The dataset contains tweets about vaccines that are labeled 0 for neutral, 1 for anti-vax or 2 for pro-vax. In this repository I have developed vaccine sentiment classifiers using different models.
I used the scikit-learn LogisticRegression function with multi class = ’multinomial’.
- Preprocessing: None, Lematizing, Stemming
- Feature Extraction with vectorizers: Bag Of Words, TF-IDF, Hashing Vectorizer
- LogisticRegression: I tried to various values for some hyperparameters by hand and I found that probably the best parameters are solver=saga, C=1.0 and l2 or l1 for penalty. A grid search confirmed that.
I used pytorch nn.Module. I experimented with:
- Different optimizers (SGD with momentum and nesterov, Adam (with amsgrad) and their learning rate
- Loss Function: CrossEntropyLoss
- Activation Functions: ReLU, ELU, SELU, tanh, LeakyReLU
- Batch Normalization
- Dropout
- Batch size
- Feature Extraction: TF-IDF, GloVe
I experimented with various parameters and ways of preprocessing.
- Sequence lentgh: The RNNs take input in the form of [batch_size, sequence_length, input_size]. My first approach was to set a default sequence length and truncate or pad sequences to match that length. The second approach, which I tried aiming to get better scores was to create batches with variable sequnce length using BucketIterator. BucketIterator groups texts based on legth so that it minimizes padding.
- Skip Connections: I implemented in a seperate class (for each sequence leght approach) RNN with skip connections based on the following structure.
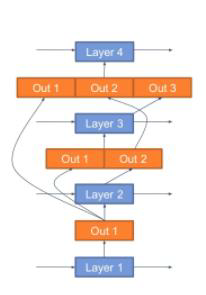
For Hyperparameter Tuning I experimented with the following parameters:
- Learning rate
- Gradient Clipping
- Number of stacked RNNs
- Hidden size
- Batch size
- Dropout
- Epochs
- Skip Connections
- LSTM vs GRU cells
- Attention Mechanism
I used the pretrained BERT-base-uncased and fine tuned it for our classification problem. For hyperparameter tuning I tried mainly the ones that are suggested in BERT paper:
- Batch size:16, 32
- Learning Rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 2, 3, 4 I found that for batch size 16, learning rate 2e-5 and 3 epochs I got the best results.
Some results:

