Difference problem between Local explainability and Global explainability #371
Comments
|
Hello @yaoching0 , Are you using embeddings for categorical features on your model? |
|
@eduardocarvp No, all numerical data between (0,1) |
|
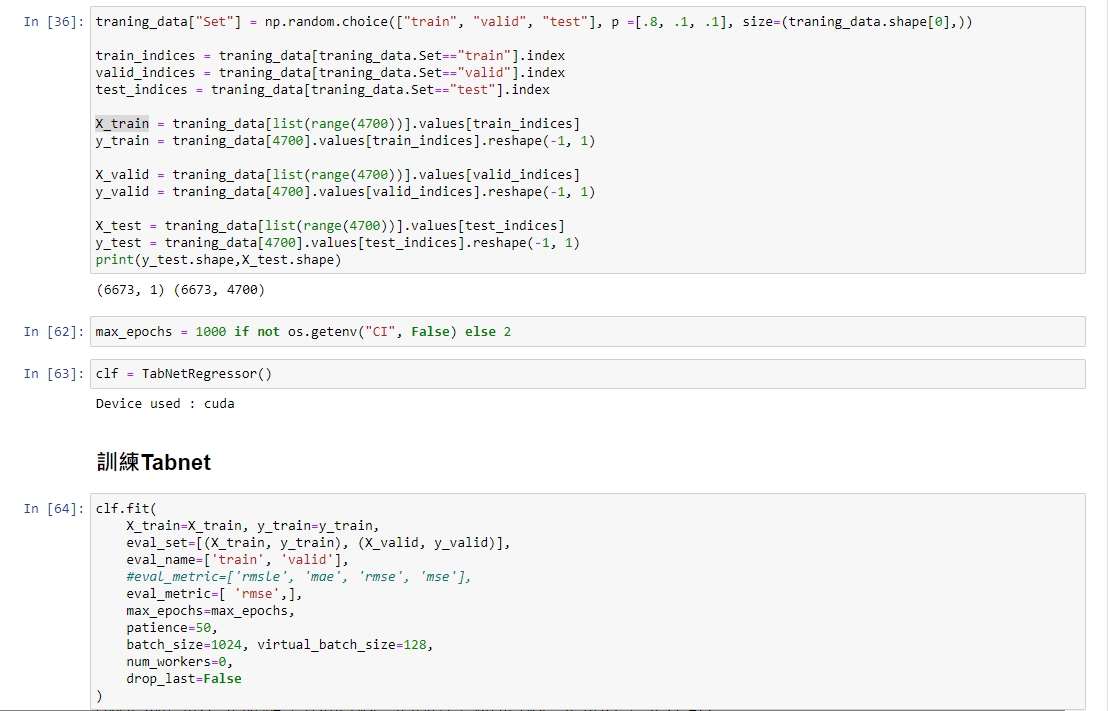
My data format is processed and trained exactly by example. |
|
This is my training data format |

|
The So you need to divide by the sum of each row. Moreover, you want to average no sum |
This comment was marked as outdated.
This comment was marked as outdated.
This comment was marked as outdated.
This comment was marked as outdated.
|
@Optimox |
|
I restart the jupyter kernel,and it seems match |
|
Actually I'm surprised that things are working now for you. I did a test and I was not able to find exactly the So if you have any parameters that changes the train dataloader you'll end up with a different score. This can happen in different scenarios:
I think those are the only two reasons, but there might be a few other scenarios that I did not spotted. In the end: this is a bug, I'll fix it, thank you very much for finding it. In the meantime, the differences are