Compile String.valid_utf8?/1 inline
#12354
Conversation
|
Upon further review, this seems to actually be slower on x86. Rescinding this PR. |
|
Hi @mtrudel and @moogle19! Also, be sure to check OTP 26, it has some improvements around this area. But I would also send a proposal to the Erlang/OTP team to add a |
|
We're actually looking at taking an (optional) 'sprinkling of NIFs' approach with a couple of hot paths in Bandit, including this one. Around half of the improvements are probably of general interest, while the other half are pretty Bandit-specific. @moogle19 has already worked up some prototypes using rustler, so integrating simdutf8 would be really straightforward. If it bears fruit (as I suspect it will) I'll happily take care of pushing the work / proposals upstream (when you said 'send a proposal', I assume you mean via the EEP process?) Also those changes to OTP26 look great, and will likely be a significant improvement here regardless. Going to benchmark them now! |
|
I don't think you need an EEP for this. I would start a discussion on the forum or potentially just submit a PR depending on your appetite. :) Pro-tip, in order to add NIFs to Erlang/OTP, first:
If you implement the nif before the stub, then you can't start the runtime because the stub the nif is supposed to fill in is missing. It may also be necessary to put the nif on a private module, such as erts_internal. I am not sure all modules from OTP are nif-able. :) |
|
Tips from the pro himself! Thanks so much! |
|
Oh you! |
|
OK, this is really interesting. Given this implementation: Mix.install([:benchee])
defmodule New do
@compile {:inline, valid?: 1, valid_utf8?: 1}
def valid?(<<string::binary>>), do: valid_utf8?(string)
def valid?(_), do: false
defp valid_utf8?(<<_::utf8, rest::bits>>), do: valid_utf8?(rest)
defp valid_utf8?(<<>>), do: true
defp valid_utf8?(_), do: false
end
defmodule New2 do
@compile {:inline, valid?: 1, valid_utf8?: 1}
def valid?(<<string::binary>>), do: valid_utf8?(string)
def valid?(_), do: false
defp valid_utf8?(<<a::8, b::8, c::8, d::8, rest::bits>>)
when a < 128 and b < 128 and c < 128 and
d < 128,
do: valid_utf8?(rest)
defp valid_utf8?(<<_::utf8, rest::bits>>), do: valid_utf8?(rest)
defp valid_utf8?(<<>>), do: true
defp valid_utf8?(_), do: false
end
Benchee.run(
%{
"old" => fn input -> String.valid?(input) end,
"new" => fn input -> New.valid?(input) end,
"new2" => fn input -> New2.valid?(input) end
},
time: 10,
memory_time: 2,
inputs: %{
"micro" => String.duplicate("a", 10),
"medium" => String.duplicate("a", 10_002)
}
)Here's what I get on OTP 25: OTP 25 Benchmark(tl;dr: inlining makes a little bit of difference, and fast-pathing ASCII strings with a 4 byte match actually slows things down) Here's the exact same thing on OTP 26 (ref:master): OTP 26 BenchmarkThis time, we see basically no difference from inlining, but a 5.6x difference on large ASCII strings by matching them 4 bytes at a time. WOW. On x86 the difference is smaller, at only 2x faster, but it's still twice as fast for a pretty small change. The downside here is that this exact same change ends up 25% slower on OTP 25 and earlier. I'm going to spend a bit more time characterizing this but assuming it checks out, @josevalim is there precedent / best practices (or even an appetite) for per-OTP optimizations such as this in the standard library? Happy to work up a PR if so. |
|
Of note, the improvement doesn't seem to come from the upstream work on utf8 validation, but rather something to do with the efficiency of the '4 byte at a time' pattern match. |
|
How does it scale? Comparing to reading two/four/eight bytes at a time? |
|
Also please benchmark non ascii strings to see the additional cost there. The linked paper on simdutf8 also has references on useful non SIMD techniques to validate them. |
I'm looking at this now. I spent the better part of an afternoon recently looking at a bunch of variations (different stride lengths, using bitwise vs numeric matches, a whole bunch of different things) and they all came up lacking in some way or another on OTP 25, but literally the first one of these I tried on OTP 26 knocked me right over. We likely get even bigger wins here by the time I'm done golfing. |
100%. This is nowhere near ready for consideration yet, and validating over all types and sizes of inputs is absolutely a necessary part of that! |
|
I've finished characterizing these changes and have some results. Approach & Raw DataI took the following approach (all steps carried out on ARM & x86):
Summary of ResultsUnder the right conditions (all-ascii binaries larger than ~128 bits on OTP26), we see significant improvements: 2.5x for 4k inputs on x86, and 5x on ARM. These numbers seem to increase quadratically (0.02/0.07 coefficient (ARM/x86), R^2=0.98). This is nothing to sneeze at, though the necessary conditions are somewhat constraining. SuggestionBased on the above, it would seem that a winning approach here would be to:
WDYT? |





|
If it helps to clarify, a rough sketch would look like @spec valid?(t, atom) :: boolean
def valid?(string, variant \\ :default)
def valid?(<<string::binary>>, :fast_ascii) when bit_size(string) >= 128, do: valid_utf8_fast_ascii?(string)
def valid?(<<string::binary>>, _), do: valid_utf8?(string)
defp valid_utf8?(<<_::utf8, rest::bits>>), do: valid_utf8?(rest)
defp valid_utf8?(<<>>), do: true
defp valid_utf8?(_), do: false
defp valid_utf8_fast_ascii?(
<<0::1, _a::7, 0::1, _b::7, 0::1, _c::7, 0::1, _d::7, 0::1, _e::7, 0::1, _f::7, 0::1,
_g::7, 0::1, _h::7, 0::1, _i::7, 0::1, _j::7, 0::1, _k::7, 0::1, _l::7, 0::1, _m::7,
0::1, _n::7, 0::1, _o::7, 0::1, _p::7, rest::bits>>
),
do: valid_utf8_fast_ascii?(rest)
defp valid_utf8_fast_ascii?(<<_::utf8, rest::bits>>), do: valid_utf8_fast_ascii?(rest)
defp valid_utf8_fast_ascii?(<<>>), do: true
defp valid_utf8_fast_ascii?(_), do: false |
|
Awesome work @mtrudel! Did you try a bitmask version? 32 bits are efficient in the Erlang VM, so you can read 32bits at a time and do a bit mask on 0x80808080. If the mask is zero, then it is valid. You could try with 48bits and even 56bits but I am almost sure 64 bits are bignums in Erlang and maybe be slower. |
|
I'd tried bitwise checks (at 8, 32, 64, 128 bit strides) and dropped them from competition as they weren't very remarkable. However, going back and trying different stride lengths is a very different story (especially on x86): I tried 8, 32, 48, 56, 64, 128 bitwise matches this time around, on both platforms. On both platforms, 56 bit strides are the best performer (with 32 bit coming in second). This makes sense as the size of a small int is 60 bits so 56 is the largest whole-byte chunk we can read without straying into bignum territory. Recasting the previous winner (pattern128) against bit32 and bit56, here's what we get: ARM performance increases to 8.3x (!) @ 4k: x86 goes up to 4.6x @ 4k: It also improves on some of the previous shortcomings:
I think the overall approach of adding an optional Unless you have any objections, I'll get this cooked up into a PR for 1.15. |


|
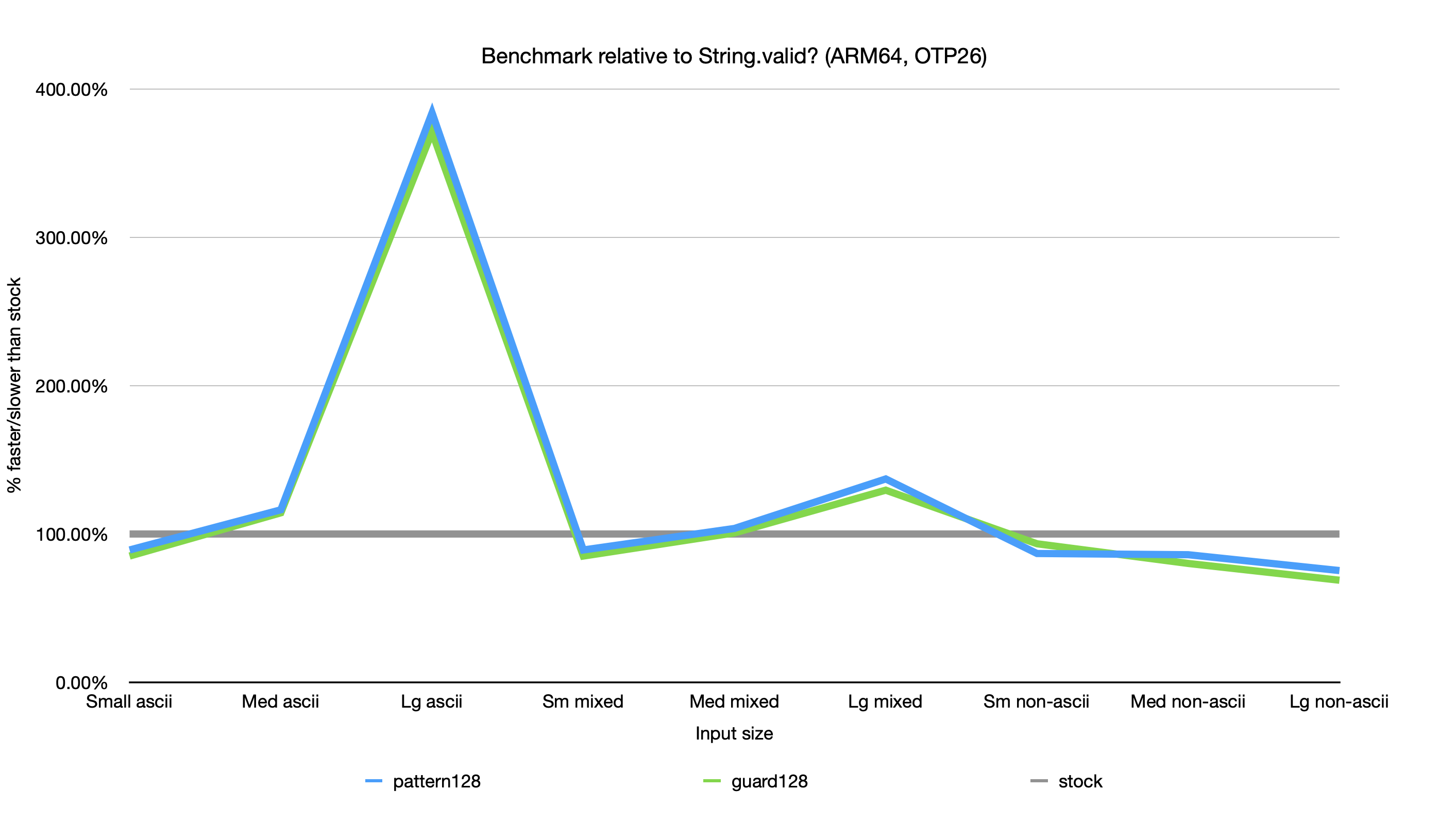
Revised input type performance on ARM: Revised input type performance on x86: ARM performance is still pretty degraded for non-ascii strings, but x86 performance is improved for all cases except large non-ascii strings. |


|
Again, for clarity, the changes would look something like: @spec valid?(t, atom) :: boolean
def valid?(string, variant \\ :default)
def valid?(<<string::binary>>, :fast_ascii), do: valid_utf8_fast_ascii?(string)
def valid?(<<string::binary>>, _), do: valid_utf8?(string)
defp valid_utf8?(<<_::utf8, rest::bits>>), do: valid_utf8?(rest)
defp valid_utf8?(<<>>), do: true
defp valid_utf8?(_), do: false
defp valid_utf8_fast_ascii?(<<a::56, rest::bits>>) when Bitwise.band(0x80808080808080, a) == 0, do: valid_utf8_fast_ascii?(rest)
defp valid_utf8_fast_ascii?(<<_::utf8, rest::bits>>), do: valid_utf8_fast_ascii?(rest)
defp valid_utf8_fast_ascii?(<<>>), do: true
defp valid_utf8_fast_ascii?(_), do: false |
|
Yes, I think those improvements are great, awesome work. PR welcome. |
A quick win to get about a 15% performance boost on UTF-8 validation. This function is consistently at the top of Bandit's WebSocket profile traces, so any wins we can get here would be great.
yields
(FWIW @moogle19 and I have spent a fair bit of time trying to improve this implementation (longer strides, clever
Bitwisetricks, Cowboy's implementation, and others) and haven't been able to get anything better that doesn't have awful memory characteristics. See notes at mtrudel/bandit#73)