
- 동영상을 입력하면 동영상의 상황/내용을 묘사하는 한국어 캡션을 생성해 주는 딥러닝 모델을 개발하고자 합니다.











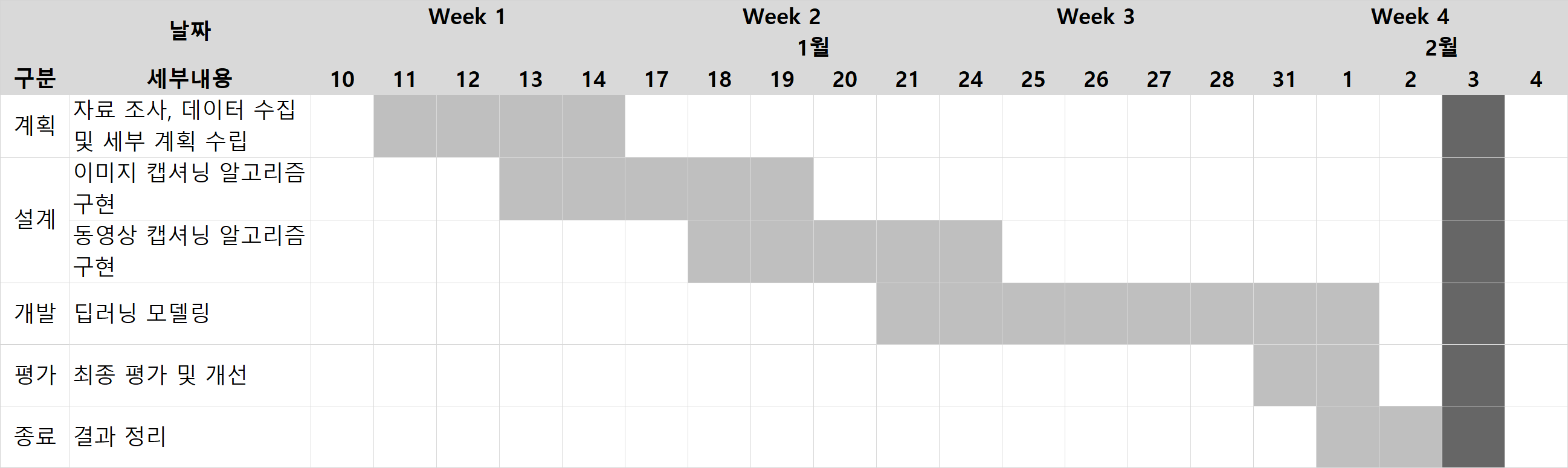
- 프로젝트 기간: 2022.01.11~2022.02.02 (3.5주)
멀티모달(Multimodal)데이터 사용
- '멀티모달'이란 언어뿐만 아니라 이미지, 영상에 이르기까지 사람의 의사소통과 관련된 다양한 정보를 습득하고 다룰 수 있는 기술을 의미합니다.
- 이런 멀티모달 기술을 사용하여, 이미지나 영상에 대한 설명글(캡션)이 자동으로 생성된다면 일상생활 속에서 다양한 서비스를 제공 할 수 있을 것이라 생각하여 프로젝트를 진행했습니다.
한국어 데이터 기반
- 기존 동영상/이미지 캡션 연구와 개발도 대다수 영어로 공개된 데이터셋이 이용되었으며, 한글 캡션을 생성하기 위해서는 영어 데이터를 번역하여 사용하거나 캡션 결과를 번역해야 했습니다.
- 하지만 국내에서도 한국어 캡션 데이터셋를 최근에서야 제공하고 있습니다. 이를 극복하기 위해, 국내 환경과 한국어에 맞는 동영상/이미지 캡션 생성 모델 개발하고자 했습니다.

- AI Hub '멀티모달' 데이터셋
- 동영상, 샷 구간 이미지, 각 이미지별 5개 상황 묘사 텍스트 데이터 사용했습니다.
- AI Hub '한국어 이미지 설명' 데이터셋
- MS COCO 캡셔닝 데이터를 한국어로 번역한 데이터입니다.

AI Hub MSCOCO Image Caption Dataset

Video Captioning Model
동영상 캡셔닝 알고리즘
- OpenCV를 통해 입력받은 동영상을 여러 프레임으로 나누고, 이미지 캡셔닝 모델을 통해 각 프레임 이미지에 대한 캡션을 생성합니다.
- 캡션이 생성된 프레임 이미지들을 OpenCV를 통해 다시 동영상으로 변환합니다.
이미지 유사도 분석
- 이미지 유사도 분석을 통해 비슷한 프레임/장면에서는 동일한 캡션을 출력하게 만들어 동영상 속 출력된 캡션이 부드럽게 전환되고, 캡셔닝 처리에 걸리는 시간도 단축시켰습니다.
- 이미지 유사도 측정은 MSE(Mean Squared Error)와 SSIM(Structured Similarity Image Matching)을 사용하였으며, 최종적으로 모델에는 SSIM을 적용하였습니다.
출력된 캡션 처리
- KoNLPy의 Kkma(꼬꼬마) 형태소 분석기를 활용하여 생성된 캡션들이 제대로 된 문장 형태(어절 단위로 구분 된 문장)처럼 출력되도록 처리했습니다.
Merge Encoder-Decoder Model

Merge Architecture for Encoder-Decoder Model in Caption Generation
- Encoder-Decoder architecture 구현을 위해 Marc Tanti, et al. (2017)가 제시한 Merge 모델을 사용
- Merge architecture에서는 이미지와 언어/텍스트 정보가 별도로 인코딩 되며, 이후 multimodal layer architecture의 Feedforward Network(FF)에서 병합(merge)되어 함께 처리됩니다.
CNN(Convolutional Neural Networks) + LSTM(Long Short-Term Memory)
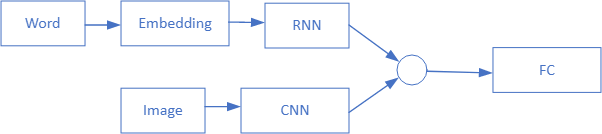
RNN as Language Model
- CNN을 이미지 데이터 인코딩을 위한 '이미지 모델'로, RNN/LSTM을 텍스트 시퀀스 데이터를 인코딩하는 '언어 모델'로 사용
- 이미지 인코딩: InceptionV3를 사용하여 전이학습(transfer learning)을 통해 이미지 특성을 추출 합니다. 여기서 추출된 이미지 특성들은 캡셔닝 모델의 input으로 사용됩니다.
- 텍스트 인코딩: FastText를 사용하여 embedding layer에서 모든 단어를 200차원 벡터로 매핑합니다. 뒤이어 LSTM layer에서 벡터 시퀀스를 처리합니다.
- Decoder 모델
- Decoder 모델은 각각 따로 처리된 이미지와 텍스트 두 입력 모델의 인코딩 결과/벡터를 병합하고 Dense layer을 통해 시퀀스의 '다음 단어'를 생성합니다.

Defined Model Structure
- 모델 학습에는 다음의 input과 output이 필요합니다.
- Input
- 이미지 특성: InceptionV3으로 추출한 이미지 특성 벡터
- 캡션 text sequence: 단어 단위로 나뉘고 인코딩 된 캡션 텍스트 시퀀스
- Output
- 다음 단어: 전체 단어 수 크기의 one-hot 인코딩 된 다음 단어
- Input
- 모델 학습을 위한 input 및 output 데이터는 data generator를 통해 생성됩니다.
- Data generator를 통해 모델에 하나의 이미지 특성(X1)과 text sequence(X2)가 input으로 주어지면 다음 단어(y)가 학습 됩니다. 이 생성된 다음 단어는 text sequence(X2)에 포함되고 해당 이미지 특성(X1)과 함께 다시 input으로 주어져 그 다음 단어(y)에 대한 학습이 이루어집니다. 이것이 모델이 훈련되는 방법입니다.
- 예를 들어, "two boys are playing baseball in the ground"라는 문장이 있다면, 이 하나의 문장과 해당 이미지에 대해 아래와 같이 처리되고 학습됩니다.

Input Data Structure
학습한 모델을 사용한 캡션 생성 과정

Caption Generation Process
- 이미지에 대한 캡션을 생성할 때, 학습한 모델은 시퀀스의 다음 단어를 예측(단어들의 연속을 예측) 하는데, 모든 단어에 대한 확률분포를 구하여 예측 힙니다. 다시 말해, 단어들의 후보 시퀀스들의 우도(likelihood)에 따라 점수화 되어 선택 됩니다.
- 이미지를 입력으로 받으면, 시퀀스의 시작을 의미하는 토큰인 'startseq'를 전달하여 단어 하나를 생성한 다음, 생성된 단어까지를 연결하여/합쳐서 다시 모델의 input으로 넘겨 그 다음 단어를 생성하게 됩니다.
- 이렇게 다음 단어를 생성하고, 지금까지 생덩된 단어들을 다시 모델에 input으로 넘기고, 또 다음 단어를 생성하는 과정을 재귀적으로 반복합니다. 그러다 아래 조건에 도달하게 되면 반복을 종료하고, 최종적으로 이미지에 대한 캡션이 만들어지게 됩니다.
- (1) 시퀀스의 끝을 의미하는 토큰인 'endseq'가 생성되거나,
- (2) 최대 캡션 길이에 도달할 때까지 반복합니다.
- 캡션을 생성하는 기법은 일반적으로 사용되는 Greedy Search와 Beam Search 두 기법을 사용했습니다.
Greedy Search
- Greedy search는 전체 단어에서 각 단어에 대한 확률 분포를 예측하여 다음 단어를 선택하는데 각 스텝에서 가장 가능성이/확률이 높은 단어를 선택합니다.
- 빠른 속도로 탐색 및 예측 과정이 완료되나, 하나의 예측만을 고려하기 때문에 minor한 변화에 영향을 받을 수 있어 최적의 예측을 하지 못활 위험이 있습니다. 쉽게 말해, 한 번이라도 잘못된 단어를 예측하게 되면 뒤이어 다 잘못된 예측이 될 수도 있다는 뜻입니다.
Beam Search
- Greedy Search의 단점을 보완하여 확장한 기법이 Beam Search 입니다.
- Beam Search에선 각 후보 시퀀스가 모든 가능한 다음 스텝들로 확대됩니다. 쉽게 말해, 가능한 모든 다음 단어/시퀀스를 예측합니다. 그리고 각 후보에 확률을 곱하여 점수가 매겨지고, 가장 확률이 높은 k개(beam size) 시퀀스가 선택되며, 다른 모든 후보들은 제거됩니다. 이 과정을 시퀀스가 끝날때까지 반복합니다.
- 예를 들어, 만약 지정한 beam size가 2라면, 각 step에서 가장 확률 높은 2개를 선택합니다.
- Greedy Search의 경우는 beam size가 1인 것과 같다고 보면 됩니다.
- beam size가 클수록 타겟 시퀀스가 맞을 확률이 높지만 decoding 속도가 떨어지게 됩니다.
BLEU(Bilingual Evaluation Understudy) Score
- 캡션 생성 평가 지표로는 기존의 이미지 캡션 논문들에서 사용되는 BLEU 스코어(BLEU-1, BLEU-2, BLEU-3, BLEU-4)를 사용했습니다.
- BLEU 스코어는 기계번역의 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 평가 지표로, 데이터의 X가 순서정보를 가진 단어들(문장)로 이루어져 있고, y 또한 단어들의 시리즈(문장)로 이루어진 경우에 사용됩니다.
- BLEU의 3가지 요소/기능입니다:
- n-gram을 통한 순서쌍들이 얼마나 겹치는지 측정(precision)
- 문장길이에 대한 과적합 보정(Brevity Penalty)
- 같은 단어가 연속적으로 나올때 과적합 되는 것을 보정(Clipping)
- 측정 기준은 n-gram에 기반하는데, 예측 문장과 정답 문장의 n-gram들이 서로 얼마나 겹치는지 비교하여 정확도를 측정하기 때문에 이미지 캡션 평가에서도 보편적으로 사용됩니다.
- 점수를 매길 최대 길이를 n-gram 길이라고 할 때, n-gram이라고 하는 연속된 n개의 단어를 기준으로 실제 캡션(ground truth)과 얼마나 공통적인 단어가 나왔는지/겹치는지를 판단해서 BLEU 점수를 계산합니다.
- 보통 1~4의 크기의 n-gram을 측정 지표로 사용합니다.
- 점수는 0.0~1.0 사이에서 나타내는데, 1.0에 가까울 수록, 높을수록 좋은 점수이며 뛰어난 캡셔닝 성능을 의미합니다.
- 사전 훈련된 CNN 모델 InceptionV3를 사용하여 이미지 특성들을 추출합니다 (추출된 이미지 특성들은 나중에 LSTM 결과/출력과 병합됩니다).
- 캡션 텍스트 시퀀스 데이터에 대해 전처리와 토큰화를 합니다. 그리도 embedding vector를 준비합니다 (텍스트 시퀀스 데이터는 나중에 임베딩 되고 LSTM에서 처리됩니다).
- 이미지 특성 데이터와 텍스트 시퀀스 데이터를 Train/Test 데이터로 나눕니다. 그리고 Train 텍스트 데이터를 기준으로 단어-인덱스 사전을 만들고 전체 단어 개수와 최대 캡션 길이를 구합니다. 이 때, 최소 빈도수 threshold를 설정해 학습에 사용할 단어 수를 줄이기도 합니다.
- 모델을 구현(define)합니다. 이 때, 준비한 embedding vector를 사용해 모든 단어에 대한 embedding matrix를 만들어 모델의 embedding layer에 적용합니다.
- 모델을 학습시킵니다.
- 훈련된 모델을 사용해 이미지 캡션을 생성해 모델에 대한 정성적 평가를 합니다. Greedy Search와 Beam Search 모두를 사용합니다.
- BLEU 평가를 통해 모델에 대한 정량적 평가를 합니다.

