Optimize the performance of TimestampParser#parse(String) #145
Comments
|
After fixing page size, I tried to profile the performance again. I used localfile input plugin and null output plugin. The timestamp parsing consumes almost CPU about 90%. |
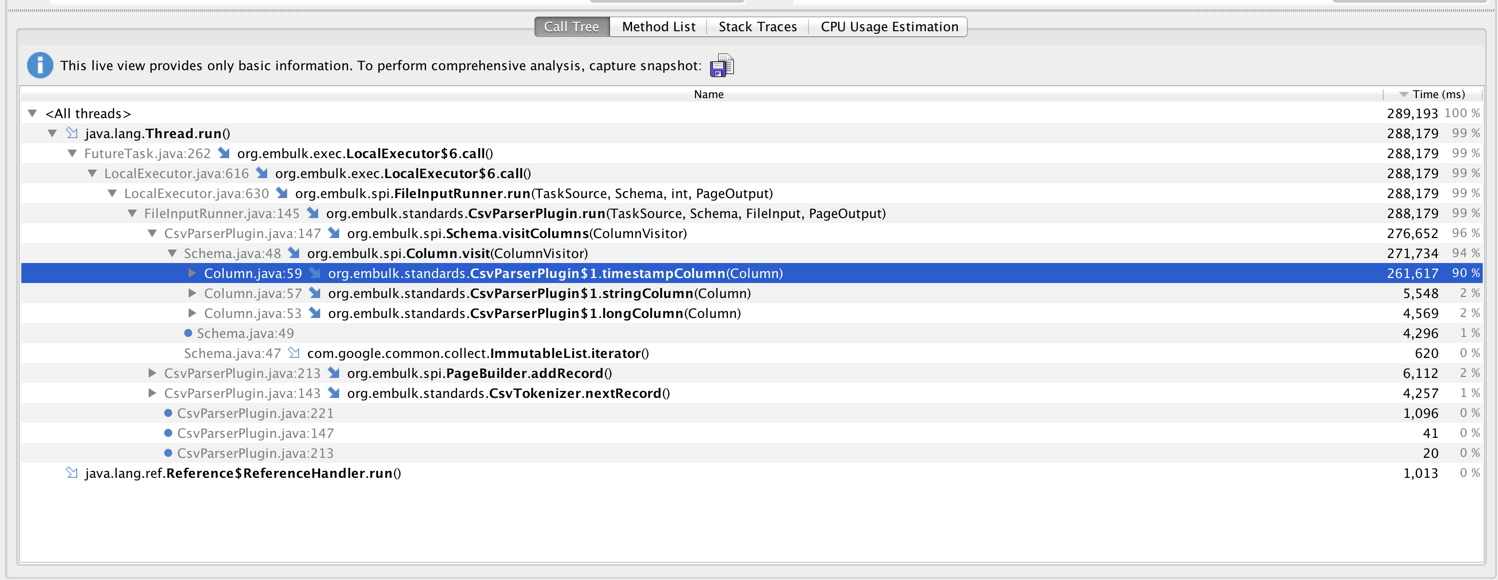
|
An implementation idea is implementing timestamp parser in Java. JRuby implements timestamp formatter in Java. Parser should be able to be the same design with formatter. |
|
I've added the issue #164 , which my be related to this issue. |
|
Hello. I would like to inform my knowledge about the performance of TimestampParser. I tested differences between Java and JRuby(original) implementation. I used time command and the result is like this(All tests run on Mac OS X Intel Core i5/2.7GHz):
When the file was tested for embulk 0.6.5, embulk finished about 4:48 in my environment. When the same file was tested for embulk 0.6.5 + my change ( 26ea959 ), embulk finished about 13.4 secs. From this, it may be better to improve parsing timestamp. My tested code can parse some patterns using java. It may help for some users who only use patterns supported by SimpleDateFormat. Sample testcaseGenerate timestamp csv file. Example script to generate timestamp sample csv file. The following script generates 100MB test file. For example, use like the following config.yml file to test the above file. Sample change to improve some type of performanceMy enhancement code is 26ea959 . This can improve some patterns supported by SimpleDateFormat. This doesn't handle unsupported patterns like micro/nano seconds. I considered I make a pull request for my change and I decided not to do it because it may be required to check more locale related behavior(default locale is better to set 'en' ?) and test patterns. I guess this performance behavior is under investigation and my code only improve some patterns. So, this is just FYI for the performance issue. |
|
Thank you for your information. Your benchmark result reaches the same conclusion with @muga's CPU profile result. Here is the idea of @muga and me:
@muga did you bring this idea to the JRuby community, by the way? What's the status of the code? Did you find the reusable test cases of Time.strptime in JRuby code? |
|
Thank you very much for the comment and it sounds good to me. |
|
Maintaining an open issue for years is easy. Closing it is difficult. |
The text was updated successfully, but these errors were encountered: