A Tensorflow implementation of batch renormalization, first introduced by Sergey Ioffe.
Paper: Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models, Sergey Ioffe https://arxiv.org/abs/1702.03275
GitHub repository: https://github.com/eigenfoo/batch-renorm
The goal of this project is to reproduce the following figure from the paper:
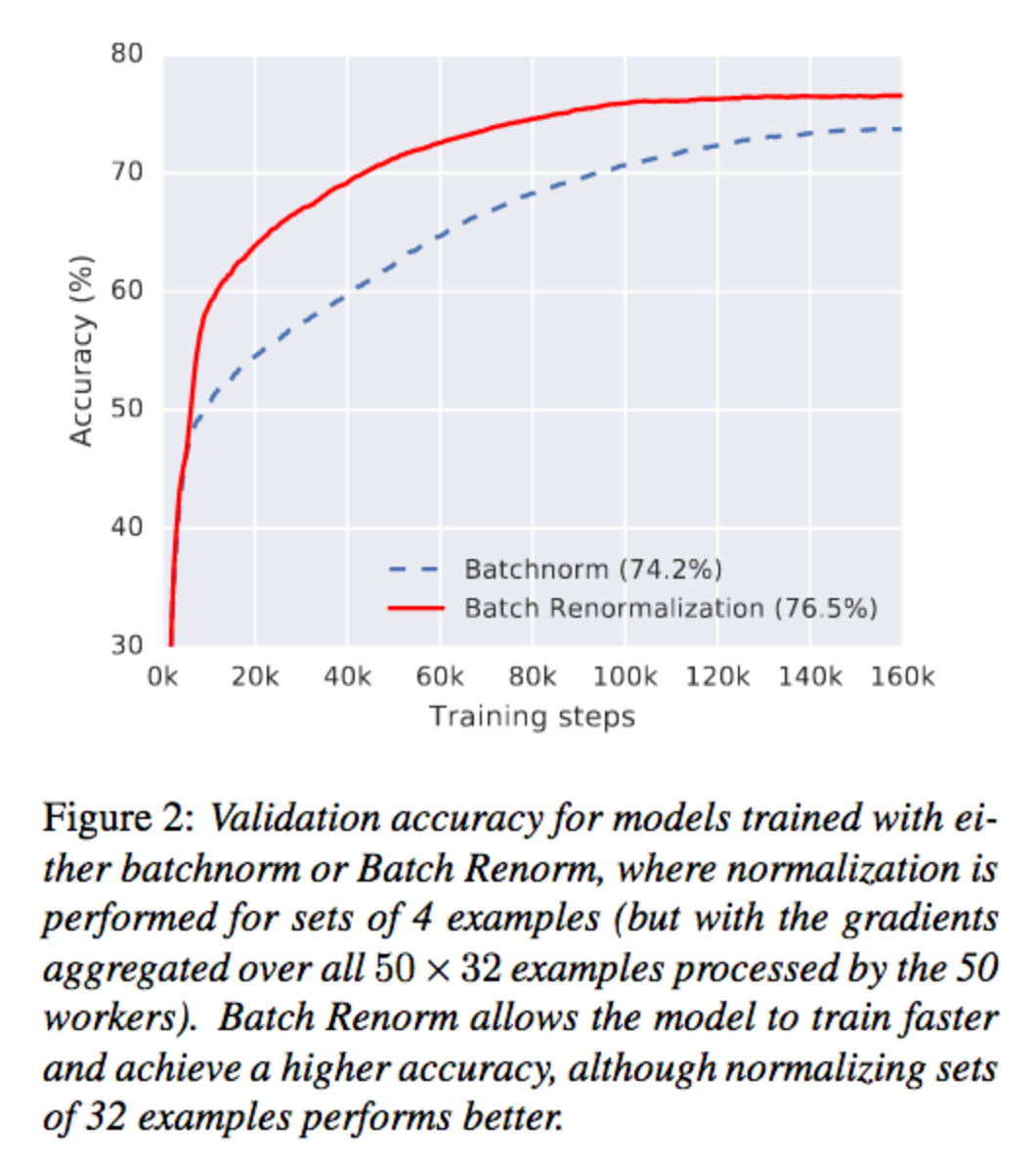
Below is our reproduction:
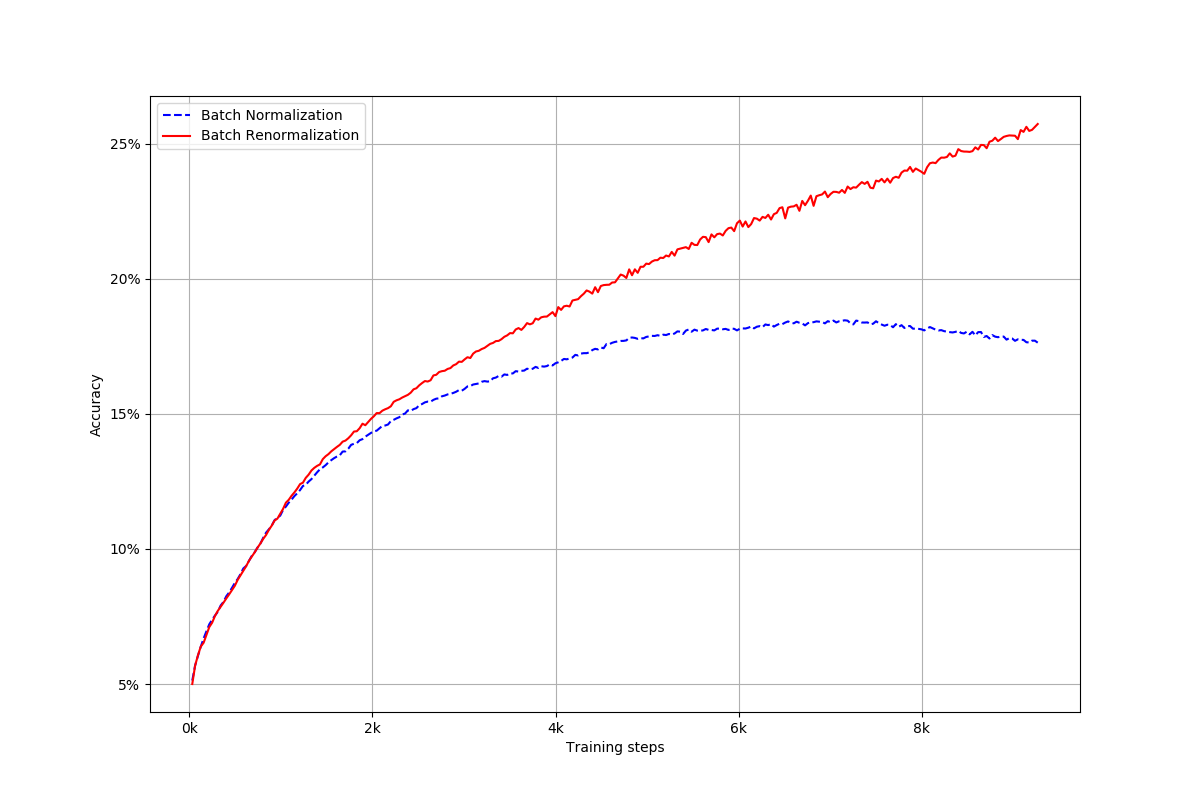
There were a few things that we did differently from the paper:
- We used the CIFAR-100 dataset, instead of the ImageNet dataset.
- We used a plain convolutional network, instead of the Inception-v3 architecture.
- We used the Adam optimizer, instead of the RMSProp optimizer.
- We split minibatches into 800 microbatches of 2 examples each, instead of 400 microbatches of 4 examples each. Note that each minibatch still consists of 1600 examples.
- We trained for a mere 8k training updates, instead of 160k training updates.
- We ran the training 5 separate times, and averaged the learning curves from all runs. This was not explicitly stated in the paper.
The reproduced results do not exactly mirror the paper's results: for instance, the learning curves for batch norm and batch renorm do not converge to the same value, and the learning curve for batch norm even appears to be curving down towards the end of training.
We suspect that these discrepancies are due to two factors:
- Not training for long enough time (8k training steps is nothing compared to 160k), and
- Using a different architecture/dataset to reproduce the same results. While the behavior should still be the same, it may be the case that certain hyperparameters are ill-chosen.