Useless mutants (eg., equivalent and duplicate) contribute to increasing costs of the mutation testing. An equivalent mutant is a mutant that has the same behavior as the original program. This way, this mutant is useless. A duplicate mutant is a mutant that has the same behavior as another one. Thus, one of them is useless. Previous research has focused mainly on detecting useless mutants only after they are generated and compiled. The few solutions that try to prevent the mutant from being generated either do not provide practical effectiveness in their outcome, are specialized to domain-specific mutants, depend on expensive resources, or work with second-order mutants. In previous work, we proposed improving the transformation rules embedded in the mutation operators in order to avoid useless mutants. This work extends our previous findings in several ways. We present i-rule, a notation to avoid useless mutants. We define an i-rule as a triple (term, transformations, constraints) and differentiate i-rules to avoid equivalent (e-rule) and to avoid duplicate mutants (d-rule). Also, we present a strategy to help mutation tool developers find out occurrence patterns that lead to new i-rules. In our previous conference paper, we instantiated the strategy with programs automatically generated by the JDolly program generator, which lead us to discover 48 i-rules for three common mutation testing tools for Java (MuJava, Major, and Pit). In this article, we instantiate the strategy with manually-written Java programs, which lead us to find out 51 new i-rules for the same mutation tools. To evaluate the effectiveness of the i-rules on reducing costs, we implement 32 of them in the MuJava tool and execute with classes of well-known projects such as ant, bcel, and commons-lang. The results show we reduced the number of mutants by almost 20% on average and saved time to generate the mutants, thus demonstrating the potential of our approach for reducing mutation costs.
Leo Fernandes - leonardo.oliveira@ifal.edu.br Informatics Center, Federal University of Pernambuco---Recife, PE, Brazil Informatics Coordination, Federal Institute of Alagoas---Maceió, AL, Brazil
Márcio Ribeiro - marcio@ic.ufal.br Computing Institute, Federal University of Alagoas---Maceió, AL, Brazil
Pedro Pinheiro - pmop@ic.ufal.br Computing Institute, Federal University of Alagoas---Maceió, AL, Brazil
Fabiano C. Ferrari - fcferrari@ufscar.br Computing Department, Federal University of São Carlos, SP, Brazil
Rohit Gheyi - rohit@dsc.ufcg.edu.br Computing Departament, Federal University of Campina Grande---Campina Grande, PB, Brazil
André Santos - alms@cin.ufpe.br Informatics Center, Federal University of Pernambuco---Recife, PE, Brazil
We created a tool called MuJava-AUM (AUM stands for Avoiding Useless Mutants). This tool ... at https://github.com/easy-software-ufal/muJava-AUM.
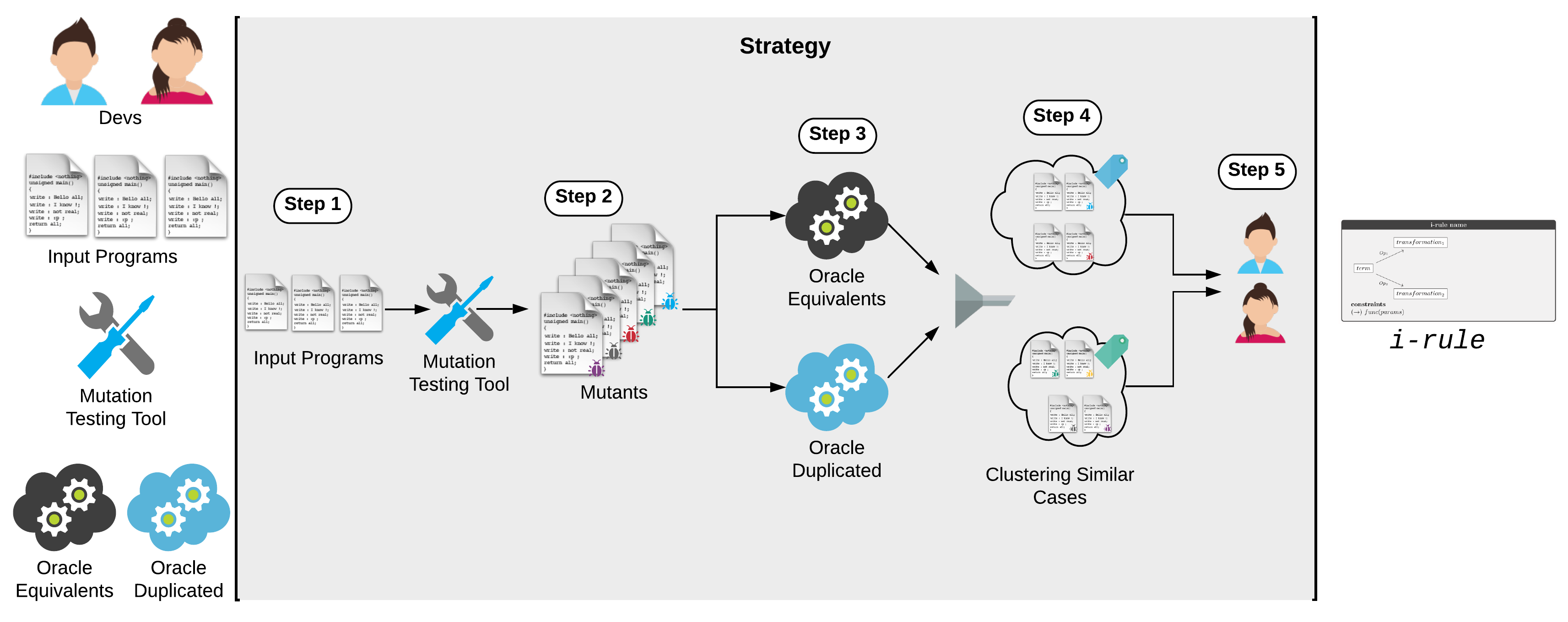
Figure above summarizes the strategy process.
- Step 1. We begin by providing a set of programs. Any program(s) could be used, however, we recommend that these programs be preferably small, because we will parse them manually to extract the i-rules.
- Step2. For each program, a mutation testing tool generates mutants. We recommend enabling all mutation operators allowing the generation of the full set of mutants.
- Step 3. Oracles must examine the original program and its mutants to identify potential equivalent and duplicate candidates. Any solution that detects or suggests the equivalent and duplicate mutants can be used.
- Step 4. A program gathers the results from Step~3 and cluster the candidates according to the mutation operators and transformations applied, and sort these groups according to the number of candidates. For instance, if the strategy detects many candidates of duplicate mutants with transformations of the ROR (Relational Operator Replacement) and COI (Conditional Operator Insertion) operators, the program cluster these mutants candidates and hints this group as a priority for manual analysis.
- Step 5. We manually analyze the clusters with more candidates to extract the i-rules. We reason that clusters with more candidates may indicate an occurrence pattern that leads to the identification of an e-rule or d-rule. To perform the manual analysis, we perceive all candidates in a cluster and if identified a pattern, we perform a manual slicing. This means we create a simple program that isolates the components of the program that are concerned with the mutation. We then execute tests (manually or automatically generated) against this program to bring up behavioral changes. If no behavioral changes are detected, we work to extract the i-rule that will prevent this useless mutant from occurring again.
JDolly programs
| Project | Description |
|---|---|
| Leakcanary | Leakcanary is a memory leak detection library for Android. |
| Guava | Guava is a set of core Java libraries that includes new collection types, graph library, functional types, an in-memory cache, etc. |
| ElasticSearch | Elasticsearch is a distributed RESTful search engine built for the cloud. |
| Incubator-Dubbo | Apache Dubbo (incubating) is a high-performance, Java based open source RPC framework. |
| RxJava | RxJava is a library for composing asynchronous and event-based programs using observable sequences for the Java VM. |
| SpringBoot | Spring Boot facilitates the creation of stand-alone, production-grade applications and services with absolute minimum fuss. |
| Spring Framework | Spring Framework provides a comprehensive programming and configuration model for modern Java-based enterprise applications. |
| Retrofit | Retrofit is a type-safe HTTP client for Android and Java. |
| The Benchmarks Game | The benchmarks game is a project for comparing toy benchmark programs implemented in different programming languages |
Developer-writen programs:
At the end of the two rounds, we identified 30 _e-rules and 69 _d-rules_ in all three mutation testing tools, with the following distribution:
- MuJava: 16 _e-rules_ and 36 _d-rules_
- Major: 9 _e-rules_ and 14 _d-rules_
- Pit: 5 _e-rules_ and 19 _d-rules_
Our results point out that there are possibilities to improve transformations to avoid useless mutants in all tools.
This document list all the i-rules discovered after executing the strategy.

| Project | Version | CLOC |
|---|---|---|
| joda-time | 2.10.1 | 28,790 |
| commons-math | 3.6.1 | 100,364 |
| commons-lang | 3.6 | 27,267 |
| h2 | 1.4.199 | 134,234 |
| javassist | 3.20 | 35,249 |
Considering a whole set of mutants generated by the original MuJava implementation, our _i-rules_ avoided the generation of 19.79% of them, all identified as useless mutants.
Out of these, 16.81% are duplicate mutants, and 2.98% are equivalent to the original program.
This way, we avoid the cost of generation, compilation, and execution of the tests on these mutants.
In addition, by eliminating equivalent ones, we also avoid the cost of manually analyzing these mutants.
Regarding the __e-rules__ related to equivalent mutants, we managed to avoid 4,030 mutants.
The AOIS-01 (MuJava) _e-rule_, itself, was responsible for the vast majority of avoided equivalent mutants.
From the 9 implemented _e-rules_, five were triggered successfully at least once,
what means that 4 _e-rules_ have not been applied.
Regarding the applied _d-rules_, they avoided 22,693 mutants.
Six _d-rules_ were responsible for approximately 89% of the avoided duplicate mutants.
From the 23 _d-rules_ implemented, 19 were triggered successfully at least once, whereas and 4 _d-rules_ have not been applied.
We also found that some _i-rules_ are challenging to detect by *TCE*, which shows that we can use both solutions in conjunction to reduce even more the number of useless mutants.
Note that these results links to the set of programs evaluated,
as well as to the implementation of the mutation operators in the MuJava-AUM mutation tool.
Although our _i-rules_ introduce an additional overhead, the payoff amount is 15% on average.
Because we generate and compile fewer mutants, we have fewer I/O operations.
These operations are more expensive than executing our _i-rules_.
Having trouble with Pages? Check out our documentation or contact support and we’ll help you sort it out.