Issue #1138 Replacement of sliding time window. #1139
Conversation
With benchmark results. Code cleanup and refactoring required. Concurrency tests required.
| newTick = getTick(); | ||
| boolean longOverflow = newTick < lastTick; | ||
| if (longOverflow) { | ||
| measurements.clear(); |
There was a problem hiding this comment.
Previous implementation was able to handle nanotime overflow without loosing anything.
| if (currentChunk.tailChunk == null) { | ||
| break; | ||
| } | ||
| currentChunk = currentChunk.tailChunk; |
There was a problem hiding this comment.
Reading mutable fields without synchronization. trim and put do mutation of:
- cursor
- startIndex
- tailChunk
So result can be totaly wrong, even negative.
|
General comment: |
…e for 416 days from reservoir creation.
|
Hi @vladimir-bukhtoyarov, As for |
|
Hi Bogdan, You wrote that package com.codahale.metrics.benchmarks;
import com.codahale.metrics.SlidingTimeWindowArrayReservoir;
import com.codahale.metrics.Snapshot;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.profile.GCProfiler;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import org.openjdk.jmh.runner.options.TimeValue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
@State(Scope.Benchmark)
public class SlidingTimeWindowReservoirsDataRaceBenchmark {
private final SlidingTimeWindowArrayReservoir reservoir = new SlidingTimeWindowArrayReservoir(200, TimeUnit.NANOSECONDS);
private AtomicLong sequence = new AtomicLong(1);
@Benchmark
@Group("contention")
@GroupThreads(2)
public void update() {
reservoir.update(sequence.incrementAndGet());
}
@Benchmark
@Group("contention")
@GroupThreads(1)
public int getSize() {
int size = reservoir.size();
if (size < 0) {
throw new IllegalStateException("size must not be negative");
}
return size;
}
@Benchmark
@Group("contention")
@GroupThreads(1)
public Snapshot getSnapshot() {
Snapshot snapshot = reservoir.getSnapshot();
if (snapshot.size() != 0 && snapshot.getMin() == 0) {
throw new IllegalStateException("Zero was never recorded and should not present in snapshot");
}
return snapshot;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(".*" + SlidingTimeWindowReservoirsDataRaceBenchmark.class.getSimpleName() + ".*")
.threads(4)
.warmupIterations(10)
.measurementIterations(10)
.addProfiler(GCProfiler.class)
.measurementTime(TimeValue.seconds(10))
.timeUnit(TimeUnit.MICROSECONDS)
.mode(Mode.AverageTime)
.forks(1)
.build();
new Runner(opt).run();
}
}Benchmark crashes in few milliseconds. # VM invoker: C:\Program Files\Java\jdk1.8.0_101\jre\bin\java.exe
# VM options: -Didea.launcher.port=7534 -Didea.launcher.bin.path=D:\dev\bin\gui-tools\IDEA\IntelliJ IDEA 2016.3\bin -Dfile.encoding=UTF-8
# Warmup: 10 iterations, 1 s each
# Measurement: 10 iterations, 10 s each
# Threads: 4 threads, will synchronize iterations
# Benchmark mode: Average time, time/op
# Benchmark: com.codahale.metrics.benchmarks.SlidingTimeWindowReservoirsDataRaceBenchmark.contention
# Run progress: 0,00% complete, ETA 00:01:50
# Fork: 1 of 1
# Warmup Iteration 1: 0,619 ±(99.9%) 1,188 us/op
# Warmup Iteration 2: <failure>
java.lang.NegativeArraySizeException
at com.codahale.metrics.ChunkedAssociativeLongArray.values(ChunkedAssociativeLongArray.java:76)
at com.codahale.metrics.SlidingTimeWindowArrayReservoir.getSnapshot(SlidingTimeWindowArrayReservoir.java:73)
at com.codahale.metrics.benchmarks.SlidingTimeWindowReservoirsDataRaceBenchmark.getSnapshot(SlidingTimeWindowReservoirsDataRaceBenchmark.java:47)
at com.codahale.metrics.benchmarks.generated.SlidingTimeWindowReservoirsDataRaceBenchmark_contention.getSnapshot_avgt_jmhStub(SlidingTimeWindowReservoirsDataRaceBenchmark_contention.java:371)
at com.codahale.metrics.benchmarks.generated.SlidingTimeWindowReservoirsDataRaceBenchmark_contention.contention_AverageTime(SlidingTimeWindowReservoirsDataRaceBenchmark_contention.java:282)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.openjdk.jmh.runner.LoopBenchmarkHandler$BenchmarkTask.call(LoopBenchmarkHandler.java:210)
at org.openjdk.jmh.runner.LoopBenchmarkHandler$BenchmarkTask.call(LoopBenchmarkHandler.java:192)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
# Run complete. Total time: 00:00:02According to jsstress - it is addional tool which can be helpful sometimes, but primary tool of any java programmer who creates concurrent code should be his brain and formal loggic described in JMM specification. If jcstress does not show errors, but code is not well formed synchronized according to JMM rules, that final decision about code correctnes should be taken according to JMM, violations of formal rules are quit enough to blame any code. And general note about dataraces: Sorry if I'm not polite. |
|
Hi Vladimir, Of course this change brings some different numbers but they are still impressive and GC pauses are even lower ( |
|
Now, It looks correct! |
|
OK, so should we replace the existing |
|
@arteam please take a look to this request. |
|
I will review tonight. Thank you! |
I reviewed and the implementation looks good (or I can't spot obvious concurrency bugs). Let's replace |
|
I would have suggested adding it as part of 3.2 and letting users opt into it, and then replace the other one in 3.3 or 4. |
|
On second thought, that's probably the best option from the point of reducing the risk of production bugs for users of 3.2. The users who will want to test this reservoir, can test use it in 3.2.3. If everything goes right, then we will make it the default one. |
Don't worry, everything should be OK now. 😄 |
|
Thank you very much for the contribution! |
|
🎉 |
|
I thought about making a release on Monday. There is a couple of useful contributions in the 3.2-development branch, which would be nice to release. |
|
Sorry for the delay, I am busy this week. Will try to make code reviews and cut a release this week. |
…egistry (#238) Support for this is desirable due to the reasons discussed in http://taint.org/2014/01/16/145944a.html and https://medium.com/hotels-com-technology/your-latency-metrics-could-be-misleading-you-how-hdrhistogram-can-help-9d545b598374 According to https://metrics.dropwizard.io/4.0.0/manual/core.html#sliding-time-window-reservoirs `SlidingTimeWindowArrayReservoir` added in dropwizard/metrics#1139 should not have the same perf issues as the old sliding time window reservoir.
Rather than using a custom reservoir in a few places use the new SlidingTimeWindowArrayReservoir everywhere. This will ensure all histograms values decay in a timely fashion with low traffic and also accurately capture min and max values. https://medium.com/expedia-group-tech/your-latency-metrics-could-be-misleading-you-how-hdrhistogram-can-help-9d545b598374 goes more into the details about what is wrong with the current histogram implantation. dropwizard/metrics#1139 and https://metrics.dropwizard.io/4.0.0/manual/core.html#sliding-time-window-reservoirs
Rather than using a custom reservoir in a few places use the new SlidingTimeWindowArrayReservoir everywhere. This will ensure all histograms values decay in a timely fashion with low traffic and also accurately capture min and max values. https://medium.com/expedia-group-tech/your-latency-metrics-could-be-misleading-you-how-hdrhistogram-can-help-9d545b598374 goes more into the details about what is wrong with the current histogram implantation. dropwizard/metrics#1139 and https://metrics.dropwizard.io/4.0.0/manual/core.html#sliding-time-window-reservoirs
Hi metrics team,
This PR provides drop-in replacement of
SlidingTimeWindowReservoircalledSlidingTimeWindowArrayReservoir. This implementation based upponChunkedAssociativeLongArraystructure which stores all values inlongarrays that are allocated and freed by big chunks. This way of storing reservoir values gives us drastically lower memory overhead overConcurrentSkipListMapused by current implementation.There is also new
metrics-jcstressmodule intoduced within this PR. I've used OpenJDK Java Concurrency Stress tests to prove thread safety of new reservoir.As for benchmarks:
On already existing benchmark called
ReservoirBenchmarknew implementation has 4.2x lower latency than old one. And most importantlySlidingTimeWindowArrayReservoirspends only271 [ms]in GC during benchmark while previous implementation spends13428 [ms]. With all this changesSlidingTimeWindowArrayReservoirnow has performance comparable withExponentiallyDecayingReservoir.I also created new benchmark called
SlidingTimeWindowReservoirsBenchmarkwith different scenario for this reservoirs. New benchmark has 3 threads that update target reservoir and 1 thread that makes snapshots. In such scenario new implementation has 2.5x faster writes, 3.5x faster snapshots and spends 40x less time in GC.Small (1 hour long) load tests for two implementations. Load test also has 3 writers and 1 reader. Frequency of writes changes by periodic function and periods become shorter with time.
