This add-on allows to integrate easily eXoPlatform and Elasticsearch. It provides an API to index and search resources in Elasticsearch, without having to bother with all the boilerplate code.
This addon is available in the eXoPlatform addons catalog, so it can be installed directly by the addons manager, from the root folder of your eXoPlatform instance :
./addon install exo-es-searchDepending on the type of deployment you will use, you may have have to install the eXo ES Embedded addon.
We support 2 deployment modes of ElasticSearch:
-
Embedded: One node of ES embedded in each PLF instance
-
External: PLF (deployed in standalone or cluster mode) is connected to an external ES (deployed in standalone or cluster mode)
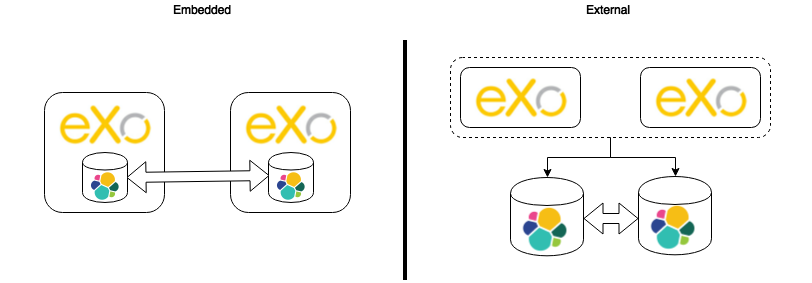
So, we have 4 deployment typologies:
Embedded |
External |
|
Standalone |
Default configuration |
|
Cluster |
The mode "standalone & embedded ES" is indicated only for small deployments: limited number of users/activity (those limits will be established by TQA tests).
The strategy for High Availability of the ES cluster depends on the client’s architecture (Load Balancing ? IP switching ? …) and is not described in this document.
An ES node is embedded in the PLF server (and is hosted in the same JVM). All the required addons are already bundled in the addon, no need to install them.
The ES node is declared as:
-
*Master (Manage the "cluster" with only one node)
-
*Data (To index and store documents)
-
*Client (To serving/coordinate request from PLF)
* means mandatory
By default
-
the parameter es.cluster.name of the ES cluster is exoplatform-es by default
-
the parameter es.network.host is set to 127.0.0.1 (this prevents accesses from IP other than localhost and prevents other nodes to join the ES cluster)
-
the broadcast is disabled: es.discovery.zen.ping.multicast.enabled: false
-
ES is binded to port 9200 for HTTP connections (property es.http.port)
ES nodes are not embedded in PLF server: PLF connects to the external ES node/cluster.
The following plugins must be installed on each node:
This add-on is not supported in PLF 4.3.
Even if theoretically this addon should be compatible with any Elasticsearch version from 2.0, it has only been tested with the version 2.3. So our recommendation is to use Elasticsearch 2.3.x.
"ElasticSearch in eXo" is composed of 2 Maven project packaged as 2 add-ons:
-
exo-es-search (required) contains
-
the connector to eXo Unified Search
-
the indexer (see Integration with PLF)
-
the HTTP client that connects to ES
-
-
exo-es-embedded (optional) if ES is deployed in "Embedded" mode
The exo-es-embedded add-on is deployed as a exo-es-embedded.war that contains all the dependencies and plugins of ES.
The data is stored in [PLF base dir]/gatein/data/es (this is configurable by setting the property es.path.data).
When deployed as embedded, the Elasticsearch configuration files (elasticsearch.yml and logging.yml) are embedded in the add-on. All the properties can be set directly in exo.properties and will override the default properties in defined in elasticsearch.yml and logging.yml.
The following elements are configurable in exo.properties:
All the properties below are standard properties of ES.
When a property es.xxx is defined in exo.properties, it is automatically managed by the embedded ES node (without the "es." prefix).
Property |
Description |
Default value |
es.cluster.name |
Cluster name identifies your cluster for auto-discovery. If you’re running multiple clusters on the same network, make sure you’re using unique names. |
exoplatform-es |
es.node.name |
Node names are generated dynamically on startup but they can also be set manually. |
exoplatform-es-embedded |
es.network.host |
Set both 'bind_host' and 'publish_host'. |
127.0.0.1 |
es.discovery.zen.ping.multicast.enabled |
Unicast discovery allows to explicitly control which nodes will be used to discover the cluster. It can be used when multicast is not present, or to restrict the cluster communication-wise. |
false |
es.discovery.zen.ping.unicast.hosts |
Configure an initial list of master nodes in the cluster to perform discovery when new nodes (master or data) are started. |
["127.0.0.1"] |
es.http.port |
Port of the embedded ES node. |
9200 |
es.path.data |
Path to directory where to store index data allocated for this node. |
gatein/data |
The client supports deployment with ES nodes dedicated to indexing and ES nodes dedicated to search.
Property |
Description |
Default value |
exo.es.search.server.url |
URL of the node used for searching. |
|
exo.es.search.server.username |
Username used for the BASIC authentication on the ES node used for searching. |
|
exo.es.search.server.password |
Password used for the BASIC authentication on the ES node used for searching. |
|
exo.es.index.server.url |
URL of the node used for indexing. |
|
exo.es.index.server.username |
Username used for the BASIC authentication on the ES node used for indexing. |
|
exo.es.index.server.password |
Password used for the BASIC authentication on the ES node used for indexing. |
Property |
Description |
Default value |
exo.es.indexing.batch.number |
Maximum number of documents that can be sent to ES in one bulk request. |
1000 |
exo.es.indexing.request.size.limit |
Maximum size (in bytes) of an ES bulk request. |
10485760 (= 10Mb) |
exo.es.reindex.batch.size |
Size of the chunks of the reindexing batch. |
100 |
These properties are defined globally in exo.properties.
They can be overridden by every connector by setting a property in their InitParams.
Property |
Description |
Default value |
exo.es.indexing.replica.number.default |
Number of replicas of the index |
1 |
exo.es.indexing.shard.number.default |
Number of shards of the index |
5 |
An index is dedicated to an application (Wiki, Calendar, …).
The different types of an application will be indexed in the same index (wiki, wiki page, wiki attachment).
Sharding will only be used for horizontal scalability.
We won’t use routing policies to route documents or documents type to a specific shard.
The default number of shards is 5 (the default value of ES).
This value is configurable per index by setting the parameter shard.number in the constructor parameters of the connectors.
-
The ES node/cluster (whether it is deployed as embedded or external) is able to accept connections only from trusted IP.
-
PLF is able to send request to the client node whatever the security configured on the client node:
-
No security
-
-
As Shield is based on HTTP Basic authentication (https://www.elastic.co/guide/en/shield/current/getting-started.html#clientauth), in a first increment, only HTTP Basic authentication is supported.
When deployed in "standalone & embedded" mode, the network.host is set to 127.0.0.1 by default in order to limit accesses (“indexing/search requests” or “nodes that want to join the cluster”) to localhost only (network.host: 127.0.0.1).
When various ES nodes, embedded in PLF instances, are deployed in cluster, network.host is not set to 127.0.0.1, it means that the ES node will accept connections ("indexing/search requests" or “nodes that want to join the cluster”) from external systems (https://groups.google.com/forum/#!msg/elasticsearch/624wiMWqMCs/my8p1GhgBzMJ).
In this case:
-
Authentication using a technical account may be activated (see Authentication)
-
Network security may be considered in order to limit the nodes which will be allowed to join the cluster.
When PLF connects to an external ES node/cluster, network.host is not set to 127.0.0.1, it means that the ES node will accept connections ("indexing/search requests" or “nodes that want to join the cluster”) from external systems (https://groups.google.com/forum/#!msg/elasticsearch/624wiMWqMCs/my8p1GhgBzMJ)
2 options are possible:
-
Authentication using a technical account (see Authentication) + network security (to limit the nodes which will be allowed to join the cluster)
-
Use of an ES security plugin
Currently the plugins that have been identified to provide both user and node authentication are Shield and Search-Guard.
The selected option will depend on the security policy of the organization.
Connecting to external ES node/clusters exposed through HTTPS is supported. In case of self-signed SSL certificate, just make sure the certificate is present in the keystore of PLF JVM.
No authentication is activated in Embedded mode since. The security is based on the IP filtering. By default ES can only be reached from the same machine (127.0.0.1).
An external ES cluster will be secured depending on the policy of the organization.
The definition of this security policy (network security, authentication, SSO, LDAP, …) is not in the scope of this document.
Note that, for the moment, the ES client embedded in the exo-es-search add-on only supports BASIC authentication.
The login and password of the external ES node/cluster can be set in exo.properties (exo.es.search.server.username / exo.es.search.server.password and exo.es.indexing.server.username / exo.es.indexing.server.password).
-
Authorizations on indexes
-
In multi-tenant environments, we will use only one technical account for all the accesses to ES.
-
Isolation between tenants we be implemented in the SearchService and IndexingService.
-
-
Authorizations on documents
-
ACL are indexed in every document using a field "permissions"
-
ES filters are used to limit the context of queries to the authorized documents. ES filters are performant and can be cached.
-
No ACL inheritance: ACL are computed when a document is indexed and are stored in a "flat" way. If some ACL are changed in PLF, all the associated documents (and their children) must be reindexed.
-
-
All the requests which intend to modify an ES index are sent through the "Indexing Queue"
-
ES search is only appropriate for full-text search. It MUST NOT be use in business logic (ex: "Does event with ID 67868 exist in Task app?") as it is not realtime.
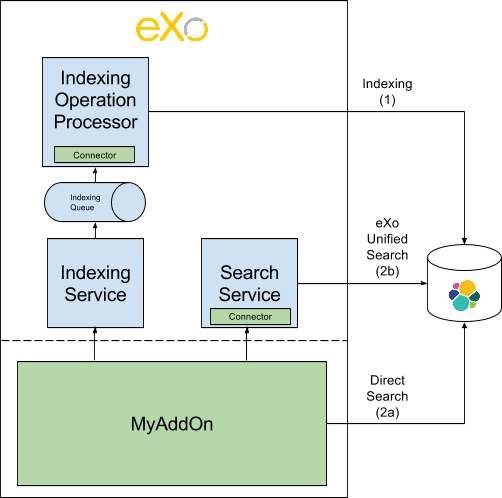
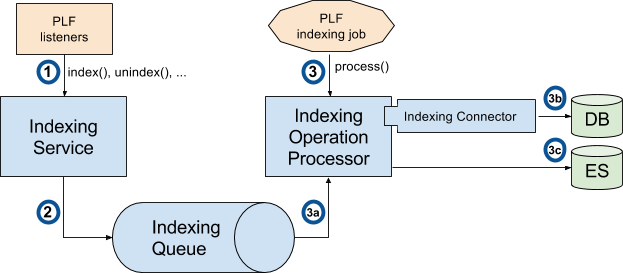
The sequence is as follow:
-
PLF listeners call the method with the ID and the type of the entities that need to be processed
-
IndexingService.index() to index a new entity
-
IndexingService.reindex() to reindex an updated entity. Reindex operation is a create or update operation and a complete update (not a partial update).
-
IndexingService.unindex() to unindex a removed entity
-
-
The IndexingService stores this information in the IndexingQueue
-
At regular interval, the IndexingJob is executed. It invokes IndexingOperationProcessor.process():
-
The ID and the type of the entities are obtained from the queue
-
For every ID, the IndexingConnector corresponding to the type is invoked to construct an object of type Document. A document contains all the data that need to be indexed. The connector generally obtain this data directly from the DB (using existing services or DAO)
-
Then, a bulk containing all these documents is sent to ES through HTTP
-
The integration with PLF uses ES Bulk API to update multiple documents: it is much faster for both Elasticsearch and PLF than issuing multiple HTTP requests to update those same documents.
-
Every time a connector is registered, an "init of the ES index mapping" operation is inserted in the IndexingQueue.
-
Every time a searchable data is modified in PLF, its entityID+entityType is inserted in an "indexing queue" table on the RDBMS, indicating that this entity needs to be reindexed (or deleted from the index in case of deletion).
-
If an entity is updated multiple times in PLF, multiple entries will be inserted in the queue. No row will be updated in the queue in order to avoid locks.
-
The row is inserted in the indexing queue with the operation type (C-reated, U-pdated, D-eleted). That way, in case of deletion, there is no need to query PLF to obtain the entity: a deletion operation is just sent to ES.
