Rewrite BSM optimizations in the new SSA-based intermediate format #1958
Conversation
6e56fcb
to
671119e
Compare
The upcoming beam_ssa_bsm pass allows match contexts to be used across function calls that take said context as an argument, which means it's fairly common for them to end up in Y registers.
The upcoming beam_ssa_bsm pass makes this redundant.
get_anno/3: as get_anno but with a default value
definitions/1-2: returns a map of variable definitions (#b_set{})
uses/1-2: returns a map of all uses of a given variable
mapfold_blocks_rpo/4: mapfolds over blocks
308dbf5
to
fc1ac1b
Compare
fc1ac1b
to
9f6f690
Compare
|
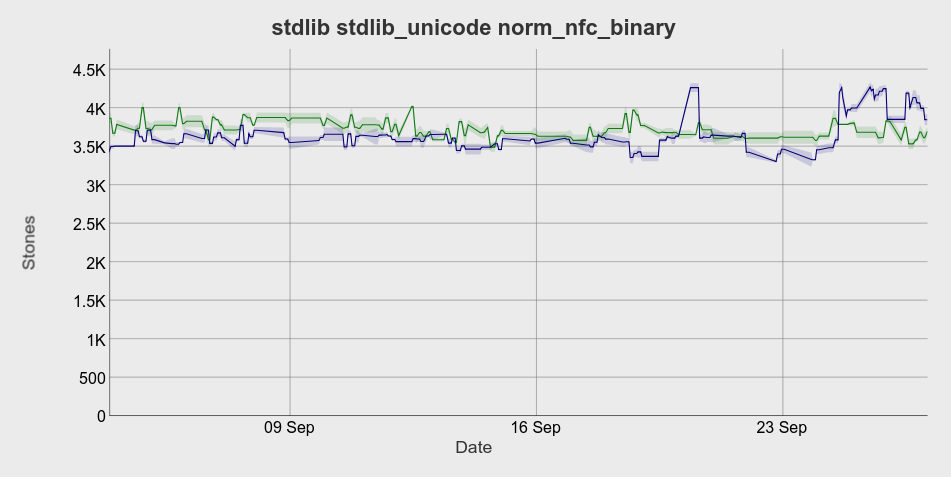
I've fixed a performance regression on 32-bit platforms and cleaned up a few cosmetic issues. It doesn't look like there's much left to do so I'll merge it on Friday if nothing new pops up. HiPE is still not fixed but there's plenty of time until OTP 22. I've also got some benchmarks now. The old pass did a pretty good job and a lot of our code was written with its limitations in mind (hurting readability in some cases), so most of the benchmarks are unchanged, but the ones I set out to improve have seen substantial gains. The blue line is this PR and the green line is
|


|
I would have assumed that there would be a line also for Also, since presumably you have an easy way to create these graphs, perhaps it would be a good idea to include HiPE on It's a super-busy period right now, but today we briefly talked with @margnus1 about at least providing some guidance to what parts of HiPE need to be changed and how. Let's see whether we will be able to do this next week... |
The graphs were taken from the nightly builds and are of
You can also see that This is a bit unfortunate. Your code no longer has to be arcane to be fast (or at least less arcane), but our benchmarks won't show that because they tend to look at things we've written with the old pass in mind.
Sounds good. |

This commit improves the bit-syntax match optimization pass, leveraging the new SSA intermediate format to perform much more aggressive optimizations. Some highlights: * Watch contexts can be reused even after being passed to a function or being used in a try block. * Sub-binaries are no longer eagerly extracted, making it far easier to keep "happy paths" free from binary creation. * Trivial wrapper functions no longer disable context reuse.
The beam_ssa_bsm pass welds chained matches together, but the match expressions themselves are unchanged and if there's a tail alignment check it will be done each time. This subpass figures out the checks we've already done and deletes the redundant ones.
Remove the variable aliasing support that was needed for the old beam_bsm pass.
This has been superseded by bs_get_tail/3. Note that it is NOT removed from the emulator or beam_disasm, as old modules are still legal.
9f6f690
to
afa36d2
Compare
|
I removed the tests because we already know that they fail hard and we don't want to litter our test result page with them. This is a temporary measure and we always planned to revert it in the branch that reintroduces support, I didn't mention it in the commit message because I figured it was obvious. In either case I hope this won't remain a problem for long, the faster I get help the faster this gets resolved. |
|
Please try to understand what I am complaining about. The commit that removed these tests (afa36d2) is actually the same that suggested to use the option So, independently of whether the HiPE compiler is fixed to work for the new instructions, there needs to be a way to test that the |
|
The Therefore, we have no interest that the hipe compiler in OTP 22 can handle code that has been compiled with Also, note that there is at least one test case in My suggestion (unless you have very good reasons otherwise), is that you revert the commit yourself as the first thing in your branch that implements the support for the new binary matching instructions. |
This PR improves the bit-syntax match optimization pass, leveraging the new SSA intermediate format to perform much more aggressive optimizations.
While mostly done this is still a work in progress, and I'm posting it a bit early because I need help adding HiPE support for a few new instructions. @kostis, @margnus1: could you lend me a hand?
Some highlights:
Sub-binary creation can now be delayed within function bodies
Sub-binaries aren't created until they're actually used as binaries, making it significantly easier to write optimized happy paths. The following code used to disable reuse altogether:
This also applies when an alias is taken for the entire match:
The cost of backtracking is significantly reduced
Match contexts only keep track of their current position, and backtrack positions are now stored in plain registers instead of "slots" on the context. This means that passing them to another function or using them near a try block will no longer disable reuse, improving performance for modules that do a lot of backtracking.
As an added benefit this also avoids creating a new match context when a function needs more slots than the context it was given, which was a very surprising (but thankfully uncommon) performance sink.
Improved context reuse within function bodies
All matches operating on the same binary are combined into a single match sequence, greatly reducing the number of match contexts created.
Wrappers no longer disable context reuse
Wrapper functions used to disable reuse in even the simplest cases, but no longer: