Reformat csv reading and plot the number of instances being used throughout the hypothesis validation process #84
Assignees

Labels
Milestone
Comments
dpuenteramirez
added a commit
that referenced
this issue
Jan 26, 2022
Due to some modifications to the csv output #84 is being renamed
dpuenteramirez
added a commit
that referenced
this issue
Jan 27, 2022
|
The desired result has been achieved |

|
I am not sure about the names... I think we should have:
|
|
You mean on the right legend, is that correct? |
|
Something like this @alvarag? |

|
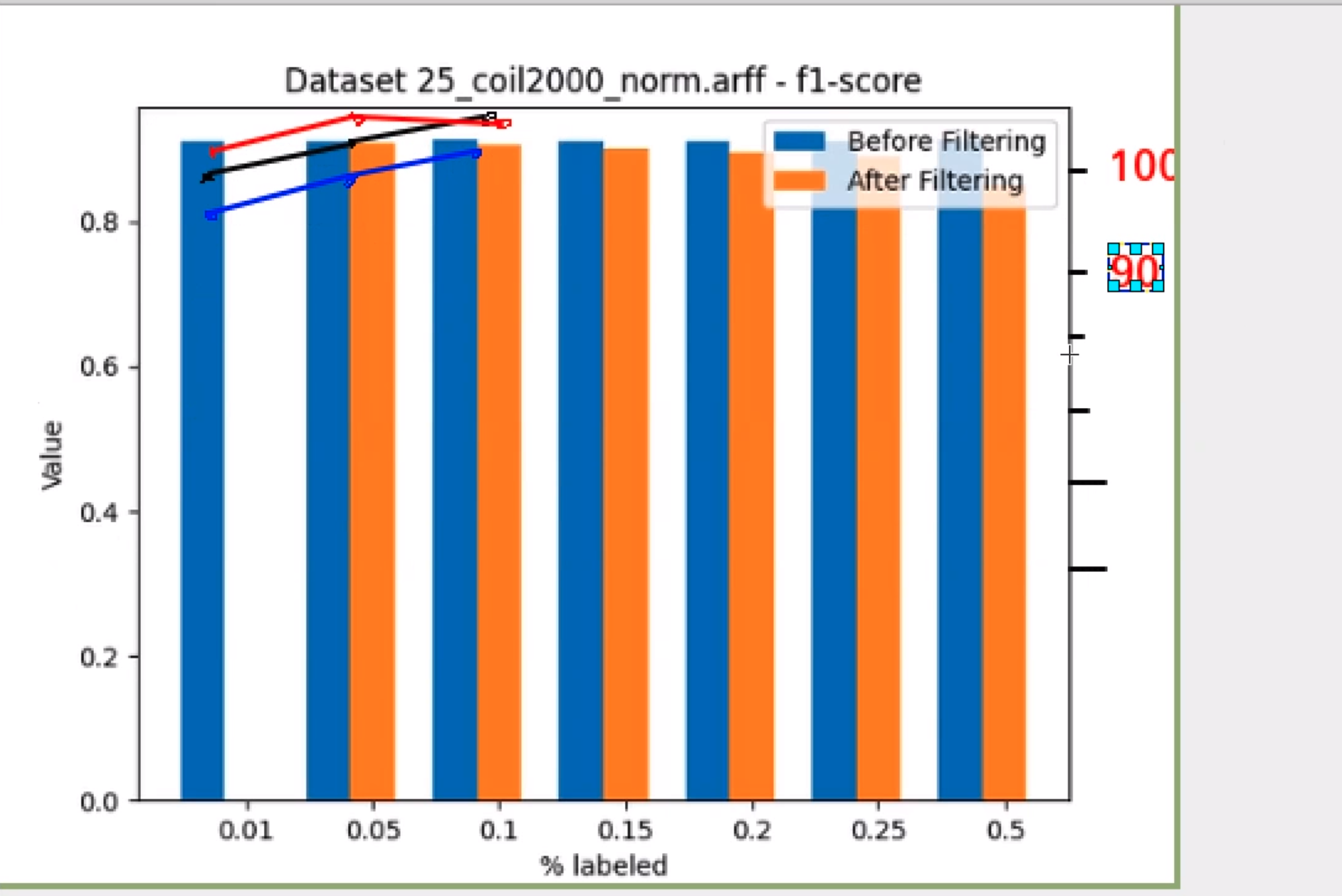
Yes, that is what I wanted to see. The problem is that ENN is fitlering instances of the original dataset, thus it is worsening the performance |
|
Yeah, I knwon, in the following picture you can see the same experiment without deletion of the originl dataset instances. Thus the performance improves quite a bit |

|
Nevertheless, both the "Banana" and the "Iris" datasets have been used as tests to check that all the code worked correctly. I am currently running the experimentation on all the datasets we have in order to have a wider range of results. |
dpuenteramirez
added a commit
that referenced
this issue
Jan 27, 2022
dpuenteramirez
added a commit
that referenced
this issue
Jan 27, 2022
Refactored legend names for clarification #84
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
The basic idea is to add a new metric on the right of the current plot. A handmade of the desired result is the following.
The text was updated successfully, but these errors were encountered: