗一个序号 seq=x,seq=x是客户端的初始化序列号,因为tcp是面向字节流的 (2)SYN=1 表示该报文不携带数据,但消耗一个序号 seq=y,seq=y是服务器的初始化序列号,ACK=1是一个确认号 ack=x+1,表示服务器下次接收到的序号希望是x+1。然后服务器进入到SYN-RCVD等待的状态 (3)ACK=1是一个确认号,seq=x+1是上一次服务器回应的序号要求,ack=y+1表示客户下一次接收到的序号希望是y+1
三次握手的作用
三次握手的作用也是有好多的,多记住几个,保证不亏。例如: 1、确认双方的接受能力、发送能力是否正常。 2、指定自己的初始化序列号,为后面的可靠传送做准备。 3、如果是 https 协议的话,三次握手这个过程,还会进行数字证书的验证以及加密密钥的生成到。
单单这样还不足以应付三次握手,面试官可能还会问一些其他的问题,例如: 1、(ISN)是固定的吗?
三次握手的一个重要功能是客户端和服务端交换ISN(Initial Sequence Number), 以便让对方知道接下来接收数据的时候如何按序列号组装数据。
如果ISN是固定的,攻击者很容易猜出后续的确认号,因此 ISN 是动态生成的。 2、什么是半连接队列
服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
这里在补充一点关于SYN-ACK 重传次数的问题: 服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传,如果重传次数超 过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s, 2s, 4s, 8s, …
3、三次握手过程中可以携带数据吗
很多人可能会认为三次握手都不能携带数据,其实第三次握手的时候,是可以携带数据的。也就是说,第一次、第二次握手不可以携带数据,而第三次握手是可以携带数据的。
为什么这样呢?大家可以想一个问题,假如第一次握手可以携带数据的话,如果有人要恶意攻击服务器,那他每次都在第一次握手中的 SYN 报文中放入大量的数据,因为攻击者根本就不理服务器的接收、发送能力是否正常,然后疯狂着重复发 SYN 报文的话,这会让服务器花费很多时间、内存空间来接收这些报文。也就是说,第一次握手可以放数据的话,其中一个简单的原因就是会让服务器更加容易受到攻击了。 而对于第三次的话,此时客户端已经处于 established 状态,也就是说,对于客户端来说,他已经建立起连接了,并且也已经知道服务器的接收、发送能力是正常的了,所以能携带数据页没啥毛病。
为什么要进行三次握手?
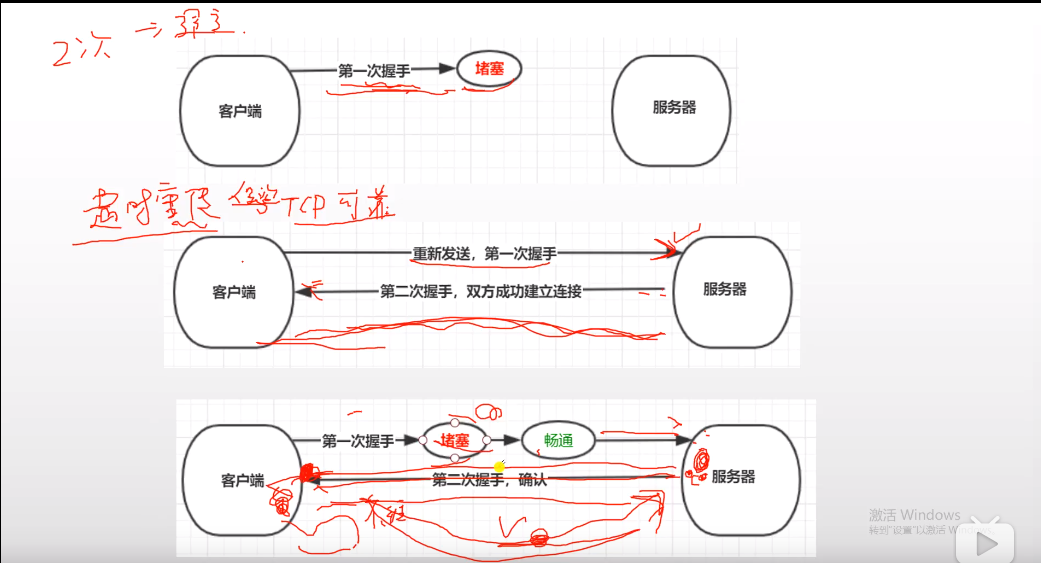
当进行第一次握手,网络不好可能会堵塞,所以连接的请求并没有到达服务器端; 但是tcp连接有超时重传的机制,所以再一次发送请求,这时候服务器端接收到了你的请求,他也会返回一个请求给你,这是第二次握手; 但是这时候网络环境突然又好了起来,那个堵塞的请求到达了服务器端,服务器端又给你回了一个请求,但是你又不想给服务器发送请求,这时候服务器的资源会进行占用等待你的请求,为了不使服务器的资源继续占用,你又必须发送一个请求给服务器; 所以要进行3次握手
1、第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于FIN_WAIT1状态。
2、第二次握手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 + 1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态。
3、第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
4、第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 + 1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态
5、服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
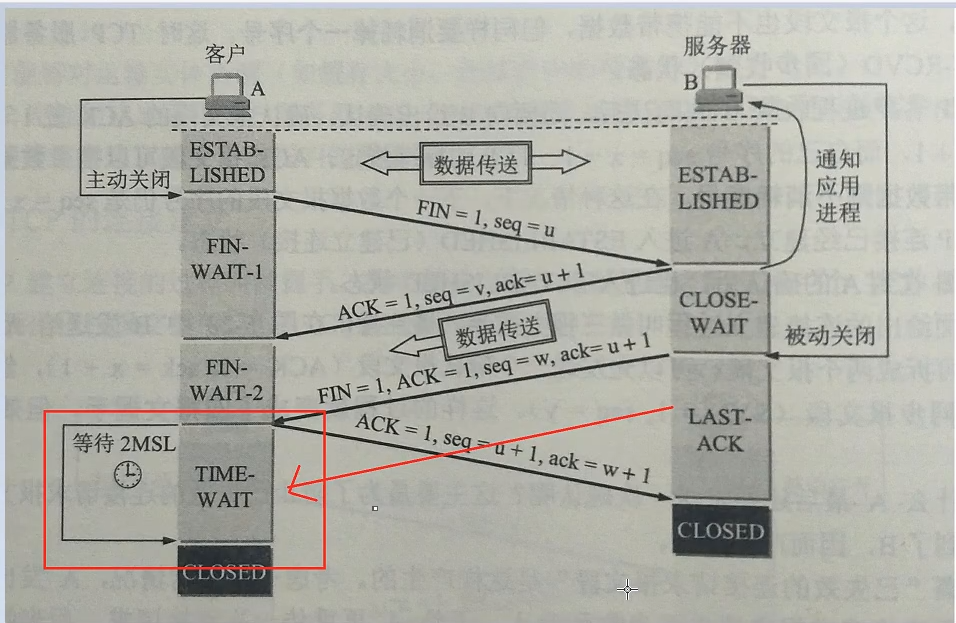
这里特别需要主要的就是TIME_WAIT这个状态了,这个是面试的高频考点,就是要理解,为什么客户端发送 ACK 之后不直接关闭,而是要等一阵子才关闭。这其中的原因就是,要确保服务器是否已经收到了我们的 ACK 报文,如果没有收到的话,服务器会重新发 FIN 报文给客户端,客户端再次收到 ACK 报文之后,就知道之前的 ACK 报文丢失了,然后再次发送 ACK 报文。 至于 TIME_WAIT 持续的时间至少是一个报文的来回时间。一般会设置一个计时,如果过了这个计时没有再次收到 FIN 报文,则代表对方成功就是 ACK 报文,此时处于 CLOSED 状态。
-
懒汉
-
饿汉
-
双重校验锁
-
sync.Once实现
GridFS用于存储和恢复超过16M(bson文件格式)的文件(图片,音频,视频)
GridFS也是文件存储的一种格式,他存储在MongoDB的集合中
GridFS主要用于存储大于超过16M的文件,因为普通doc只能存储16M大小文件
GridFS会将大文件对象分割多个小的chunk文件片段一般为256个,每个chunk作为MongoDB的一个文档被存储在chunk集合中。
GridFS用两个集合来存储一个文件,fs.files与fs.chunks
从jdk1.2版本开发,对象的引用被划分四种级别,从而使程序能更加灵活的控制对象的生命周期。这四种级别由高到底依次为:强引用、软引用、弱引用、虚引用。
强引用是最普遍的引用。如果一个对象具有强引用,垃圾回收器绝对不会回收他
当内存空间不足时,宁愿抛出oom错误,使程序异常终止,也不会随意回收具有强引用的对象来解决内存不足时的问题,如果强对象不使用时,需要弱化从而使gc能够回收
如果一个对象只具有软引用,则内存空间充足时,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用。如果软引用所引用对象被垃圾回收,JAVA虚拟机就会把这个软引用加入到与之关联的引用队列中
当内存不足时,JVM首先将软引用中的对象引用置为null,然后通知垃圾回收器进行回收:
if(JVM内存不足) {
// 将软引用中的对象引用置为null
str = null;
// 通知垃圾回收器进行回收
System.gc();
}
也就是说,垃圾收集线程会在虚拟机抛出OutOfMemoryError之前回收软引用对象,而且虚拟机会尽可能优先回收长时间闲置不用的软引用对象。对那些刚构建的或刚使用过的**"较新的"软对象会被虚拟机尽可能保留**,这就是引入引用队列ReferenceQueue的原因。
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
虚引用顾名思义,就是形同虚设。与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
应用场景:
虚引用主要用来跟踪对象被垃圾回收器回收的活动。 虚引用与软引用和弱引用的一个区别在于:
虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
思维导图

基础
AbstractQueuedSynchronizer抽象同步队列简称A Q S,它是实现同步器的基础组件,如常用的ReentrantLock、Semaphore、CountDownLatch等。
A Q S定义了一套多线程访问共享资源的同步模板,解决了实现同步器时涉及的大量细节问题,能够极大地减少实现工作
AQS分为三部分组成,state同步状态、Node组成的CLH队列、ConditionObject条件变量(包含Node组成的条件单向队列)。
状态
getState():返回同步状态setState(int newState):设置同步状态compareAndSetState(int expect, int update):使用C A S设置同步状态isHeldExclusively():当前线程是否持有资源
独占资源(不响应线程中断)
tryAcquire(int arg):独占式获取资源,子类实现acquire(int arg):独占式获取资源模板tryRelease(int arg):独占式释放资源,子类实现release(int arg):独占式释放资源模板
共享资源(不响应线程中断)
tryAcquireShared(int arg):共享式获取资源,返回值大于等于0则表示获取成功,否则获取失败,子类实现acquireShared(int arg):共享式获取资源模板tryReleaseShared(int arg):共享式释放资源,子类实现releaseShared(int arg):共享式释放资源模板
在A Q S中维护了一个同步状态变量state,getState函数获取同步状态,setState、compareAndSetState函数修改同步状态,对于A Q S来说,线程同步的关键是对state的操作,可以说获取、释放资源是否成功都是由state决定的,比如state>0代表可获取资源,否则无法获取,所以state的具体语义由实现者去定义,现有的ReentrantLock、ReentrantReadWriteLock、Semaphore、CountDownLatch定义的state语义都不一样。
- ReentrantLock的state用来表示是否有锁资源
- ReentrantReadWriteLock的state高16位代表读锁状态,低16位代表写锁状态
- Semaphore的state用来表示可用信号的个数
- CountDownLatch的state用来表示计数器的值
CLH是A Q S内部维护的FIFO(先进先出)双端双向队列(方便尾部节点插入),基于链表数据结构,当一个线程竞争资源失败,就会将等待资源的线程封装成一个Node节点,通过C A S原子操作插入队列尾部,最终不同的Node节点连接组成了一个CLH队列,所以说A Q S通过CLH队列管理竞争资源的线程,个人总结CLH队列具有如下几个优点:
- 先进先出保证了公平性
- 非阻塞的队列,通过自旋锁和
C A S保证节点插入和移除的原子性,实现无锁快速插入 - 采用了自旋锁思想,所以
CLH也是一种基于链表的可扩展、高性能、公平的自旋锁
Object的wait、notify函数是配合Synchronized锁实现线程间同步协作的功能,A Q S的ConditionObject条件变量也提供这样的功能,通过ConditionObject的await和signal两类函数完成。
不同于Synchronized锁,一个A Q S可以对应多个条件变量,而Synchronized只有一个。