
NOTE: This was originally a DSSG 2018 project. If you want to see the code generated by the DSSG 2018 team go here
Many Chilean workers face significant workplace safety issues. Dirección del Trabajo, Chile’s labor department, helps reduce the risks workers face through inspections and remediations, but they spend a lot of time inspecting facilities reactively based on complaints or facilities where no significant hazards exist. Dirección del Trabajo has taken steps to focus its limited resources on the facilities that need it most, including with some machine learning and a field trial. We will use historical violation and safety records, as well as business, geographic, and other data to help improve their inspection targeting.
The problem will be posed as a resource prioritization problem.
The main objective of this project is to identify the most violations
given DT’s limited resources. We would like to
identify the probability of a violation given a facility’s inspection
status, P(V|I). Notably, we need to know the inspection status of the
facility to correctly identify this effect.
So, the ML question that we want to answer is:
Which X facilities are most likely to fail an inspection in the following Y period of time?
Where X is determined by the resources that DT has for inspections (basically the number of inspectors available and the length of the inspection, which depends on the complexity of it), and Y refers to how frequent DT needs to generate the list of facilities to be inspected.
For example, one pose the problem as
Which X=500 facilities are most likely to fail an inspection in the following Y=1 month?
An additional problem with the data is that we have precise information about the all the companies, not about all the facilities (but we will try to alleviate that using record linkage techniques and incorporating other data sources.
-
DT wants to know
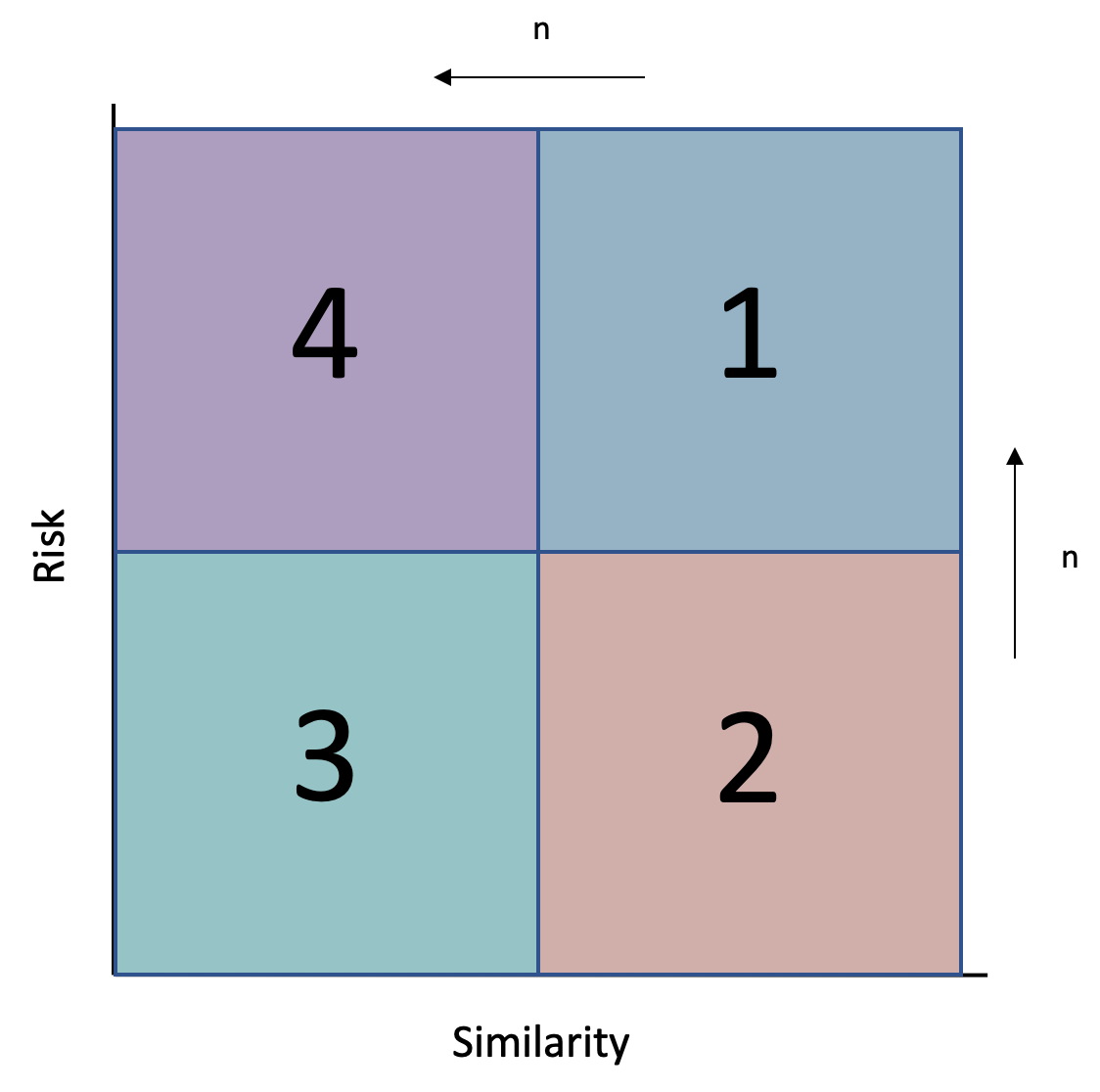
P(V)i.e. probability of a violation, notP(V|I), probability of a violation given an inspection. We could alleviate this problem if we supplement this information with a similarity model, assessing how similar a facility is to those previously inspected (i.e.P(I), probability of being inspected). Fewer than half of facilities have been inspected in the past, and they differ in significant ways from the rest, not the least of which is that they haven’t had safety complaints. By plotting risk score against similarity, DT can easily compare a facility’s risk and our confidence in the score. The higher the facility, the higher the estimated risk; and the farther right the facility, the more the facility is like other facilities that have been inspected. DT will want to inspect facilities from all four quadrants, but more from 1 and 4 than 3 and 2, and more from 4 and 3 than 1 and 2.-
Another consideration is that the inspectors are assigned to specific regions of Chile, so, we need to tailor the list of facilities at risk to a particular region given the resources of that region.
-
Lastly, as mentioned before, the complexity of an inspection is partially determined by the size of the facility and by the materia (type of violation) inspected. If we don’t take in account this nuance, the inspector won't know which violations to look for.
-
Taking all of that in account the ML question is:
For a given region, which X facilities are most likely to violate a specific subset of materias if inspected in the following Y period of time?
NOTE: Is important to mention that in this iteration of the project we didn’t take in account the region or the materias.
Triage was built at DSaPP to facilitate
the creation of supervised learning models, in particular binary
classification models with a strong temporal component in the data.
Triage uses the concept of an experiment. An experiment consists of a
series of steps that aim to generate a good model for predicting the
label of an entity in the data set. The steps are data time-splitting,
label generation, feature generation, matrix creation, model training,
predictions, and model evaluation. In each of these steps, triage will
handle the temporal nuances of the data.
You should check the Triage documentation.
If you want to try Triage first, you should go through the Triage tutorial.
All the triage’s configuration files are located in the folder experiments
-
DSSG 2018 results are discussed in the branch dssg2018
-
The project was suspended by the partner in November 2018.