Below is an excerpt of the design section of my thesis automatically converted to markdown. I recommend you instead go to the Design section in my thesis
The file system is set up hierarchically: data is stored in files which are kept in folders. Folders can contain other folders. The hierarchy looks like a tree where each level may have 1 to n nodes.
The POSIX has enabled applications to be developed once for all complying file system and my system's API is based on it. If we expand beyond POSIX by adding methods that allow for greater performance we exclude existing applications from these gains. This is a trade-off made by Ceph () by implementing part of the POSIX HPC IO extensions [@hpc_posix]. Ceph also trades in all consistency for files using the HPC API.
Key to my approach is also expanding the file system API beyond POSIX. While this makes my system harder to use it does not come at a cost of reducing consistency. Specifically my system expands upon POSIX with the addition of open region. A client that opens a file region can access only a range of data in the file. This API enables consistent limited parallel concurrent writes on, or combinations of reading and writing in the same file.
Like Ceph in my system clients gain capabilities when they open files. These capabilities determine what actions a client may perform on a file. There are four capabilities:
4
-
read
-
read region
-
write
-
write region
A client with write capabilities may also read data. Similar to Ceph capabilities are only given for a limited time, this means a client is given a lease to certain capabilities. The lease needs to be renewed if the client is not done with its file operations in time. The lease can also be revoked early by the system.
My system tracks the capabilities for each of its files. It will only give out capabilities that uphold the following:
- Multiple clients can have capabilities on the same file as long as write capabilities have no overlap with any region.
My system uses hierarchical leadership, there is one president elected by all servers. The president in turn appoints multiple ministers then assigns each a group of clerks. A minister contacts its group, and promotes each member from idle to clerk, forming a ministry.
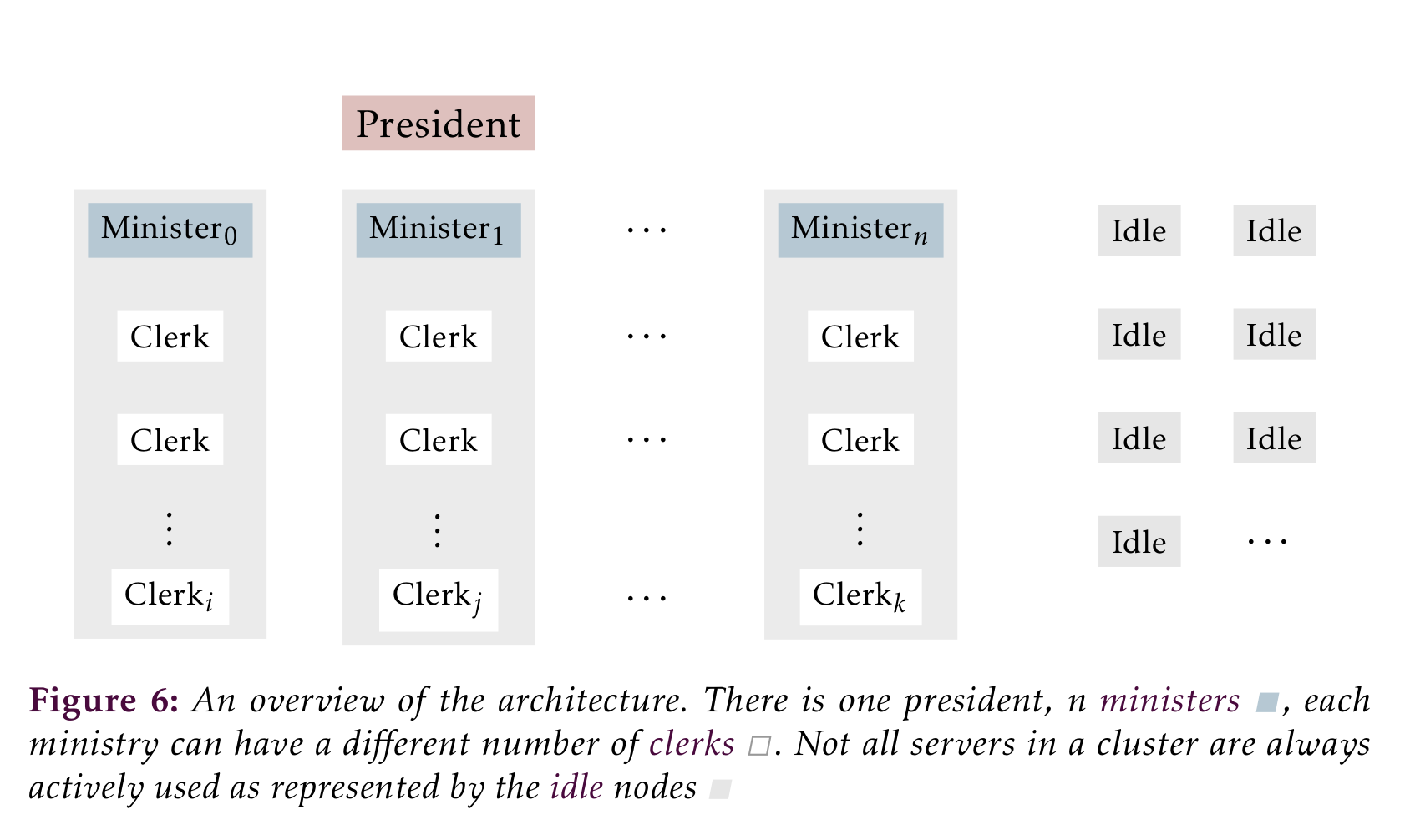
The president coordinates the cluster: monitoring the population, assigning new ministers on failures, adjusting groups given failures and load balances between all groups. Load balancing is done in two ways: increasing the size of a group and increasing the number of groups. To enable the president to make load balancing decisions each minister periodically sends file popularity.
Metadata changes are coordinated by ministers, they serialize metadata modifying requests and ensures the changes proliferate to the ministry's clerks. Changes are only completed when they are written to half of the clerks. Each minister also collects file popularity by querying its clerks periodically. Finally, write capabilities can only be issued by ministers.
A ministry's clerks handle metadata queries: issuing read capabilities and providing information about the file system tree. Additionally, each clerk tracks file popularity to provide to the minister.
It is not a good idea to assign as many clerks to ministries as possible. Each extra clerk is one more machine the minister needs to contact for each change. The cluster might therefore keep some nodes idle. I will get back to this when discussing load balancing in .
Consistent communication has a performance penalty and complicates system design. Not all communication is critical to system or data integrity. I use simpler protocols where possible.
The president is elected using Raft. Its coordination is communicated using Raft's log replication. On failure a new president is elected by all nodes.
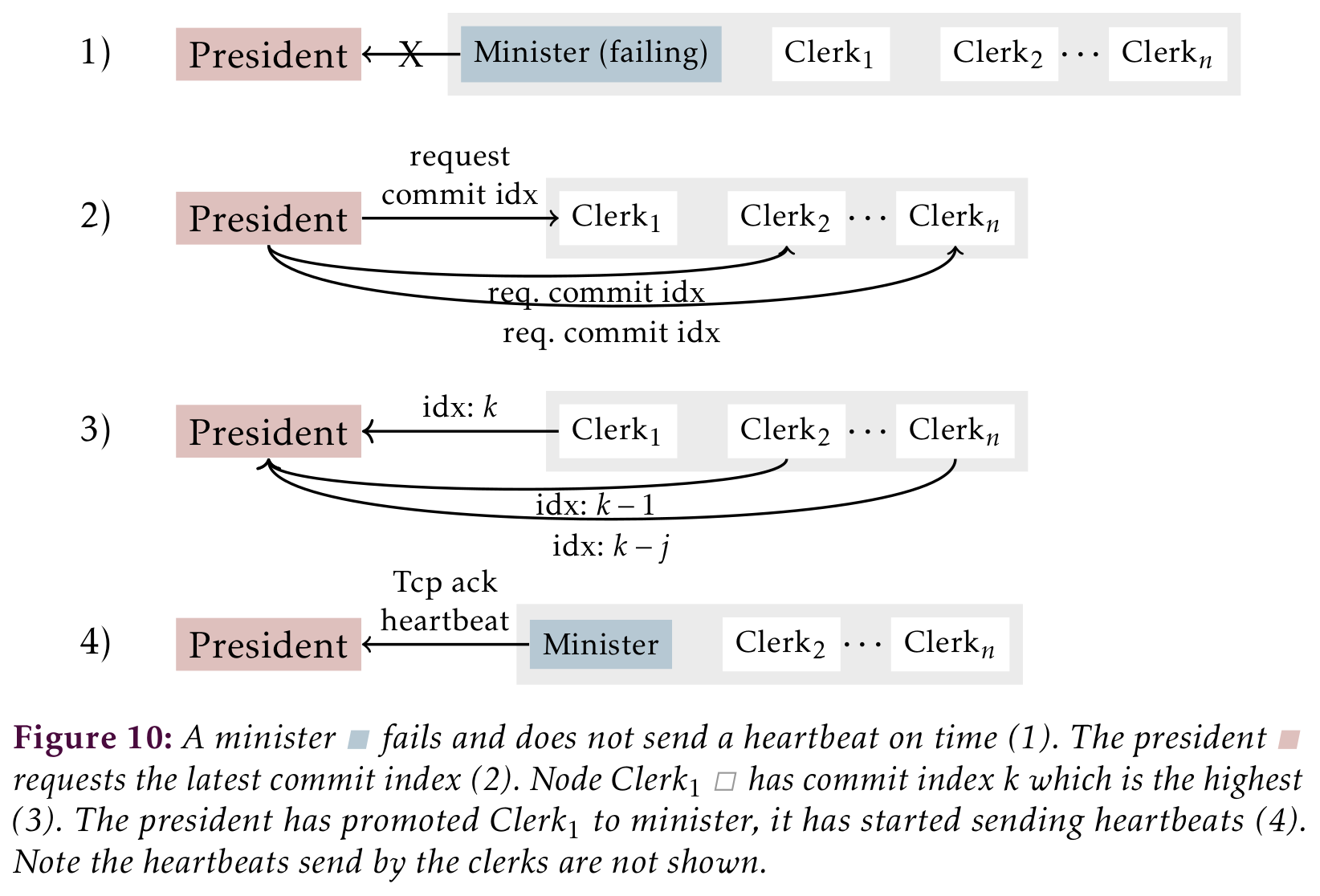
Communication from the minister to its ministries clerks uses log replication similar to Raft. When a minister is appointed it gets a Raft term. Changes to the metadata are shared with clerks using log replication. A minister can fail after the change was committed but before the client was informed of the success. The log index is shared with the client before it is committed, on minister failure the client can check with a clerk to see if its log entry exists[^13]. When the minister fails the president selects the clerk with the highest commit index as the new minister. I call this adaptation pRaft.
Load reports to the president are sent over TCP, it will almost always insure the reports arrive in order. A minister that froze, was replaced and starts working again however can still send outdated reports. By including the term of the sending minister the president detects outdated reports and discards them.
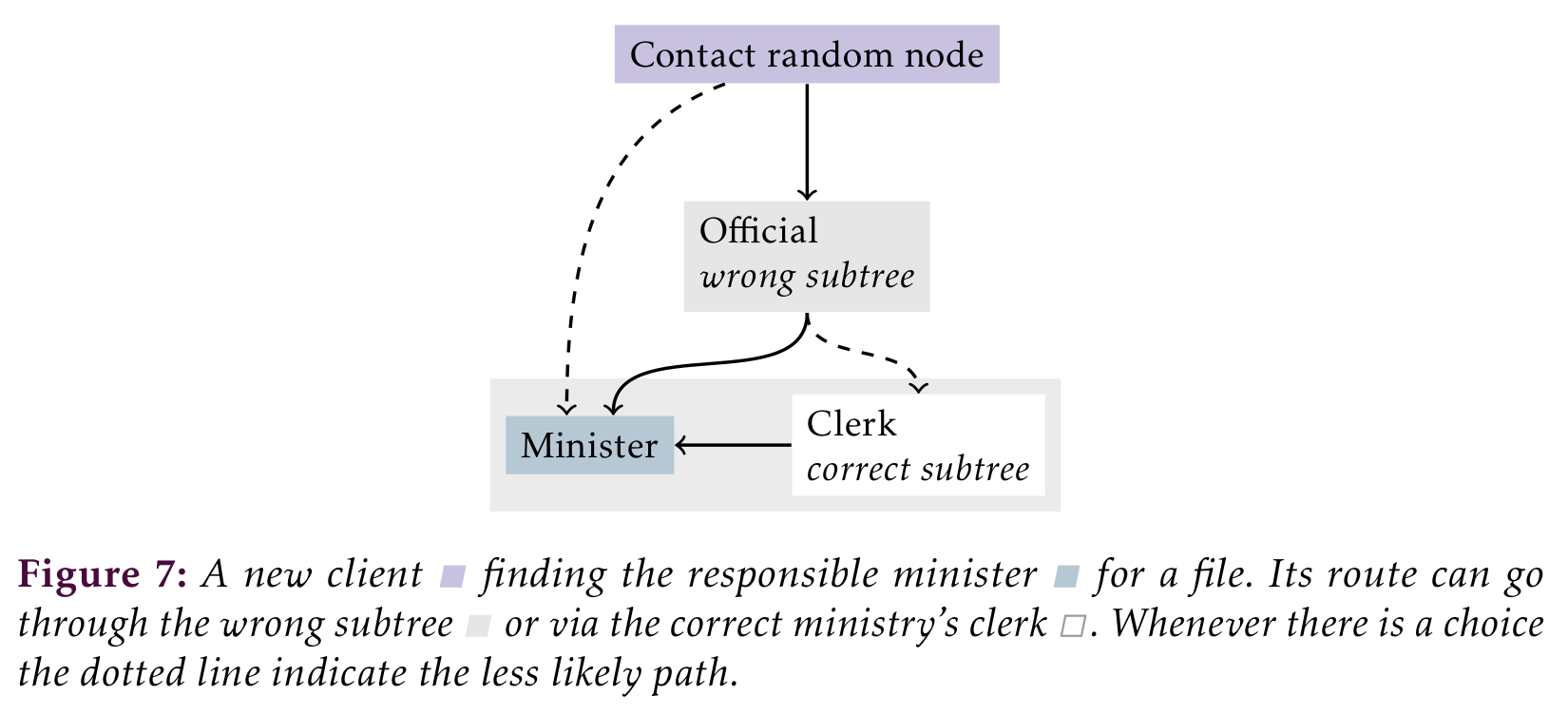
In this section we go over all the operations of the system, while discussing four in greater detail. I also explain how most operations are simpler forms of these four. This section is split in two parts: client requests and coordination by the president. For all requests a client needs to find an official (a minister or clerk) to talk to. If the request modifies the namespace, such as write, create and delete, the client needs to contact the minister. In we see how this works. Since load balancing changes and minister appointments are communicated through Raft each cluster member knows which ministry owns a given subtree. A client can not judge whether the node it got directions from has up to date and correct information. In the rare case the directions where incorrect this means an extra jump through an irrelevant ministry before getting correct information.
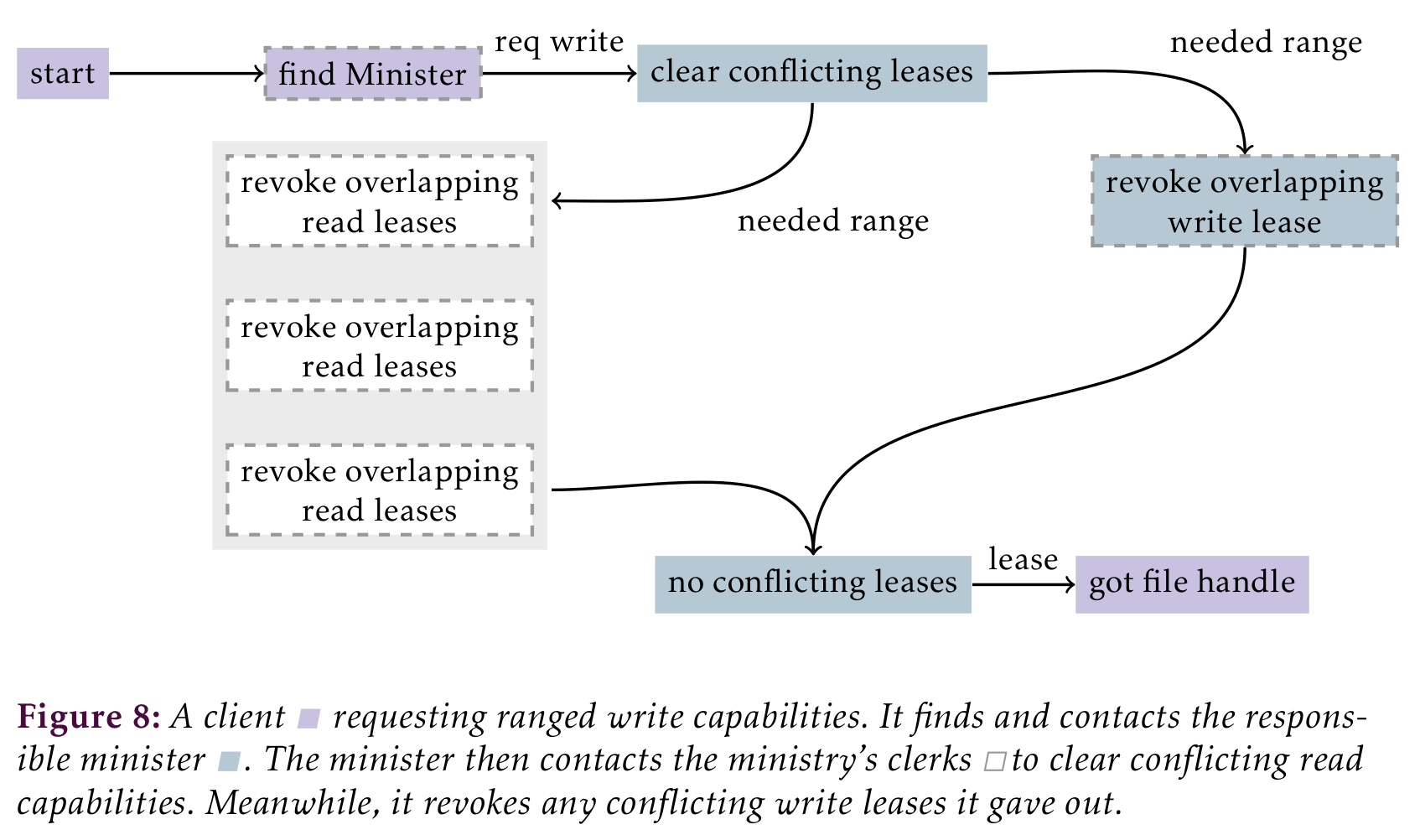
A client needing write-capability on a file contacts the minister. It in turn checks if the lease can be given out and asks its clerks to revoke outstanding read leases that conflict. A read lease conflict when its region overlaps with the region needed for the write capability. If a clerk lost contact with a client it can not revoke the lease and has to wait till the lease expires. The process is illustrated in .
If the client needs read capabilities it sends its requests to a clerk. The clerk checks against the Raft log if the leases would conflict with an outstanding write lease. If no conflict is found the lease is issued and the connection to the client kept active. Keeping an active connection makes it possible to revoke the lease or quickly refresh it.
Most changes to the namespace need simple edits within ministries metadata table. The client sends its request to the minister. The change is performed by adding a command to the pRaft log (see: ). Before committing the change the client gets the log index for the change. If the minister goes down before acknowledging success the client verifies if the change happened using the log index.
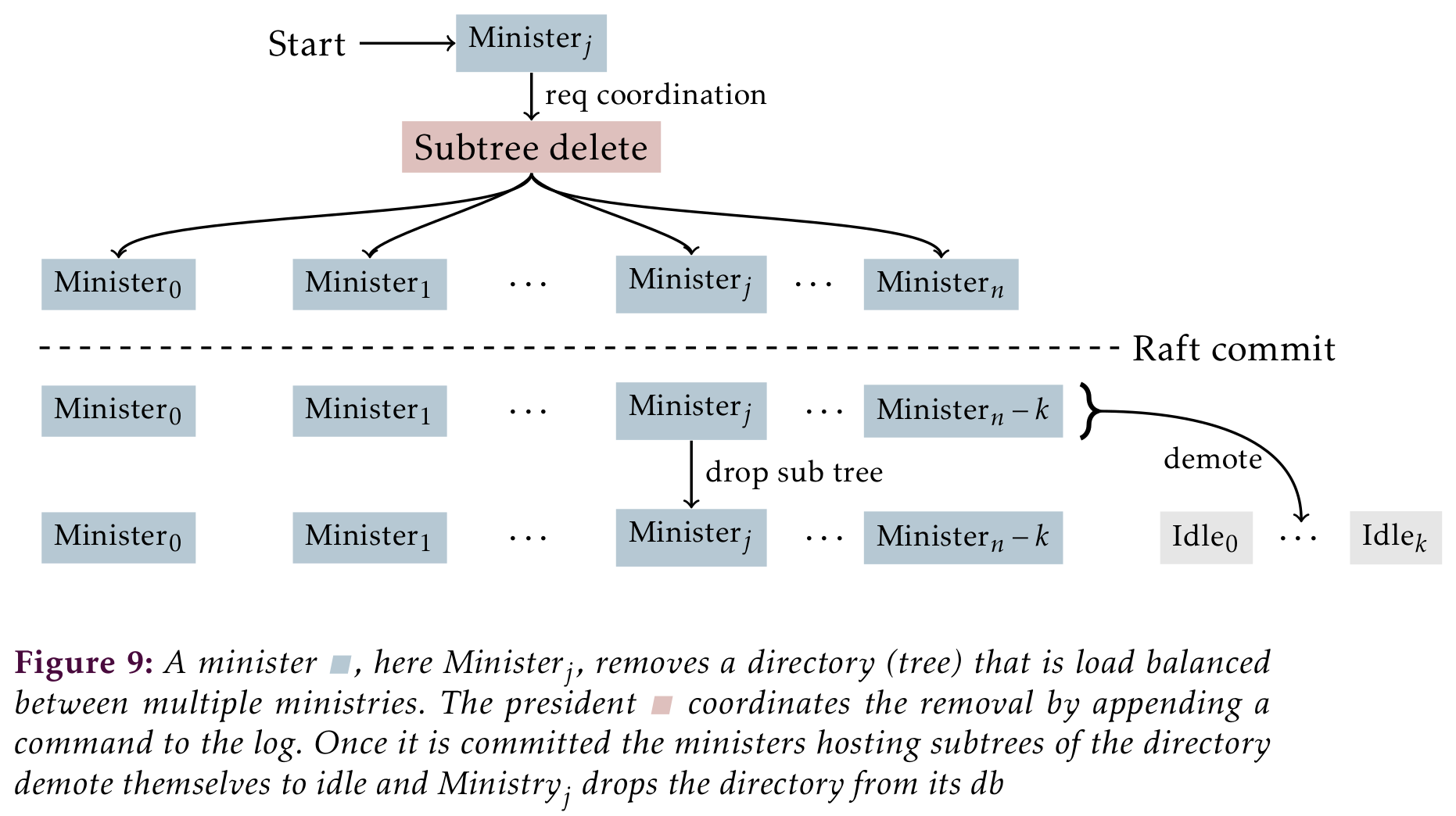
Removing a directory spanning one or more load balanced subtrees needs a little more care. One or more ministers will have to delete their entire subtree. This requires coordination across the entire cluster. The clients remove requests is forwarded by the minster to the president. It in turn appends Subtree Delete to the cluster wide log. The client receives the log index for the command to verify success even if the president goes down. The steps the minister takes are shown in .
Ensuring file system availability is the responsibility of the president. This includes replacing nodes that fail and load balancing. All ministers and clerks periodically send heartbeats to the president. In this design I improve scalability by moving tasks from a central authority (the president) to groups of nodes. Continuing this pattern we could let the ministers monitor their clerks. This is more complex than letting these report directly to the president. However, even reporting directly to the president is not needed, instead I use the TCP ACK to the president's Raft heartbeat. When the president fails to send a Raft heartbeat to a node it decides the node must be failing.
When the president notices a minister has failed it will try to replace it. It queries the ministries clerks to find the ideal candidate for promotion. If it gets a response from less than half the ministry it can not safely replace the minister. At that point it marks the file subtree as down and may retry in the future. A successful replacement is illustrated in .
A clerk going down is handled by the president in one of two ways:
-
There is at least one idle node. The president assigns the idle node to the failing nodes group.
-
There are no idle nodes. The president, through raft, commands a clerk in the group with the lowest load to demote itself. Then the president drops the matter. The clerk wait till its read leases expire and unassigns.
When the groups' minister appends to the groups pRaft log it will notice the replacement misses entries and update it (see ).
From the point of availability a system that is up but drowning in requests might as well be down. To prevent nodes from getting overloaded we actively balance the load between ministries, add and remove them and expand the read capacity of some. A load report contains CPU utilization for each node in the group and the popularity of each bit of metadata split into read and write. The President checks the balance for each report it receives.