- 모델링은 아래의 요소들을 변경해가며 진행했습니다.
- 데이터셋, 임베딩 방법, 텍스트 전처리 및 토큰화 방법, 단어 최소 빈도수 threshold, 에포크(epoch), 배치사이즈(batch size), 학습률(learning rate), 교차검증(cross validation)
- 이미지 특성 추출은 모든 과정에서 동일하게 pre-trained model인 InceptionV3를 사용했습니다.
- 실험을 거치면서 BLEU 스코어가 지속적으로 증가했습니다. 결론적으로 마지막 모델이 가장 높은 성능을 보였습니다.


Model Architecture of the Trial
실험 배경
- 동영상이라는건 결국 이미지들의 연속이며, 데이터 구조를 보면 동영상 안에는 여러 장면들이 있고 하나의 동일한 장면에 대해선 프레임 이미지들이 다 비슷합니다. 그리고 캡션도 동일합니다.
- 그렇다면 이러한 비슷한 이미지들을 중복하여 학습할 필요 없이, 각 영상마다 유니크한 캡션들과 관련 이미지들만 추출하여 학습을 해도 충분할 것이라 생각하였습니다. 유니크한 캡션들과 이미지들만 학습시킨다면, 최초 수집한 60만개 데이터를 다 사용하지 않더라도 다양한 이미지와 캡션을 학습시킬 수 있기 때문에 모델이 잘 일반화되고 좋은 성능을 보일것으로 기대했습니다.
실험 내용
| 설정 | 내용 |
|---|---|
| 데이터셋 | AI Hub 멀티모달 데이터셋 |
| 데이터 규모 | 전체 600,000개 데이터 중 약 26,000개의 고유한 캡션과 이미지들을 추출하여 사용 |
| 데이터셋 분리 | Train(70%):Test(30%) |
| 임베딩 | Glove를 사용하여 자체 데이터로 학습 하였고 200차원의 embedding matrix를 만들어 모델에 적용 |
| 텍스트 처리 | 어절(띄어쓰기) 단위로 처리 |
| 최소 빈도수 | 최소 빈도수 3 미만의 단어 제외 |
| 학습 단위 | Epoch 40, Batch Size 3, Learning Rate 0.001 |
실험 결과
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| 0.486578 | 0.334570 | 0.229077 | 0.090989 |
- BLEU 점수는 1에 가까울 수록 좋은 점수인데, 평가 결과 낮은 점수를 보입니다.
- 모든 테스트 이미지들에 대해 동일한 동일한 캡션을 출력했습니다.


AI Hub 멀티모달 데이터셋 이미지 테스트 캡션

Model Architecture of the Trial
실험 배경
- 이전 실험에서 결과가 좋지 않았던 이유가 각 고유한 캡션에 대해 이미지가 1개씩만 있어 이미지들이 가지는 특성을 제대로 학습을 하지 못한 것이 아닐까 생각했습니다.
- 또한, 어절 단위 모델의 경우 조사에 따라 동일 단어가 다른 단어로 인식하기 때문에 데이터의 부족으로 인한 오류가 발생했을 것으로 생각했습니다.
- 이에 따라, 이번엔 연속적인 이미지들을 사용하여 다시 모델링을 진행했습니다.
실험 내용
| 설정 | 내용 |
|---|---|
| 데이터셋 | AI Hub 멀티모달 데이터셋 |
| 데이터 규모 | 150개 영상 규모의 약 160,000개 데이터 사용 |
| 데이터셋 분리 | Train(70%):Test(30%) |
| 임베딩 | 사전훈련된 FastText 임베딩 모델을 사용하여 200차원의 embedding matrix를 만들어 모델에 적용 |
| 텍스트 처리 | 불용어 제거 후 명사, 형용사, 동사 등의 의미형태소 단위로 처리 및 어간 추출 |
| 최소 빈도수 | 최소 빈도수 threshold 미설정 |
| 학습 단위 | Epoch 10, Batch Size 3, Learning Rate 0.001 |
실험 결과
- 여전히 모든 테스트 이미지들에 대해 동일한 동일한 캡션을 출력했습니다.


