Feature/replace avl digest with merging digest #35182
Conversation
|
Pinging @elastic/es-search-aggs |
|
The big question I set out to answer in this PR was what happens in a mixed I have graphs below, but will give an overview first. Our worst drop in As the compression increases (NB: Higher compression values mean more The worst mixed-implementation performance actually came with Gaussian I am concerned that this PR will add a "flaky" unit test. I've run this test Graphs of test results (Note - when I say "99th Percentile", I mean that's the percentile I queried the TDigest for, not that this is the 99th percentile of the error): Random Distribution, 99th Percentile: Gaussian Distribution, 90th Percentile: Random Distribution, 90th Percentile: |
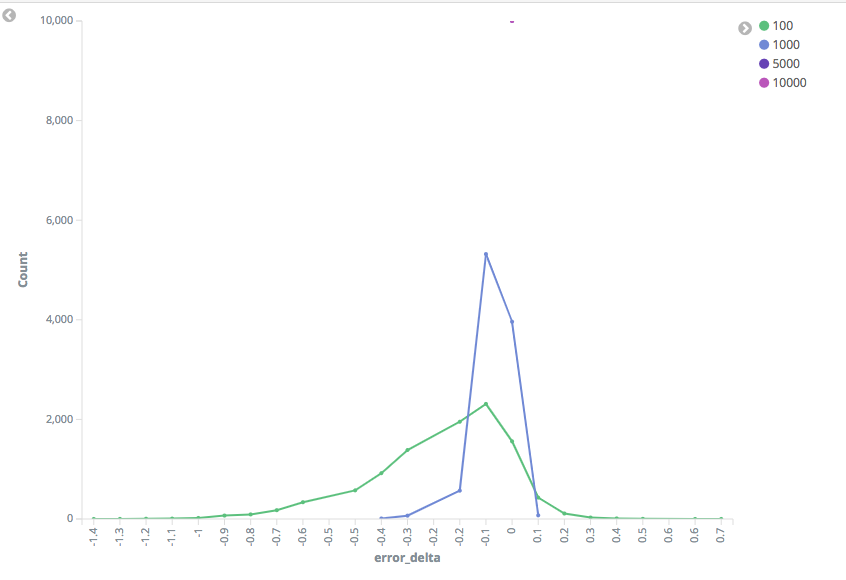
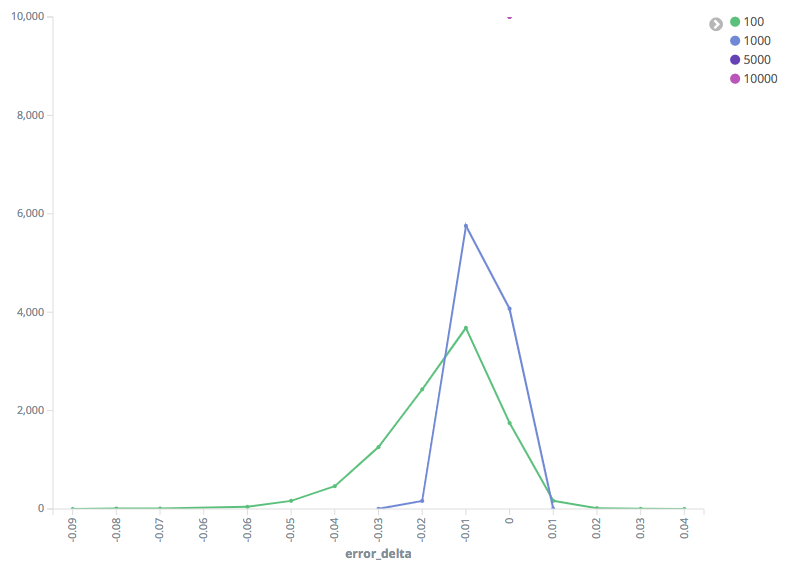

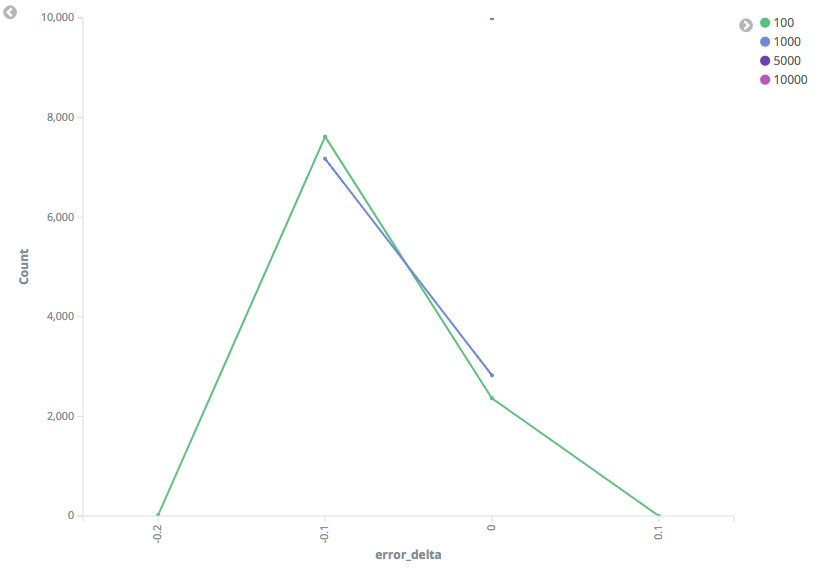
|
Thanks for running these benchmarks @not-napoleon. Based on the fact that the error introduced in the mixed cluster scenario is pretty low and that we expect mixed clusters to be a short-lived situation I would be happy to proceed with the switchover as is. I'd be interested to hear thoughts from @polyfractal and @jpountz on this though. Also in terms of the "flaky" test. I think we can do one of two things (again I'm interested to see what you, @polyfractal and @jpountz think here):
|
|
@colings86 both options for the test seem reasonable. I was running 10k iterations of the test in less than 120 seconds on my laptop, and a lot of that time is gradle overhead, so 50 shouldn't even be a blip in our test times. |
Gernerally ++ to this. @not-napoleon and I were chatting last night and another point came up: since the error basically goes to zero when compression is cranked up, if a user is unhappy about the potential cross-version error they could temporarily increase I did have a few questions about testing methodology after noodling over it a bit. I'm not sure if any of these are important, they are more half-baked thoughts than anything:
I'm leaning towards option 1), or just cranking the tolerance up a bit and revisiting if it still flakes out on CI. Since this is a short-lived problem/test that will go away after everyone upgrades, it probably doesn't make a ton of sense to invest lots of time trying to keep the test stable. |
|
I'm inclined to not keep the tests around; I don't think they prove anything individually that we need for the long term. |
|
Hi @not-napoleon, I've created a changelog YAML for you. |
|
Pinging @elastic/es-analytics-geo (Team:Analytics) |
|
Looks like continuing to adopt merging digest is worth our while from a performance perspective: The two hour and 24 hour variant of this search showed a similar relative improvement. This based on running this search from a new tsdb rally track: The baseline is main branch and contender this PR. |
|
This is no longer relevant |
Relates to #28702
@colings86 had started this conversion in the above referenced PR. This builds on his work with unit tests for deserializing between the two t-digest implementations.
This is a work in progress because the testing methodology is ready for feedback, but specific test parameters still need to be tuned.