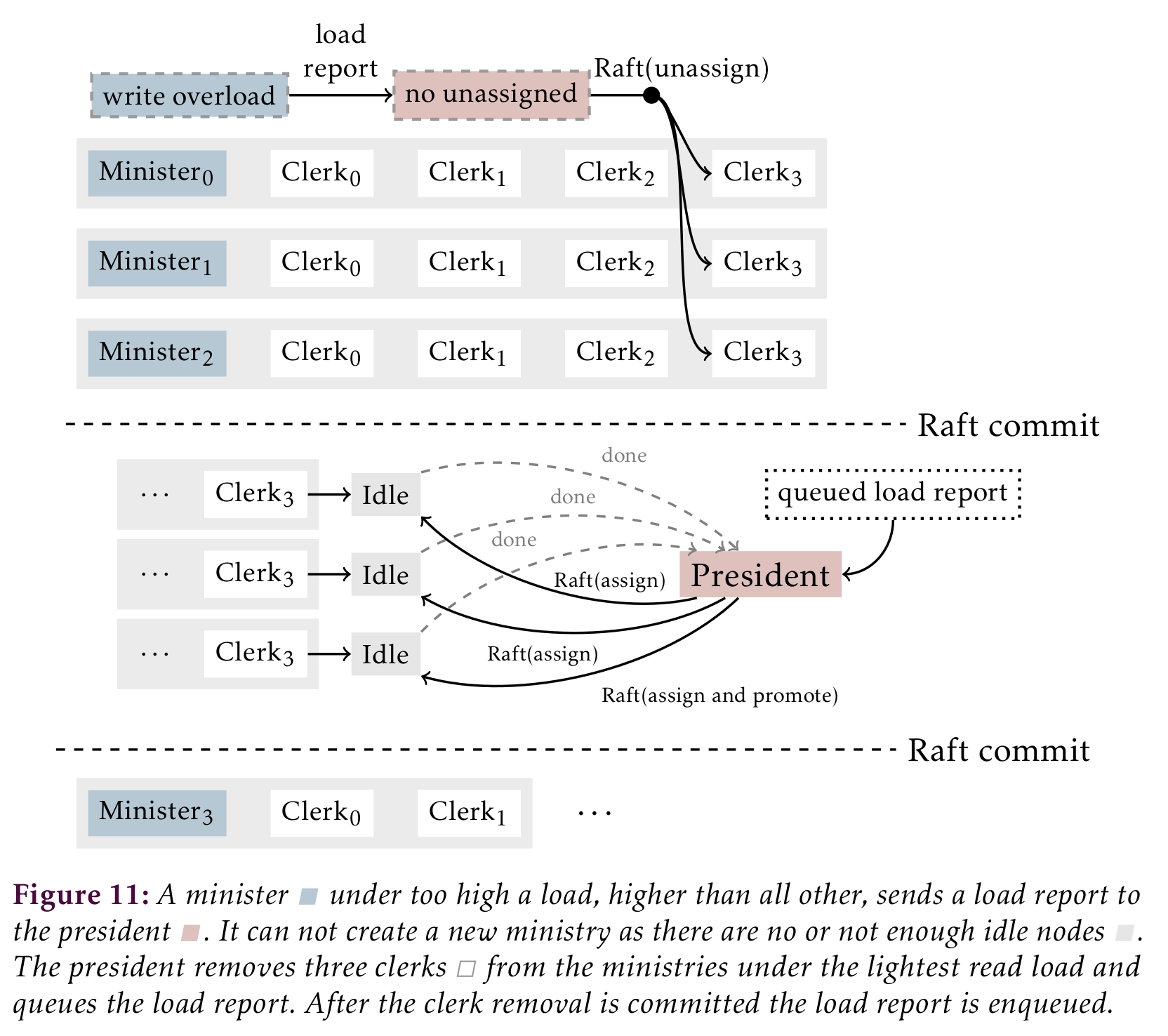
There is a trade-off here: a larger ministry means more clerks for the minister to communicate changes to, slowing down writes. On the other side as the file system is split into more subtrees the chance increases a client will need to contact not one but multiple ministries. Furthermore, to create another ministry we usually have to shrink existing ministries. Growing a ministry can involve removing one to free up clerks. We can model the read and write capacity of a single group as: $$\begin{aligned}
r =& n_\text{c} \
w =& 1 - \sigma*n_\text{c}\end{aligned}$$ Here