this place is where i take notes from book "algs4"
- 1.1 下压(LIFO)栈(能够动态调整数组大小的实现)
- 1.2 下压堆栈(链表实现)
- 1.3 先进先出队列
- 1.4 背包
- 1.5 union-find的实现
| 算法 | 构造函数 | union() | find() |
|---|---|---|---|
| quick-find算法 | N | N | 1 |
| quick-union算法 | N | 树的高度 | 树的高度 |
| 加权quick-union算法 | N | lgN | lgN |
| 算法 | 是否稳定 | 是否为原地排序 | 时间复杂度 | 空间复杂度 | 备注 |
|---|---|---|---|---|---|
| 选择排序 | 否 | 是 | N^2 | 1 | |
| 插入排序 | 是 | 是 | 介于N和N^2之间 | 1 | 取决于输入元素度排列情况 |
| 希尔排序 | 否 | 是 | NlogN? or N^6/5 | 1 | |
| 快速排序 | 否 | 是 | NlogN | lgN | 运行效率由概率提供保证 |
| 三向快速排序 | 否 | 是 | 介于N和NlogN之间 | lgN | 运行效率有概率保证,同时也取决于输入元素的分布情况 |
| 归并排序 | 是 | 否 | NlogN | N | |
| 堆排序 | 否 | 是 | NlogN | 1 |
- 3.1 顺序查找(基于无序链表)
- 3.2 二分查找(基于有序数组)
- 3.3 基于二叉查找树的符号表
- 3.4 基于红黑树的符号表
- 3.5 基于拉链法的散列表
- 3.6 基于线性探测的散列表
| 算法(数据结构) | 最坏情况下的运行时间的增长数量级(N次插入之后)(查找:插入) | 平均情况下的运行时间的增长数量级(N次随机插入之后)(查找命中:插入) | 关键接口 | 内存使用(字节) |
|---|---|---|---|---|
| 顺序查找(无序链表) | N:N | N/2:N | equals() | 48N |
| 二分查找(有序数组) | lgN:N | lgN:N/2 | compareTo() | 16N |
| 二叉树查找(二叉查找树) | N:N | 1.39lgN:1.39lgN | compareTo() | 64N |
| 2-3树查找(红黑树) | 2lgN:2lgN | 1.00lgN:1.00lgN | compareTo() | 64N |
| 拉链法(链表数组) | <lgN:<lgN | N/(2M):N/M | equals() hashCode() | 48N+32M |
| 线性探测法(并行数组) | clgN:clgN | <1.5:<2.5 | equals() hashCode() | 在32N和128N之间 |
- 4.1 深度优先搜索(DFS)查找图中的路径
- 4.2 广度优先搜索(BFS)查找图中的路径
- 4.3 使用深度优先搜索找出图中的所有连通分量
| 问题 | 解决方法 |
|---|---|
| 单点连通性 | DepthFirstSearch |
| 单点路径 | DepthFirstPaths |
| 单点最短路径 | BreadthFirstPaths |
| 连通性 | CC |
| 检测环 | Cycle |
| 双色问题(图的二分性) | TwoColor |
- 4.4 有向图的可达性
- 4.5 拓扑排序
- 4.6 计算强连通分量的Kosaraju算法
| 问题 | 解决方案 |
|---|---|
| 单点和多点的可达性 | DirectedDFS |
| 单点有向路径 | DepthFirstDirectedPaths |
