Parse Apache2 logs to create statistics

- Overview
- Installation and execution
- Usage
- How to configure
- How to update
- Logs
- Statistics
- View statistics
- Extra features
- Final considerations
- Contributions
Craplog is a tool that takes Apache2 logs in their default form, parses them and creates simple statistics.
Welcome to the command line version
Searching for something different? Try the other versions of CRAPLOG.
None
-
Download and un-archive this repo
orgit clone https://github.com/elB4RTO/craplog-CLI.git
-
Open a terminal inside "craplog-CLI-main/"
orcd craplog-CLI/
-
Run craplog using python's environment:
python3 craplog/craplog.py --help
-
Download and un-archive this repo
orgit clone https://github.com/elB4RTO/craplog-CLI.git
-
Open a terminal inside "craplog-CLI-main"
orcd craplog-CLI/
-
Run the installation script:
chmod +x ./install.sh && ./install.sh
-
You can now run craplog from terminal, as any other application (you don't need to be in craplog's folder):
craplog --help
craplog [TOOL] {[OPTION] [ARGUMENT]}
| Tool | Description |
|---|---|
| log | Craplog: make statistics from the logs Implicit, can be omitted |
| view | Crapview: view your statistics |
| setup | Crapset: configure these tools |
| update | Crapup: check for updates |
| Abbr. | Option | Additional | Description |
|---|---|---|---|
| -h | --help | prints an help screen | |
| --examples | prints usage examples | ||
| -l | --less | less output on screen | |
| -m | --more | more output on screen | |
| -p | --performance | prints performances data | |
| --no-colors | prints text without using colors | ||
| --auto-delete | auto-chooses to delete files/folders | ||
| --auto-merge | auto-chooses to merges sessions having the same date | ||
| -e | --errors | make sstatistics of error logs too | |
| -eO | --only-errors | only uses error logs (doesn't parse access logs) | |
| -gO | --only-globals | only updates globals (doesn't store sessions) | |
| -gA | --avoid-globals | does not update global statistics | |
| -b | --backup | stores a backup copy of the original logs file | |
| -bT | --backup-tar | stores the backup as a compressed tar.gz archive | |
| -bZ | --backup-zip | stores the backup as a compressed zip archive | |
| -dO | --delete-originals | deletes the original log files when done | |
| --trash | <path> | moves files to Trash instead of remove <path> is optional: if omitted, default will be used |
|
| --shred | uses shred on files instead of remove | ||
| -P | --logs-path | <path> | path of the directory where the logs are located |
| -F | --log-files | <list> | list of log files to use (names, NOT paths) <list>: whitespace-separated file names |
| -A | --access-fields | <list> | list of fields to use while parsing access logs <list>: whitespace-separated fields |
| -W | --ip-whitelist | <list> | doesn't parse log lines from these IPs <list>: whitespace-separated IPs |
-
Uses default log files as input, including errors (access logs are used by default). Stores a backup copy the original files as a tar.gz compressed archive, without deleting them. Moves files to trash if needed (instead of complete deletion). Global statistics will be updated by default.
craplog -e -bT --trash
-
As the above one, but only parses errors (not access logs). Stores a backup copy the original files as a zip compressed archive, without deleting them. Shreds files if needed (instead of normal deletion). Global statistics will be updated by default.
craplog -eO -bZ --shred
-
Uses user-defined access and/or error logs files from an alternative logs path. Automatically merges sessions having the same date if needed.
craplog -e -P /your/logs/path -F file.log.2 file.log.3.gz --auto-merge
-
Uses default log files for both access and error logs. Uses a whitelist for IPs and a selection of which access fields to parse.
craplog -e -W ::1 192.168. -A REQ RES
-
Print more informations on screen, including performance details. Use the default access logs file but only update globals, not sessions.
craplog -m -p -gO
-
Print less informations on screen, including performance details but without using colors. Use the default access and error logs files, but do not update globals. Make a backup copy of the original files used and delete them when done.
craplog -l -p --no-colors -e -gA -b -dO
Warning: the following syntax is only suited for the usage with installation. If you're using Craplog without installing it, you'll have to run the tools individually. Further informations can be found in the relative sections.
-
Make a version check query.
craplog update
-
View your statistics.
craplog view
-
Set-up Craplog's tools.
craplog setup
You can control the output on screen, like: quantity of informations printed, performance details and the use of colors.
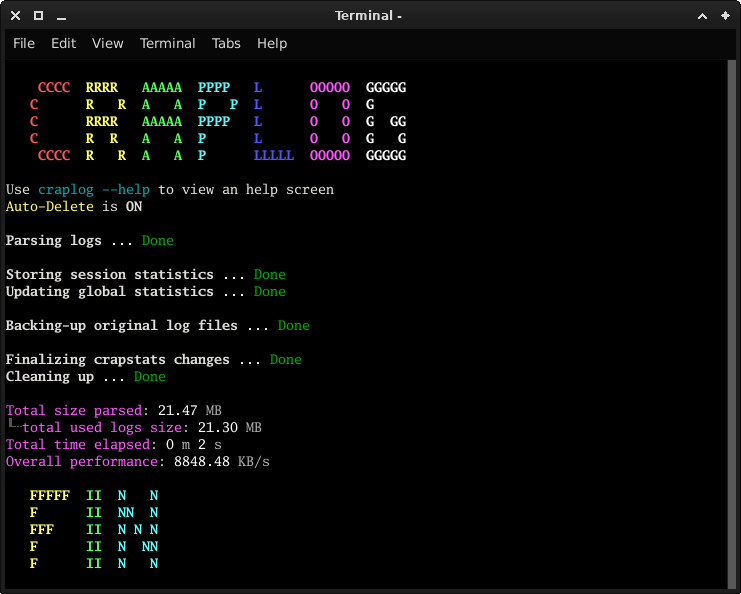
 Normal output vs Less output
Normal output vs Less output
Sometimes is annoying to keep remembering and passing arguments, I know. This is why Craplog gives you the possibility to customize the way it gets ready to do its job.
There's actually more then one way you can customize Craplog's settings: using the configuration tool, editing the configuration files or the hardcoded values.
The configuration file will override the hardcoded values and will be overridden by the command-line arguments, so that the configurations hierarchy results as follows:
- Hardcoded values
- Configuration files
- Command-line arguments
You can also lock a configuration method to avoid it, like discarding any command-line argument or not reading the configuration files. Further informations can be found while following one of the procedures listed above.
Crapset is an utility to easily and safely customize Craplog.
With Craplog installed:
craplog setup
Without Craplog installed (from the main folder):
python3 crapset/crapset.py
Manually editing the configuration files you need.
Files can be found inside craplog-cli/crapconfs/
Directly modifying the script's hardcoded variables, to set pre-defined initialization values:
- Craplog -> line 117 @ craplog-CLI/craplog/craplog.py
- Crapview -> line 21 @ craplog-CLI/cragview/crapview.py
- Crapup -> line 66 @ craplog-CLI/cragup/crapup.py
- Crapset -> line 32 @ craplog-CLI/cragset/crapset.py
Updates can be checked with the updater tool or, in alternative, you can always do a manual update.
Crapup allows you to query the updates in two different ways: a simple version check query, or an effective update through git pull.
With Craplog installed:
craplog update
Without Craplog installed (from the main folder):
`python3 crapup/crapup.py
This is the default method.
Crapup will check for a version-update through a simple GET request to the version check file in this page.
Nothing will be downloaded or updated, it will only queries this repo's version and gives back a response. You'll have to manually download and apply the changes.
This is the suggested method.
Crapup will update your local version by directly fetching this repo. This is the suggested method since it's fast, reliable and easy.
You can also perform this procedure manually if you want, by following the update with git guide.
A self-served update of Craplog can be done in the well-known two ways.
To manually update Craplog, please download the new version of this repo and run the update script.
Or alternatively manually copy-paste this list of files/folders in your Craplog installation directory:
craplog/, crapset/, crapup/, crapview/, README.md, LICENSE.
If you opted for the manual copy-paste, please make sure the operation fully replace the old content, meaning that you have to check that no old entry (maybe with a different, old name) is left there.
To update Craplog with git you'll need to have a local clone of this repo.
If you downloaded Craplog using the git clone method, you should be ready to go.
Follow these steps:
-
Make sure you're in Craplog's main folder with your terminal
You should see "craplog" as outputls | grep craplog
-
Make sure you have git installed in your system
This should output the path of your git executablewhich git
-
Test if a git repository is already initialized in the current directory
No error message should be showngit statusIf you get an error message, follow these steps to initialize a git:
-
Initialize the git repo, using
mainas local branch namegit init -b main -
Configure it
git config core.filemode false git config remote.origin.url https://github.com/elB4RTO/craplog-CLI.git git config remote.origin.fetch +refs/heads/*:refs/remotes/origin/* git config remote.origin.prune true git config branch.main.remote origin git config branch.main.merge refs/heads/main git config pull.rebase false -
Add Craplog's files to the git index
git add craplib/ craplog/ crapview/ crapup/ crapset/ README.md LICENSE -
Make a
.gitignorefile to ignore the local configurations and statisticsecho "/crapconfs/" >> .gitignore echo "*.crapconf" >> .gitignore echo "/crapstats/" >> .gitignore echo "*.crapstat" >> .gitignore
-
-
Your local repo is ready to pull the updates from the remote:
-
You can directly download and apply any modification with just one command:
git pull origin main
-
Or you can split the process in steps:
-
Download the informations about the new version's changes
git fetch origin -
Inspect any modification
git diff origin/main -
Finally apply the changes (if you want so)
git merge origin/main
-
-
-
If you're having troubles updating for refs/code mismatches, follow the following:
-
Make a backup copy of the
crapstatsandcrapconfsfolders (and whatever else you care about).
Nothing should happen to the non-indexed files/folders, but who knows, right? -
Reset your local git, removing the indexed content
git reset --hard -
Pull a fresh copy of this repository
git pull origin main -
Restore your backups if required
Hopefully you shouldn't need to
-
At the moment, it still only supports Apache2 log files in their default form.
Archived (gzipped) log files can be used as well as normal files.
This version of Craplog keeps track of the log files which have been used.
When a file is parsed succesfully, its sha256 checksum is stored.
The stored checksums will be checked every time a file is given as input, to help preventing parsing the same files twice.
Hashes will be stored in craplog/crapstats/.hashes
If not specified, the files to be used will be access.log.1 and/or error.log.1
Different file/s can be used by passing their names with -F <names> / --log-files <names>
Please notice that only file names have to be specified, NOT full paths.
If not specified, the default path will be /var/log/apache2/
A different path can be used by passing it with -P <path> / --logs-path <path>
At the moment of writing, this is the only supported logs structure.
IP - - [DATE:TIME] "REQUEST URI" RESPONSE "FROM URI" "USER AGENT"
123.123.123.123 - - [01/01/2000:00:10:20 +0000] "GET /style.css HTTP/1.1" 200 321 "/index.php" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Firefox/86.0"
[DATE TIME] [LOG LEVEL] [PID] ERROR REPORT
[Mon Jan 01 10:20:30.456789 2000] [headers:trace2] [pid 12345] [client 123.123.123.123:45678] AH00128: File does not exist: /var/www/html/domain/readme.txt
Statistics will be stored in Craplog's main folder: craplog-CLI/crapstats/
Please refer to the statistics viewer tool to view your crapstats.
Four fields can be examined while parsing access logs:
- IP address of the client
- User-agent of the client
- Requested page/URL
- Response code from the server
You can select which fields to use by passing them with -A <fields> / --access-fields <fields>
Available fields choices are: IP, UA, REQ, RES
You can avoid parsing access logs by passing -eO / --only-errors
While parsing error logs, only two fields will be used:
- Log level
- Error report
By default error logs won't be used, but you can parse them by passing -e / --error-logs
Sessions are made by grouping statistics depending on the date of the single lines and will be stored consequently: new content will be made if that date is not present in the crapstats yet, or it will be merged if the date already exists.
Olny '*.log.*' files will be considered valid as input. This is because these files (usually) contain the full logs stack of an entire (past) day.
Running it against a today's file (which is not complete yet) may lead to re-running it in the future on the same file, parsing the same lines twice.
You can avoid storing sessions by passing -gO / --only-globals
Additionally, global statistics will be created and/or updated consequently.
These statistics are identical to the session ones, in fact they're just merged sessions, for a larger view.
You can avoid updating globals by passing -gA / --avoid-globals
You can add IP addresses to this list (may them be full IPs, only the net-ID part or just a portion of your choice), in order to skip the relative lines by whitelisting (or blacklisting..?) them, in both access and error logs.
Please notice that the given sequence must be the starting part: it's not possible (at the moment, and more likely also in future versions) to skip IPs ending or just containing that sequence.
As an example, if you insert "123", then only IP addresses starting with that sequence will be skipped.
If you insert ".1", then nothing will be skipped, since no IP will ever start with a dot.
But the shortcut "::1" is used by Apache2 for internal connections and will therefore be valid to skip those lines.
The default is to only skip logs from ::1, but different sequences can be passed with -W <IPs> / --ip-whitelist <IPs>
Please notice that using a custom list will overwrite the default one, not appending to it. When passing a custom list as argument, you should include the default ::1 in order to keep whitelisting the relative lines.
Craplog saves statistics as plain-text files, so you can directly view them, but you will agree that this ain't the best way to do that.
Crapview is a cursed application that lets you easily view your crapstats.
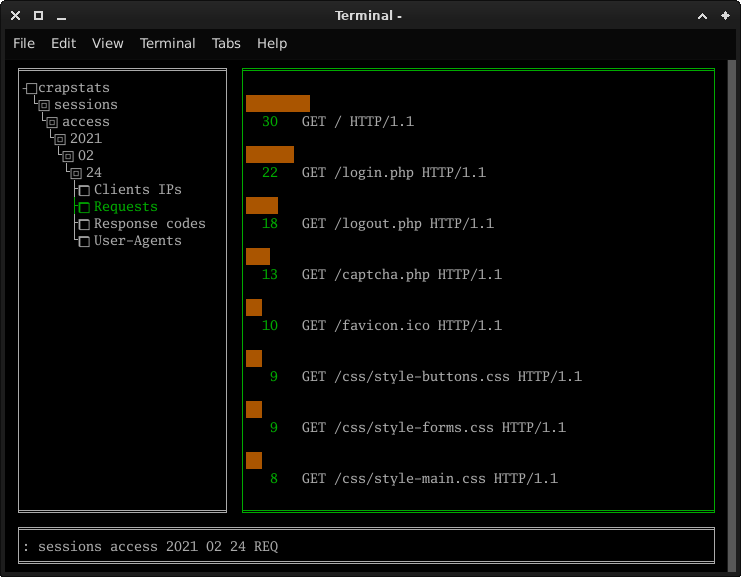
Viewing statistics
With Craplog installed:
craplog view
Without Craplog installed (from the main folder):
python3 crapview/crapview.py
It is pretty straight forward: use TAB to switch between windows, ENTER to interact, the arrow keys ← ↑ → ↓ to move arownd and the letters to write in the cli or jump in the index of the tree.
On the left side you can see the tree of your statistics, as it is in your system.
On the right side you can view the selected statistics file. You can see the elements (in white) and their counts (in green). The bars will show the percentage compared to the other elements in the same file.
Last but not least, at the bottom you can find the cli, which is not a real cli, but more like a search box.
Available keywords ar the following:
-
quit: quits the program -
clear <element>: clears an element of the window. If no element is supplied, it will take effect on each one.
Available elements are:cli,tree,view -
<element>: Directly jump to the relative element -
<tree path>: Directly jump to the relative position in the tree.
Path must be composed by whitespace-separated words, as they are in the tree.
Example: see the Requests statistics of a particulare day:sessions access <year> <month> <day> REQ
COMING SOON
1~15 MB/s
May be higher or lower depending on the complexity of the logs, the complexity of the stored statistics (in case of merge), your hardware and the workload of your system during the execution.
Usually, if it takes more than 10 seconds to parse 10 MB of data, it means you've probably been tested in some way (better to check).

Normal vs Scanned
The above image shows the difference in performances between two different sessions, having the same number of lines and very similar data sizes.
On the left side, the parsed logs resulted from a webserver with normal activity.
On the right side, the parsed logs resulted from a webserver which have been scanned with tools like sqlmap and nikto (not nmap)
Craplog will automatically make backups of global statistics files (in case of fire).
If something goes wrong and you lose your actual globals, you can recover them (at least the last backup taken).
Move inside the folder you choose to store statistics in, open the "globals" folder, show hidden files and open the folder named ".backups'.
The complete path should look like /<your_path>/craplog/crapstats/globals/.backups/
Here you will find the last 3 backups taken. Folder named '3' is always the oldest and '1' the newest.
A new backup is made every time you run Craplog successfully over globals.
Please notice that session statistics will not be backed-up
Craplog is under development
If you have suggestions about how to improve it please open an or make a
If you're not running Apache, but you like this tool: same as the above (bring a sample of a log file)