AI Hub 멀티모달 데이터셋 이미지 테스트 캡션
Model Architecture of the Trial
실험 배경
- 이전 실험에서 학습한 모델이 모든 이미지들에 대해 동일한 캡션만 출력한 이유에 대해, 학습시킨 이미지들이 문제인 것이 아닐까 생각했습니다. 학습에 사용한 이미지들을 살펴보면 그저 사람 또는 사람 얼굴만 나오는 경우가 많았고, 특별한 패턴이나 특징이 없다고 생각했습니다. 그래서 InceptionV3 모델이 이미지들로부터 특별한, 구별되는 특성들을 잡아내지 못한 것이 아닐까 생각했습니다.
- 또한, 캡션 텍스트 데이터의 단어들의 종류, 즉 다양성도 부족하다고 생각했습니다.
- 그래서 다양한 사진들과 캡션으로 이루어진, 사진들마다의 특징들이 더 분명해 보이는 AI Hub의 MSCOCO 이미지 설명 데이터로 학습하여 다시 테스트해 보았더니 이미지별로 다른 캡션을 생성하는 것을 확인했습니다. 결국, 기존의 멀티모달 영상/이미지 데이터는 모델이 구별되는 특성을 파악하기 어렵고 캡션 단어들도 다양하지 않기 때문에 학습이 제대로 되지 않은 것입니다.
- 따라서, AI Hub의 MSCOCO 이미지 설명 데이터 약 120,000개를 수집해 사용하여 다시 모델링을 시도했습니다.
- 그리고 batch size를 제대로 학습하기에 너무 작게 설정한 것일 수도 있다 생각하여, 보다 안정적인 학습을 위해 batch size도 8로 늘려서 진행했습니다.
실험 내용
| 설정 | 내용 |
|---|---|
| 데이터셋 | AI Hub MSCOCO 이미지 설명 데이터셋 |
| 데이터 규모 | 약 120,000개 데이터 |
| 데이터셋 분리 | Train(70%):Test(30%) |
| 임베딩 | 사전훈련된 FastText 모델 사용 |
| 텍스트 처리 | 의미형태소 단위로 처리 및 어간 추출 |
| 최소 빈도수 | 최소 빈도수 10 미만의 단어 제외 |
| 학습 단위 | Epoch 30, Batch Size 8, Learning Rate 0.001 |
실험 결과
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| 0.613606 | 0.370514 | 0.259467 | 0.132638 |
- Trial 1과 비교하여 BLEU 점수가 크게 증가했습니다.
- BLEU-1(+13점), BLEU-2(+4점), BLEU-3(+3점), BLEU-4(+4점)
- 그리고 테스트 이미지들에 대해 다 다른 캡션을 출력하였고, 개선된 캡션 생성 성능을 보였습니다..


AI Hub 멀티모달 데이터셋 이미지 테스트 캡션
Model Architecture of the Trial
실험 배경
- 이전 실험에서 성능이 좋아진 것을 확인했기 때문에, 이번에는 batch size를 16으로 더 늘려서 진행했습니다.
실험 내용
| 설정 | 내용 |
|---|---|
| 데이터셋 | AI Hub MSCOCO 이미지 설명 데이터셋 |
| 데이터 규모 | 약 120,000개 데이터 |
| 데이터셋 분리 | Train(70%):Test(30%) |
| 임베딩 | 사전훈련된 FastText 모델 사용 |
| 텍스트 처리 | 의미형태소 단위로 처리 및 어간 추출 |
| 최소 빈도수 | 최소 빈도수 10 미만의 단어 제외 |
| 학습 단위 | Epoch 30, Batch Size 16, Learning Rate 0.001 |
실험 결과
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| 0.662971 | 0.417041 | 0.295106 | 0.156322 |
- Trial 2와 비교하여 BLEU 점수가 더 증가했습니다.
- BLEU-1(+5점), BLEU-2(+5점), BLEU-3(+4점), BLEU-4(+2점)
- MSCOCO 이미지 캡셔닝에 대한 사람의 BLEU 점수는 BLEU-1 67점, BLEU-2 47점, BLEU-3 32점, BLEU-4 22점이라고 합니다. Trial 3의 BLEU-1 점수 66점은 사람의 BLEU-1 점수인 67점과 비슷한 점수를 보였습니다. BLEU-2, 3, 4 또한 비교할만한 성능을 보여줬다고 생각합니다.