| 单点最短有向路径 | BreadthFirstDirectedPaths |
| 有向环检测 | DirectedCycle |
| 深度优先的顶点排序 | DepthFirstOrder |
| 优先级限制下的调度问题 | Topological |
| 拓扑排序 | Topological |
| 强连通性 | KosarajuSharirSCC |
| 顶点对的可达性 | TransitiveClosure |
- 4.7 最小生成树的Prim算法(贪心算法)
- 4.8 最小生成树的Kruskal算法
- 4.9 最短路径的Dijkstra算法
- 4.10 无环加权有向图的最短路径算法
- 4.11 基于队列的Bellman-Ford算法
| 算法 | 局限 | 路径长度的比较次数(增长的数量级)一般情况:最坏情况 | 所需空间 | 优势 |
|---|---|---|---|---|
| Dijkstra算法(即时版本) | 边的权重必须为正 | ElogV:ElogV | V | 最坏情况下仍有较好的性能 |
| 无环加权有向图的最短路径算法(拓扑排序) | 只适合用于无环加权有向图 | E+V:E+V | V | 是无环图中的最优算法 |
| 基于队列的Bellman-Ford算法 | 不能存在负权重环 | E+V:VE | V | 适用领域广泛 |
- 5.1 低位优先的字符串排序
- 5.2 高位优先的字符串排序
- 5.3 三向字符串快速排序
| 算法 | 是否稳定 | 原地排序 | 在将基于大小为R的字母表的N个字符串排序的过程中调用charAt()方法次数的增长数量级(平均长度为w,最大长度为W)运行时间:额外空间 | 优势领域 |
|---|---|---|---|---|
| 字符串的插入排序 | 是 | 是 | N到N^2之间:1 | 小数组或者是已经有序的数组 |
| 快速排序 | 否 | 是 | Nlog2N:logN | 通用排序算法,特别适合用于空间不足的情况 |
| 归并排序 | 是 | 否 | Nlog2N:N | 稳定的通用排序算法 |
| 三向快速排序 | 否 | 是 | N到NlogN之间:logN | 大量重复键 |
| 低位优先的字符串排序 | 是 | 否 | NW:N | 较短的定长字符串 |
| 高位优先的字符串排序 | 是 | 否 | N到Nw之间:N+WR | 随机字符串 |
| 三向字符串快速排序 | 否 | 是 | N到Nw之间:W+logN | 通用排序算法,特别适合用于含有较长前缀的字符串 |
- 5.4 基于单词查找树的符号表
- 5.5 基于三向单词查找树的符号表
| 算法(数据结构) | 处理由大小为R的字母表构造的N个字符串(平均长度为w)的增长数量级,未命中查找检查的字符数量:内存使用 | 优点 |
|---|---|---|
| 二叉树查找(BST) | c1(lgN)^2:64N | 适用于随机排列的键 |
| 2-3树查找(红黑树) | c2lgN)^2:64N | 有性能保证 |
| 线性探测法(并行数组) | w:32N~128N | 内置类型缓存散列值 |
| 字典树查找(R向单词查找树) | logRN:(8R+56)N~(8R+56)Nw | 适用于较短的键和较小的字母表 |
| 字典树查找(三向单词查找树) | 1.39lgN:64N~64Nw | 适用于非随机的键 |
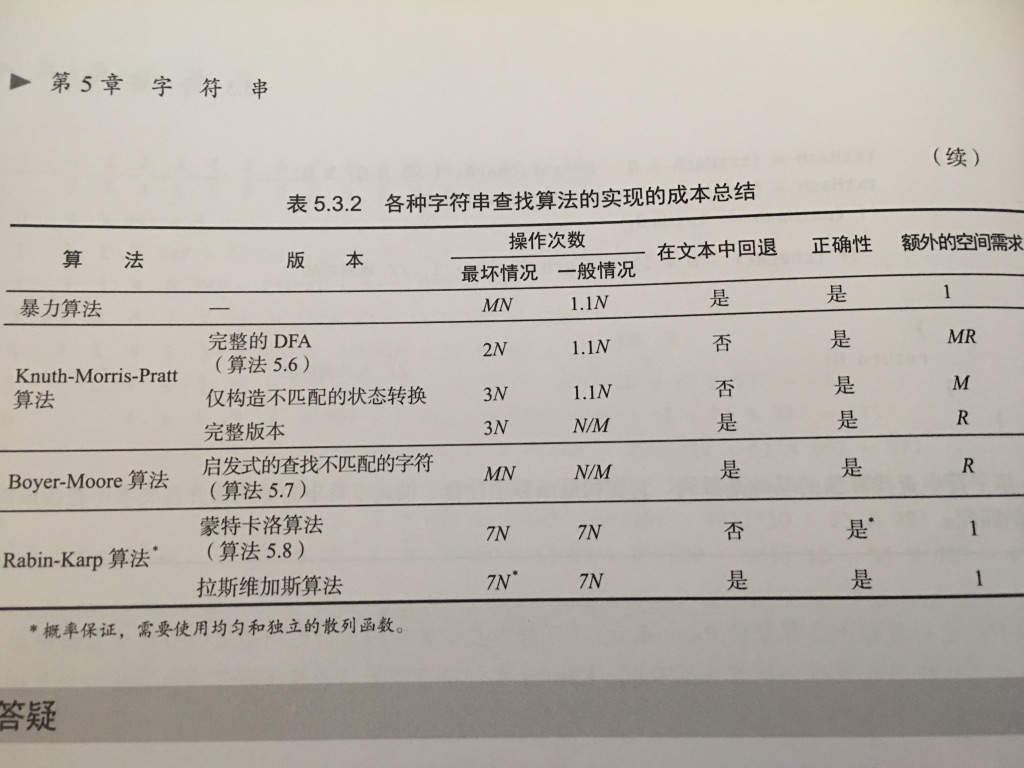
- 5.6 Knuth-Morris-Pratt字符串查找算法
- 5.7 Boyer-Moore字符串匹配算法(启发式地处理不匹配的字符)
- 5.8 Rabin-Karp指纹字符串查找算法(拉斯维加斯,书上是蒙特卡洛)