A pre-compiled Soccer-Twos environment with multi-agent Gym-compatible wrappers and a human-friendly visualizer. Built on top of Unity ML Agents to be used as final assignment for the Reinforcement Learning Minicourse at CEIA / Deep Learning Brazil.
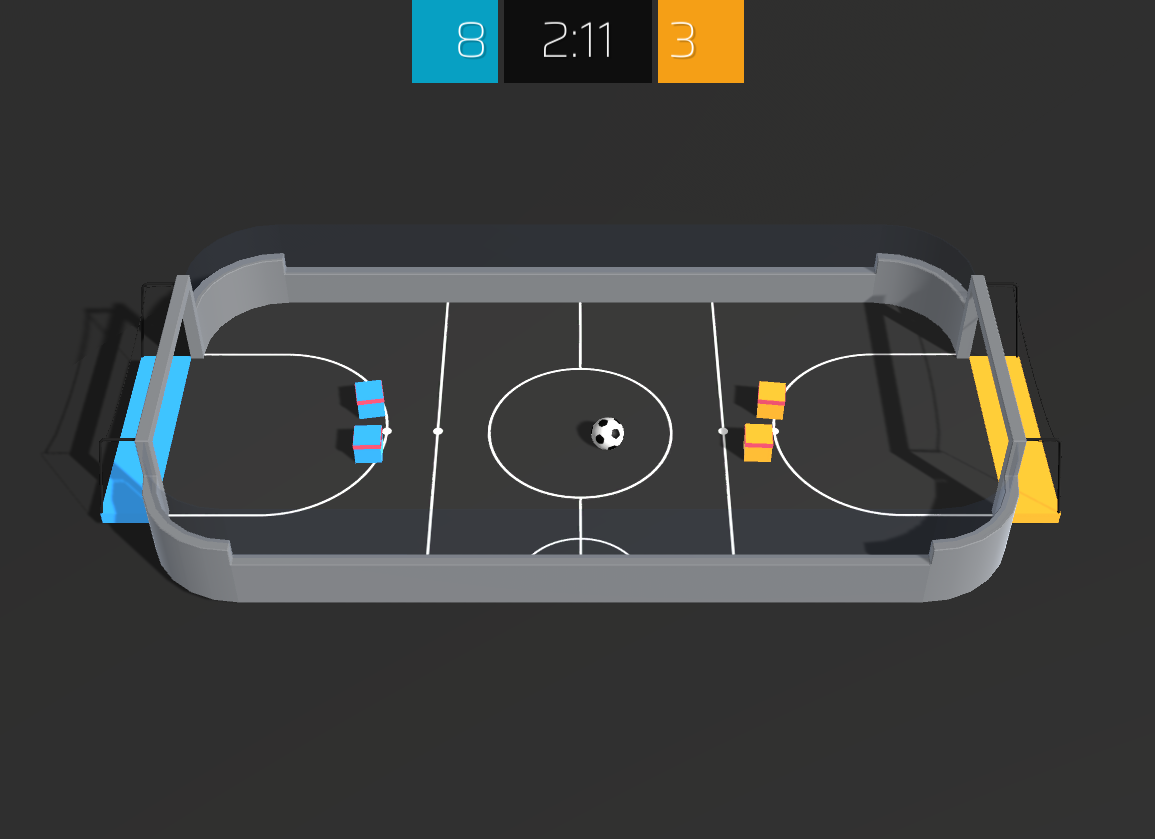
Pre-compiled versions of this environment are available for Linux, Windows and MacOS (x86, 64 bits). The source code for this environment is available here.
See requirements.txt.
Import this package and instantiate the environment:
import soccer_twos
env = soccer_twos.make()
The make method accepts several options:
| Option | Description |
|---|---|
render |
Whether to render the environment. Defaults to False. |
watch |
Whether to run an audience-friendly version the provided Soccer-Twos environment. Forces render to True, time_scale to 1 and quality_level to 5. Has no effect when env_path is set. Defaults to False. |
variation |
A soccer env variation in EnvType. Defaults to EnvType.multiagent_player |
time_scale |
The time scale to use for the environment. This should be less than 100x for better simulation accuracy. Defaults to 20x realtime. |
quality_level |
The quality level to use when rendering the environment. Ranges between 0 (lowest) and 5 (highest). Defaults to 0. |
base_port |
The base port to use to communicate with the environment. Defaults to 50039. |
worker_id |
Used as base port shift to avoid communication conflicts. Defaults to 0. |
env_path |
The path to the environment executable. Overrides watch. Defaults to the provided Soccer-Twos environment. |
flatten_branched |
If True, turn branched discrete action spaces into a Discrete space rather than MultiDiscrete. Defaults to False. |
opponent_policy |
The policy to use for the opponent when variation==team_vs_policy. Defaults to a random agent. |
single_player |
Whether to let the agent control a single player, while the other stays still. Only works when variation==team_vs_policy. Defaults to False. |
The created env exposes a basic Gym interface.
Namely, the methods reset(), step(action: Dict[int, np.ndarray]) and close() are available.
The render() method has currently no effect and soccer_twos.make(render=True) should be used instead.
The step() method returns extra information about the player and the ball in the last tuple element.
This information may be used to build custom reward functions if needed.
We expose an RLLib-compatible multiagent interface.
This means, for example, that action should be a dict where keys are integers in {0, 1, 2, 3} corresponding to each agent.
Additionally, values should be single actions shaped like env.action_space.shape.
Observations and rewards follow the same structure. Dones are only set for the key __all__, which means "all agents".
Agents 0 and 1 correspond to the blue team and agents 2 and 3 correspond to the orange team.
Here's a full example:
import soccer_twos
env = soccer_twos.make(render=True)
print("Observation Space: ", env.observation_space.shape)
print("Action Space: ", env.action_space.shape)
team0_reward = 0
team1_reward = 0
while True:
obs, reward, done, info = env.step(
{
0: env.action_space.sample(),
1: env.action_space.sample(),
2: env.action_space.sample(),
3: env.action_space.sample(),
}
)
team0_reward += reward[0] + reward[1]
team1_reward += reward[2] + reward[3]
if done["__all__"]:
print("Total Reward: ", team0_reward, " x ", team1_reward)
team0_reward = 0
team1_reward = 0
env.reset()
More information about the environment including reward functions and observation spaces can be found here.
You may implement your own rollout script using soccer_twos.make(watch=True) or use our CLI tool.
To rollout via CLI, you must create an implementation (subclass) of soccer_twos.AgentInterface and run python -m soccer_twos.watch -m agent_module.
This will run a human-friendly version of the environment, where your agent will play against itself.
You may instead run python -m soccer_twos.watch -m1 agent_module -m2 opponent_module to play against a different opponent.