AI Hub 멀티모달 데이터셋 이미지 테스트 캡션
Model Architecture of the Trial
실험 배경
- 이번 실험에선 epoch 20까지는 batch size 16으로 학습하고, epoch 21~30까지는 batch size 32로 높이되 learning rate을 0.001 --> 0.0001로 낮췄습니다. Batch size가 크면 learning rate을 작게 줄이는 것이 학습 효과가 더 좋기 때문입니다.
- Learning rate를 너무 크게 설정할 경우, 최적화된 W 값을 지나쳐 학습이 이루어지지 않고 오류가 발생하는 오버슈팅(overshooting)이 발생 할 수 있습니다. 그래서 학습 후반부에는 모델 convergence를 위해 learning rate을 낮춰 낮은 보폭으로 minima를 찾아야 합니다. 그리고 generalization 측면에서도 낮은 learning rate이 flat minima를 찾는데 도움이 됩니다.
- 또한, learning rate은 낮아졌지만 batch size는 증가했기에 local minima로 빠지는 것을 막을 수도 있습니다.
실험 내용
| 설정 | 내용 |
|---|---|
| 데이터셋 | AI Hub MSCOCO 이미지 설명 데이터셋 |
| 데이터 규모 | 약 120,000개 데이터 |
| 데이터셋 분리 | Train(70%):Test(30%) |
| 임베딩 | 사전훈련된 FastText 모델 사용 |
| 텍스트 처리 | 의미형태소 단위로 처리 및 어간 추출 |
| 최소 빈도수 | 최소 빈도수 10 미만의 단어 제외 |
| 학습 단위 | Epoch 20, Batch Size 16, Learning Rate 0.001 + Epoch 10, Batch Size 32, Learning Rate 0.0001 |
실험 결과
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| 0.674453 | 0.432529 | 0.310111 | 0.169415 |
- Trial 3과 비교해서도 BLEU 점수가 더 증가했습니다.
- BLEU-1(+1점), BLEU-2(+2점), BLEU-3(+2점), BLEU-4(+1점)
- 사람의 BLEU 점수(BLEU-1 67점, BLEU-2 47점, BLEU-3 32점, BLEU-4 22점)와 비교하여 매우 근접한 성능을 보여줬습니다.


AI Hub 멀티모달 데이터셋 이미지 테스트 캡션

Model Architecture of the Trial
실험 배경
- 가장 성능이 좋았던 Trial 4와 동일하게 epoch 20까지는 batch size 16, learning rate 0.001로 학습하고, epoch 21~30까지는 batch size 32, learning rate 0.0001로 학습 했습니다.
- 하지만 이번 실험에선 캡션 데이터를 의미형태소 뿐만 아니라 기능형태소(조사, 어미 등 문법적관계를 표현하는 형태소)를 포함하여 처리하였습니다. 기능형태소는 제한적인 어휘를 가지기 때문에 예측 성능이 높게 나타날 수 있기 때문입니다.
- 그리고 기능형태소를 포함하였기에 단어 토큰 수가 증가하였는데, 학습할 토큰 단어들의 종류가 충분히 있어야 학습에도 도움이 될 것 같아 학습할 데이터에 맞춰 최소 빈도수 threshold는 4로 변경했습니다.
실험 내용
| 설정 | 내용 |
|---|---|
| 데이터셋 | AI Hub MSCOCO 이미지 설명 데이터셋 |
| 데이터 규모 | 약 120,000개 데이터 |
| 데이터셋 분리 | Train(70%):Test(30%) |
| 임베딩 | 사전훈련된 FastText 모델 사용 |
| 텍스트 처리 | 의미형태소+기능형태소 단위 |
| 최소 빈도수 | 최소 빈도수 4 미만의 단어 제외 |
| 학습 단위 | Epoch 20, Batch Size 16, Learning Rate 0.001 + Epoch 10, Batch Size 32, Learning Rate 0.0001 |
실험 결과
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| 0.671619 | 0.477204 | 0.367619 | 0.234462 |
- Trial 4와 비교하여 BLEU 점수가 더 향상되었습니다.
- BLEU-1은 거의 동일했고, BLEU-2(+4점), BLEU-3(+6점), BLEU-4(+7점) 점수 모두 증가했습니다.
- 사람의 BLEU 점수(BLEU-1 67점, BLEU-2 47점, BLEU-3 32점, BLEU-4 22점)와 비교하여 더 나은 성능을 보여줬습니다.
- 또한, 기능형태소를 포함하였더니 생성된 캡션도 문장 처럼 더욱 자연스러워 졌습니다.