Results bellow:
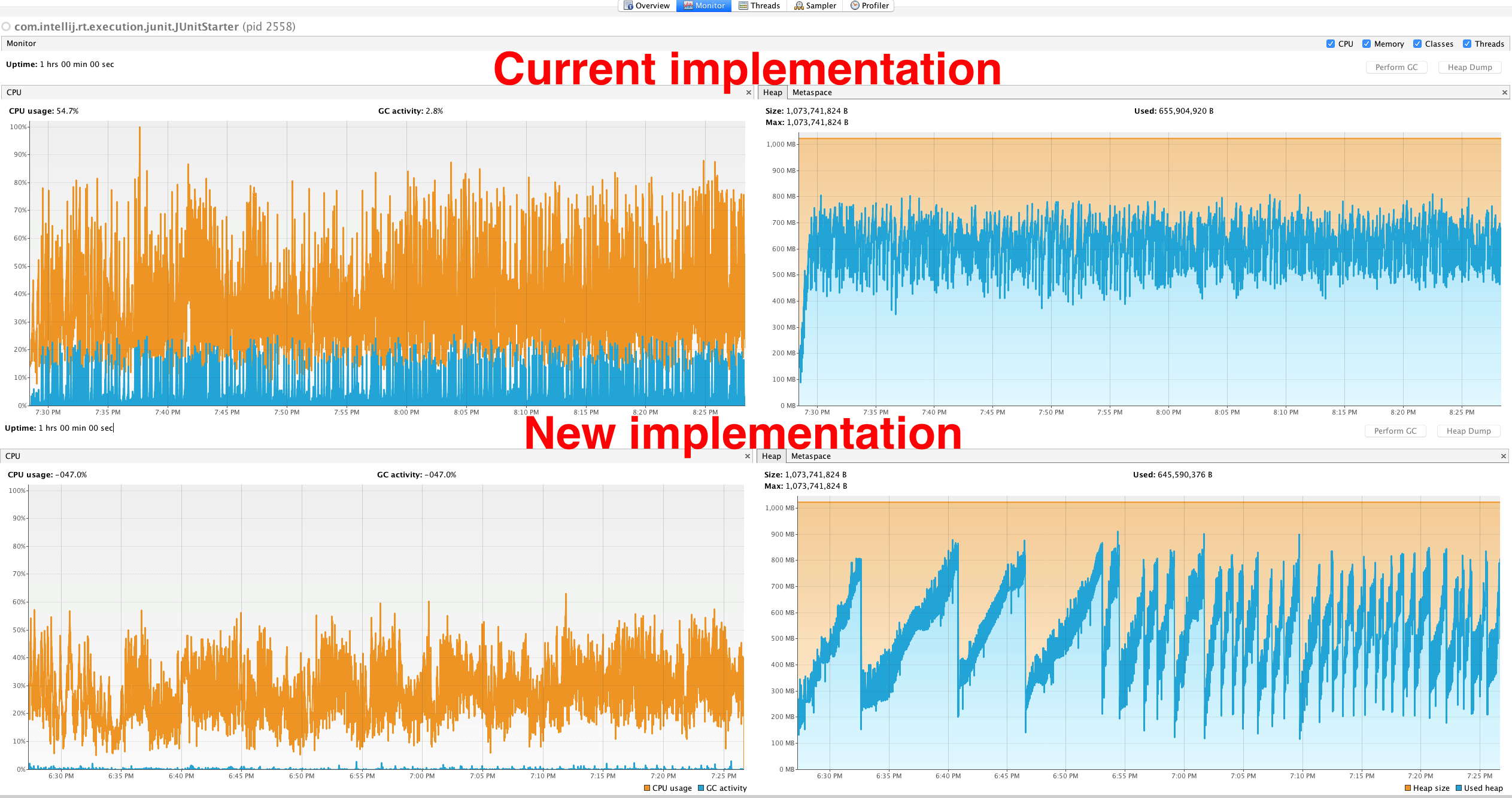
If you're OK with this changes we've basically two ways to merge this PR. We can leave this two separate reservoirs in library and give our users possibility to choose one. Or we can completely replace old implementation with new one.