coming from the sample used for internal feature importance. So you can trust both methods: if you see a big change in your case, this is due to the high sparsity of your data, and the final training importance might not be very representative. |
|
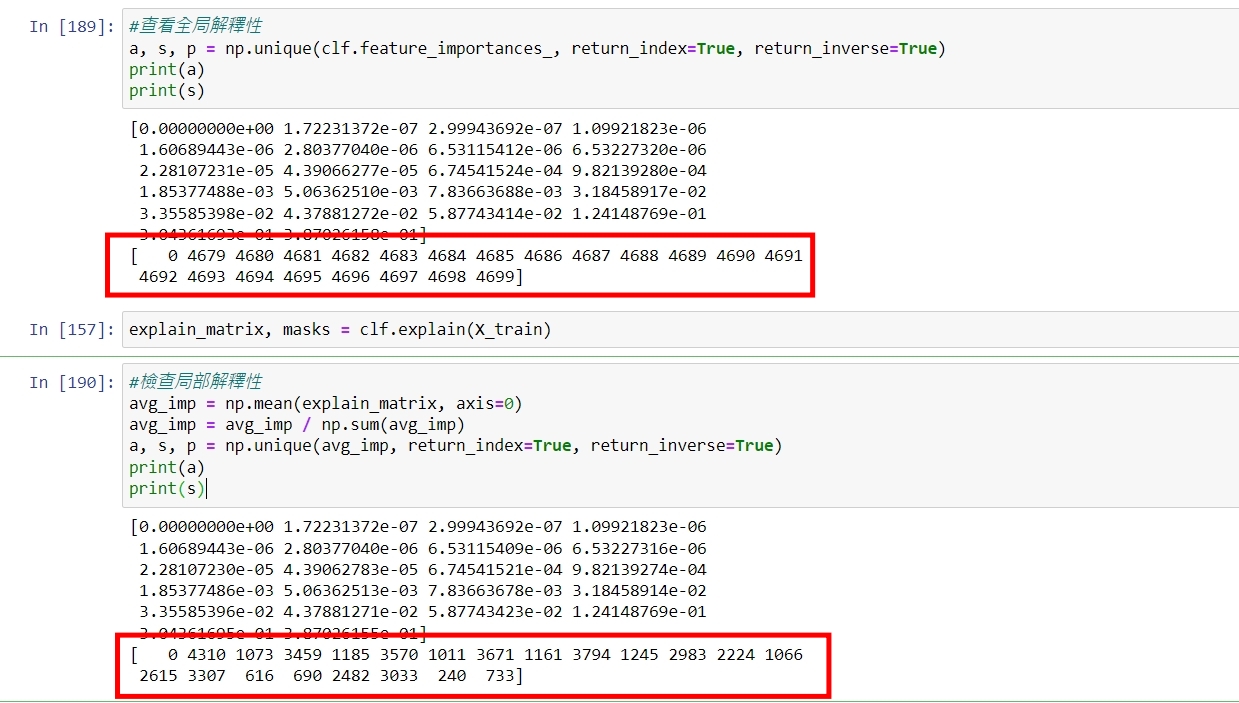
Yes, I think there are some problems as well. I was wondering if the reducing matrix has any influence, since in one case we do the sum first and then reduction and the inverse in the other case. But since there are no np.abs and only sums and averages I guess it should be the same... |
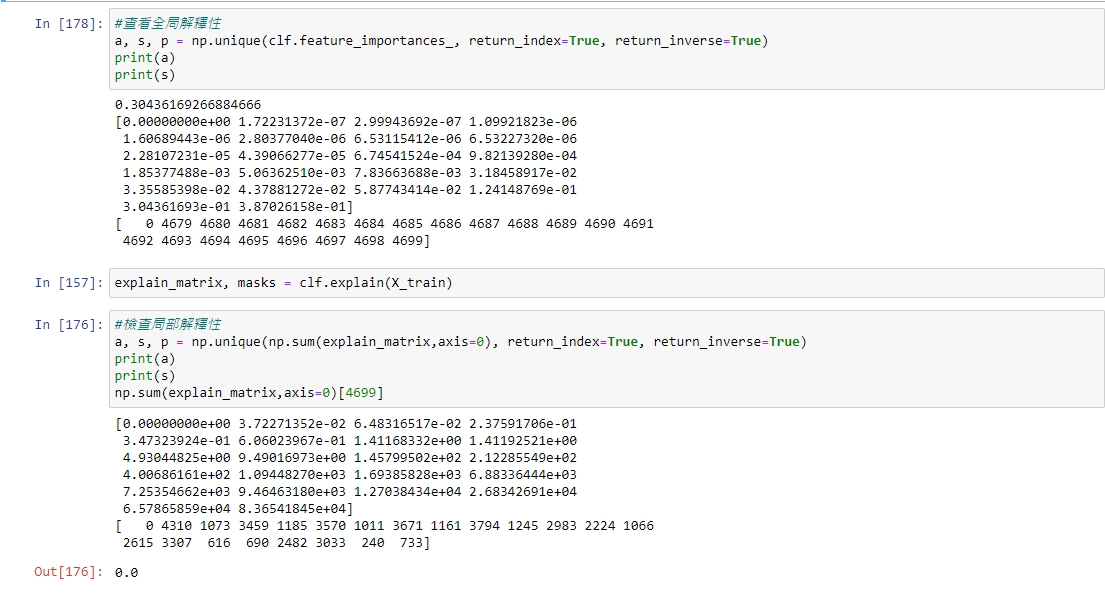
HI,

I train tabnet with 4700-dimension feature,and i check the Global explainability.(Because of its sparseness, I did unique(),the s shows the index in the Global explainability matrix )
and i input training data to the function .explain(Training data), i sum explain_matrix cross the rows, but i get totally different result with Global explainability.
For example,the index of the globally explained maximum value is even 0 in the output of explain() function
The text was updated successfully, but these errors were encountered: