- ffmpeg
The following steps are taken from https://replicate.com/blog/run-stable-diffusion-on-m1-mac
- Install Python 3.10 or above and FFmpeg
- Clone this repository (https://github.com/dzluke/Sound-Diffusion)
- Setup and activate a virtual environment
pip install virtualenv
virtualenv venv
source venv/bin/activate
- Install dependencies:
pip install -r requirements.txt
If you're seeing errors like Failed building wheel for onnx you might need to install these packages:
brew install Cmake protobuf rust
- Download pre-trained model at https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
- Download
sd-v1-4.ckpt(~4 GB) on that page. Create a new foldermodels/ldm/stable-diffusion-v1and save the model you downloaded asmodels/ldm/stable-diffusion-v1/model.ckpt
- Download
- Test that it works by running:
python scripts/txt2img.py \
--prompt "a red juicy apple floating in outer space, like a planet" \
--n_samples 1 --n_iter 1 --plms
The generated image will be saved to outputs/txt2img-samples.
- Follow instructions for mac until part 3.
- Set up virtual environment:
pip install virtualenv
python -m venv venv
.\venv\Scripts\activate
-
Install dependencies:
pip install -r requirementswindows.txtNote that assumes the user has CUDA. If your computer does not have a GPU, you will have to reinstall pytorch without it. -
Continue following instructions for mac starting at 5.
To peform Audio-to-Image, use the script audio2img.py. It can be run in the following way:
python audio2img.py --prompt PATH --feature waveform|fft
To perform Audio-to-Video, use the script audio2video.py. It can be run in the following way:
python audio2video.py --path PATH --fps FRAMES_PER_SECOND --strength STRENGTH
There are many other arguments that influence the model, including text, sound representation, and strength of text. The list of key args is as follows:
--path: path to audio that will be visualized (string)
--fps: the frames per second of the resulting video (int). This determines the number of images that are
generated
--strength: a float between 0 and 1 that determines the weight of the previous image compared to the weight of the current prompt. A value of 1.0 "corresponds to full destruction of information in init image." Suggested values: between 0.2 and 0.7.
--ckpt: path to a .ckpt model which will be used to generate images
--textprompt: text prompt for each image. Default to the empty string.
--textpromptend: ending textprompt by the end of the video. Default as the initial textprompt
--textstrength: scales the ratio of text influence vs sound influence. For text to make an influence, value should generally be 200+
--feature: determines how sound is represented, includes waveform, fft, and melspectrogram.
SD = Stable Diffusion
todo:
- update to SD 2.0 https://github.com/Stability-AI/stablediffusion
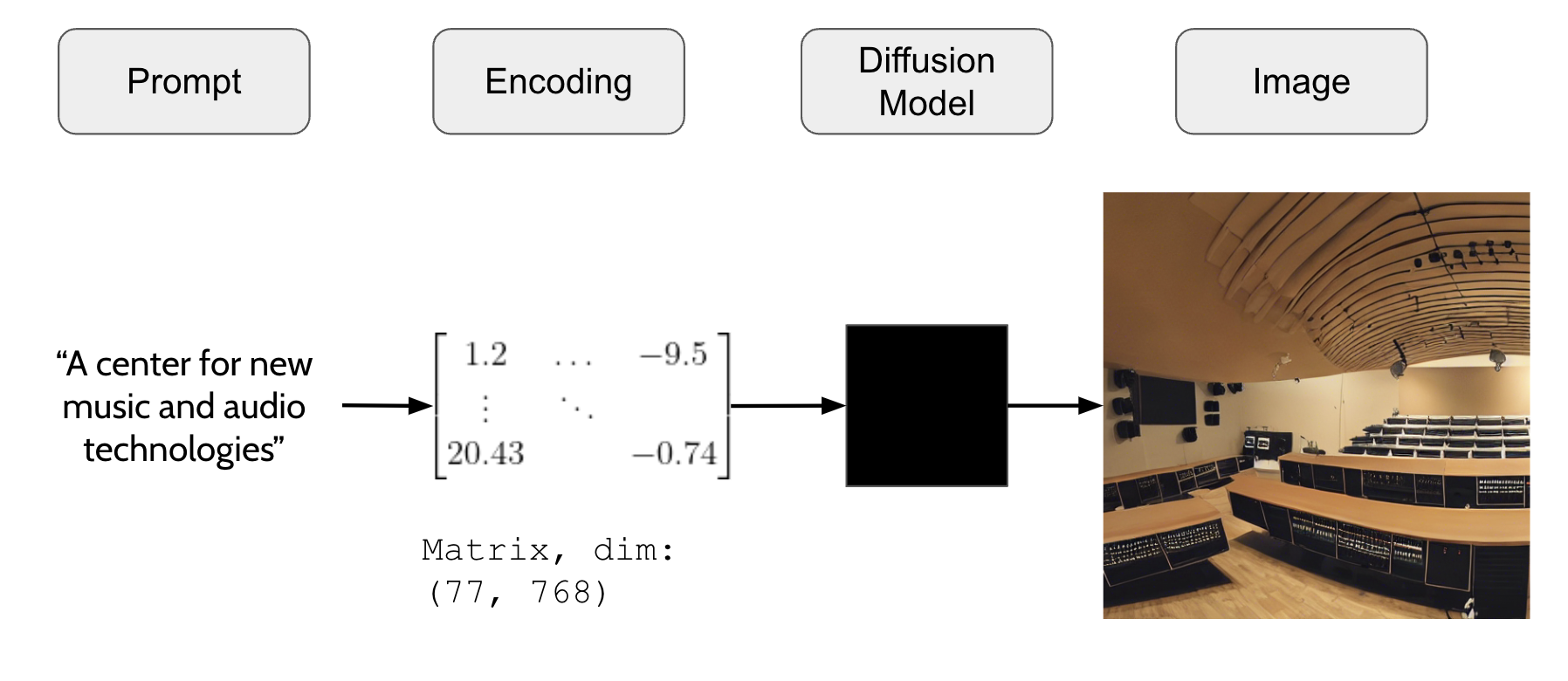
A sound is input to SD and an image is created, essentially visualizing the sound.
SD works by encoding the text prompt as a matrix of dim (77, 768). I believe this is the featurized version of the prompt, but more research is necessary to figure out exactly what the encoding is (is it tokenization?). This matrix is what is passed to the model, and the model outputs an image.
A first look showed that the data in the matrix are floats in the range [-28.0912, 33.0632].
My first approach was to use a waveform (sample) representation of audio, and fill the feature matrix with the sample values of the audio. The first 768 samples of the audio become the first row of the feature matrix, the next 768 samples are the second row, and so on. At a sampling rate of 44.1 kHz, you can fit about 1.5 seconds on audio into the matrix. The sample values are NOT scaled, so they exist in the range [-1, 1].
examples:
| Audio | Example images |
|---|---|
| archeos-bell |    |
| bass_clarinet |     |
| 1 Hz sine |  |
| 10 Hz sine |  |
| 100 Hz sine |    |
Due to the unstable nature of the waveform representation, I tried computing the STFT of the input sound and passing that as the input to SD. In order to make the dimensions of the STFT matrix fit the dimensions expected by SD, I had to use a number of frequency bins equal to 768. Only the real part of the STFT is kept.
# stft makes an np array of size (1 + n_fft / 2, 1 + audio.size // hop_length)
n_fft = 1534
hop_length = y.size // 77 + 1
stft = librosa.stft(y, n_fft=n_fft, hop_length=hop_length)
stft = np.abs(stft)
Using the FFT representation provided images that were much more consistent (self-similar). For a given audio input, the images generated were much more similar to each other compared to the waveform representation. Interestingly, different audio inputs also gave similar image outputs.
examples:
| Audio | Example images |
|---|---|
| archeos-bell |   |
| bass_clarinet |   |
| 1 Hz sine |   |
| 10 Hz sine |   |
| 100 Hz sine |   |
Instead of creating a single image for a sound, the goal is to create a series of images that before frames in a video, creating a visualization of the temporal evolution of the sound. This is done by taking the STFT of the input sound and cutting it in time into successive slices, which are then passed to SD to be visualized in the same method as Experiment 1. The FFT (STFT) representation is chosen over the waveform representation because of its consistency and stability.
First the user species the frames per second (FPS) of the video, which defines the number of total images that will be created. Then an STFT is created with the following dimensions: (768, NUM_FRAMES * 77). This matrix is sliced into sub-matrices of size (768, 77) and each one is passed to SD to create the successive frames.
Here the slices of the STFT are each passed to text2img, which takes in a matrix of size (77, 768) and creates a single image. The results have varying consistency. For example, the visualization of synth_chords.wav mimics the spectral envelope of the sounds, it starts with a noisy image at the attack and slowly smooths out to a solid blue color as the sound decays. However, for windchimes.wav the frames created vary dramatically, sometimes showing images of people or nature, interspersed with abstract colors. There is little continuity in the visualization.
SD is able to create images from prompts and start the generation with a supplied image.
The idea is that the prompt is applied to the given image, and the resulting image has some qualities of the supplied
image. In this test, each frame that is generated is conditioned on the previous frame, with the hopes that a more continuous, smoother
visualization will be created. For the creation of frame i, the STFT slice i and the image from frame i-1 is
passed to SD. The first frame is created in the same way as Test 1, the prompt is passed to text2img. All subsequent
frames are generated using img2img.
The strength parameter determines the influence of the init image in the final image. A value of 1.0 "corresponds to
full destruction of information in init image."
- prompt interpolation: SD generates frames that are interpolations between two points in time. Linear interpolation is done with np.linspace or similar. For this to work, there must be same space in between successive STFT slices where the interpolation can happen. How do you do this without leaving out some audio data?
- have some overlap between successive frames, so some of the STFT data from frame
iis included in framei+1. This actually won't perform as expected because it just changes the beginning of the encoding - The amplitude of the sound affects the encoding/prompt
- Scale the encodings/prompts to the range that SD expects
- User can provide init image
- How does setting a seed value (or not) affect the images?
- What if the input is a combination of a text prompt and audio data? Sum the encodings?
Resources for prompt interpolation:
- repo with iPython notebook for interpolation: https://github.com/schmidtdominik/stablediffusion-interpolation-tools
- repo with code to make a video inteprolating between two prompts: https://github.com/nateraw/stable-diffusion-videos
- using KerasCV library: https://keras.io/examples/generative/random_walks_with_stable_diffusion/
examples of animation with SD:
- https://www.instagram.com/p/Ci7Z8DZDMTG/
- Xander Steenbrugge "Voyage through Time": https://twitter.com/xsteenbrugge/status/1558508866463219712, https://www.youtube.com/watch?v=Bo3VZCjDhGI&feature=youtu.be&ab_channel=NeuralSynesthesia
OP-Z Real time sound to image with stable diffusion: https://modemworks.com/projects/op-z-stable-diffusion/