AI Hub 멀티모달 데이터셋 이미지 테스트 캡션
Model Architecture of the Trial
실험 배경
- 캡셔닝 성능이 많이 개선되었지만, 일부 사람만 등장하는 이미지에 대해 비슷한 캡션을 출력하는 오류를 확인하여, 이에 대해 혹시 과적합(overfitting)으로 인한 문제가 아닐까 생각했습니다.
- Trial 5와 동일한 설정에서 cross validation을 추가하여 학습하면서 overfitting에 대한 모니터링을 진행했습니다. 그리고 validation loss가 더 이상 낮아지지 않는 지점의 모델을 찾았습니다.
실험 내용
| 설정 | 내용 |
|---|---|
| 데이터셋 | AI Hub MSCOCO 이미지 설명 데이터셋 |
| 데이터 규모 | 약 120,000개 데이터 |
| 데이터셋 분리 | Train(70%):Validation(15%):Test(15%) |
| 임베딩 | 사전훈련된 FastText 모델 사용 |
| 텍스트 처리 | 의미형태소+기능형태소 단위 |
| 최소 빈도수 | 최소 빈도수 4 미만의 단어 제외 |
| 학습 단위 | Epoch 20, Batch Size 16, Learning Rate 0.001 + Epoch 10, Batch Size 32, Learning Rate 0.0001 |
실험 결과
| BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 |
|---|---|---|---|
| 0.677784 | 0.481672 | 0.370388 | 0.236028 |
- Trial 5와 비교하여 BLEU 점수가 미미하지만 상승했습니다.
- BLEU-1 점수가 약 +1점 가까이 증가하였고, BLEU-2, 3, 4는 거의 동일합니다.
- Trial 5와 마찬가지로 Trial 6도 사람의 BLEU 점수(BLEU-1 67점, BLEU-2 47점, BLEU-3 32점, BLEU-4 22점)와 비교하여 더 나은 성능을 보여줬습니다.
- 결론적으로, 마지막 모델링 Trial 6에서 가장 좋은 성능을 보여주었습니다.


AI Hub 멀티모달 데이터셋 이미지 테스트 캡션
캡션 생성은 이미지나 영상을 설명하는 캡션을 자동으로 생성하는 기술로 이미지/시각 처리 기술과 자연어 처리 기술이 합쳐진 어려운 기술이지만, 이미지 검색, 유아 교육, 청각 장애인들을 위한 캡셔닝 서비스와 같은 응용에 사용될 수 있는 중요한 기술입니다.
1. 사진이나 동영상에 대한 검색/SEO 개선과 컨텐츠 접근성 향상
- 사진이나 동영상에 캡션을 입히는 것을 통해, 동영상 플랫폼이나 컨텐츠 제작자는 영상에 대한 검색엔진최적화, 즉 SEO를 개선할 수 있습니다. 구글 등 검색 엔진에선 이미지나 영상 검색에 대한 검색의 질도 향상 시킬 수 있습니다.
- 또한, 일상적으로 동영상을 시청할 때 소리 없이 습관적으로 시청하거나 해야하는 경우가 종종 있습니다. 이러한 경우, 시청자 입장에선 동영상 속 상황이나 내용을 더 쉽게 이해할 수 있을 것이며, 더 다양한 컨텐츠에도 접근 할 수 있게 될 것입니다.
2. 시각 또는 청각이 불편한 사람들에게 사진/동영상을 설명
- 캡셔닝 기술을 전자고글이나 카메라 등 디바이스에 접목시킨다면 시각 장애를 가진 사람들에게 영상에 대한 설명을 음성으로 제공하거나 길안내 등에 사용 될 수 있으며, 청각이 불편한 사람들에겐 영상에 캡션이 함께 제공되어 영상 속 상황이나 행동을 더 쉽게 이해할 수 있어 미디어/컨텐츠에 대한 접근성/접근 환경을 개선 할 수 있습니다.
3. 자율 주행 차량에 활용
- 차량 주변 장면/환경에 대해 캡션을 적절하게 생성 할 수 있게 되면 자율 주행 시스템을 더욱 고도화 할 수 있습니다.
4. CCTV 감시 장비에 활용
- CCTV에 캡셔닝 기술을 적용하여 위험한 무기나 상황을 탐지하여 알람을 보내는 등 위험 사전 방지와 치안유지에 도움이 될 것입니다.
5. 미술 심리 치료
- 입력된 그림을 기록하여 전문 상담사들이 그림에 대한 질문을 제시하여 내면의 심리를 상세하게 기록할 수 있도록 돕는 등 미술 심리치료에도 활용될 수 있습니다.
6. 언어 교육
- 이미지나 동영상에 대한 한국어 설명글을 통해 아동이나 외국인에게 언어 교육도 제공 할 수 있을 것입니다.
- 모델링 결과, 사람의 캡션 BLEU 점수보다 더 높은 점수를 받아, 더 나은 정확도를 보였습니다.
- 모델 학습에 사용할 데이터가 중요하다는 것을 느꼈습니다.
- 이미지에 대한 학습과 특성 추출은 패턴을 기반으로 학습이 되기 때문에, 뚜렷하고 구분되는 패턴이나 특징이 없는 이미지를 넣어 학습을 하면 성능이 좋지 않다는 것을 확인했습니다.
- 빈도수가 너무 적은 단어까지 포함시켜 학습을 하게 되면 시간이 많이 소요될 뿐만 아니라 정확도가 낮아질 수 있습니다. 하지만 학습시킬 단어 토큰 종류도 충분히 있어야 제대로 학습이 될 수 있습니다. 따라서, 모델링시 단어 토큰 수/규모에 따라 적당한 threshold를 지정하는 것이 중요 합니다.
- 메모리 가용 범위 내에서 batch size를 크게 잡는 것이 안정적이고, 좋은 성능으로 학습 할 수 있습니다.
- 모델 학습이 빨리 되기 때문에, cross validation 등 과적합을 줄이기 위한 조치가 필요합니다.
- 캡션 텍스트 처리와 토큰화는 어절이나 의미형태소 단위로만 처리하는 것보다 의미형태소와 기능형태소를 포함하는 것이 더 성능이 좋습니다.
모델의 캡션 예측/생성 성능 향상을 위한 시도
- 더 많은 데이터를 사용하여 학습한다면 캡션 예측/생성 성능이 더 좋아질 것이기 때문에
- 새로운 데이터를 더 확보하거나,
- AI Hub MSCOCO와 멀티모달 두 데이터를 합쳐 모델 학습 진행
- 모델 아키텍쳐를 변경하여 모델링 (e.g. Bidirectional RNNs/LSTMs 사용, Attention 메커니즘 기법 사용 사용)
- Pre-trained CNN 모델로 transfer learning시 여러 fine tuning 시도 (e.g. trainable layer 증가)
- AI Hub 멀티모달 데이터셋을 이용한 모델링시 사전학습된 모델이 아닌 자체 CNN 모델을 설계하여 처음부터 학습하여 모델링
- 여러 하이퍼파라미터 튜닝 시도 (e.g. learning rate, batch size, embedding dimension 300, number of layers, number of units, dropout rate, batch normalization 등 조정)
- 영상을 표현하는 시각 특징 외에, 정적 그리고 동적 의미 특징들도 이용
출력된 캡션에 대한 추가적인 처리
- 문장이 완전하지 않은 형태로 출력 되는 경우가 있습니다. 예를 들어, "...에 서있다"가 맞는 형태이지만, "...에서 있다"로 출력이 되는 경우입니다. 더 고도화한 문장 생성 및 출력을 위해 형태소 분석이나 관련 기능을 조사하여 적용이 필요합니다.
- Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2015). Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3156-3164).
- Masters, D., & Luschi, C. (2018). Revisiting small batch training for deep neural networks. arXiv preprint arXiv:1804.07612.
- Smith, S. L., Kindermans, P. J., Ying, C., & Le, Q. V. (2017). Don't decay the learning rate, increase the batch size. arXiv preprint arXiv:1711.00489.
- Kandel, I., & Castelli, M. (2020). The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express, 6(4), 312–315. https://doi.org/10.1016/j.icte.2020.04.010
- Tanti, M., Gatt, A., & Camilleri, K. P. (2017). What is the role of recurrent neural networks (rnns) in an image caption generator?. arXiv preprint arXiv:1708.02043.
- Tanti, M., Gatt, A., & Camilleri, K. P. (2018). Where to put the image in an image caption generator. Natural Language Engineering, 24(3), 467-489.
- Mao, J., Xu, W., Yang, Y., Wang, J., Huang, Z., & Yuille, A. (2014). Deep captioning with multimodal recurrent neural networks (m-rnn). arXiv preprint arXiv:1412.6632.
- Park, Seong-Jae & Cha, Jeong-Won. (2017). Generate Korean image captions using LSTM. Proceedings of the Korean Society for Language and Information Conference, (), 82-84.
- Lamba, H. (2019, February 17). Image Captioning with Keras. Medium. https://towardsdatascience.com/image-captioning-with-keras-teaching-computers-to-describe-pictures-c88a46a311b8
- Brownlee, J. (2020, December 22). How to Develop a Deep Learning Photo Caption Generator from Scratch. Machine Learning Mastery. https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
- Data-Stats. (n.d.). Image-Captioning-using-Keras-and-Tensorflow. GitHub. https://github.com/data-stats/Image-Captioning-using-Keras-and-Tensorflow
- Tang. (n.d.). Image Caption using Neural Networks. GitHub. https://xiangyutang2.github.io/image-captioning/
- Captioning Leaderboard. (n.d.). COCO - Common Objects in Context. https://cocodataset.org/#captions-leaderboard