-
-
At regular interval, an "indexing processor" (Quartz job configured to avoid overlapping job execution - even in cluster deployments) does the following:
-
Process all the requests for "init of the ES index mapping" (Operation type = I) in the indexing queue (if any)
-
Process all the requests for "delete all documents of type" (Operation type = X) in the indexing queue (if any)
-
Process all the requests for "reindex all documents of type" (Operation type = R) in the indexing queue (if any)
-
Then process the Create/Update/Delete operations (per bulks of 1000 rows max or 10Mb - these values are configurable)
-
if the operation type is C-reated or U-pdated, obtain the last version of the modified entity from PLF and generate a Json index request
-
if the operation type is D-eleted, generate a Json delete request
-
computes a bulk update (https://www.elastic.co/guide/en/elasticsearch/guide/current/bulk.html) request with all the unitary requests
-
submits this request to ES
-
then removes the processed IDs from the "indexing queue"
-
-
The distinct operation code are the following
Code |
Operation |
I |
Init of the ES index mapping |
X |
Delete all documents of type |
R |
Reindex all documents of type |
C |
Index a document (because it was created on PLF) |
U |
Index a document (because it was updated on PLF) |
D |
Unindex a document (because it was deleted on PLF) |
Note that the current implementation of the "indexing processor" doesn’t support multiple instances of the job running at the same time. The quartz job is therefore configured to avoid multiple executions of the job at the same time, even when PLF is deployed in cluster (the job is annotated with @org.quartz.DisallowConcurrentExecution).
In case of error, the entityID+entityType will be logged in a "error queue" to allow a manual reprocessing of the indexing operation. However, in a first version of the implementation, the error will only be logged with ERROR level in the log file of platform and an event will be inserted in the Audit trail.
The PLF documents (for example, attachments in wiki) are indexed directly by ES using the plugin elasticsearch-mapper-attachments.
|
Note
|
File Format supported to index: http://tika.apache.org/1.8/formats.html |
Example of content of the "Indexing Queue" table:
OPERATION_ID |
ENTITY_ID |
ENTITY_TYPE |
OPERATION_TYPE |
OPERATION_TIMESTAMP |
1 |
TASK |
I |
20150717-113901034 |
|
2 |
EVENT |
I |
20150717-113901075 |
|
3 |
TASK |
X |
20150717-113902034 |
|
4 |
98876 |
TASK |
C |
20150717-114002032 |
5 |
36567 |
TASK |
D |
20150717-114102067 |
… |
… |
… |
… |
By default, the indexing queue will be a dedicated table in the same database as PLF data.
The timestamp is generated by the database server.
The delay between two executions of the indexing job will be configurable, with a default value of 5 seconds.
PLF is configured with a misfire threshold of 5 seconds (org.quartz.jobStore.misfireThreshold = 5000). It means that, if an execution of the indexing job has not been started 5 seconds after the time it was planned, it is considered as "misfire" (this case happens when the processor needs more than 10 seconds to process the whole IndexingQueue).
What happens to misfire executions is defined on the Quartz’s Triggers. By default, Quartz will try to fire all the misfire executions as soon as possible (MISFIRE_INSTRUCTION_FIRE_NOW instruction) but it’s possible to change this behavior in order to drop the misfire executions (MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT instruction).
For the indexingProcessor, we should switch to this strategy in version 1.1 : https://jira.exoplatform.org/browse/ES-34
Complete reindexing of one entity type is possible through a dedicated API on the PLF indexing service.
When a reindexing operation ("R") is inserted in the IndexingQueue for a given type, the “indexing processor” will “expand it”. It means it will replace the reindexing operation (“R”) in the IndexingQueue by
-
one "delete all" (“X”) operation for the type
-
then one "create" (“C”) operation for every PLF entity
"Expanding a reindexing operation (“R")” is a batch operation, processed in chunks. Each chunk is processed in its own transaction. The size of the chunks can be defined through the property exo.es.reindex.batch.size (the default value is 100).
All these atomic operations will then be processed normally by the "indexing processor".
The operations (and their results) that update the indexes are tracked in an audit trail.
These events are logged on a dedicated exo-logger named "org.exoplatform.indexing.es" with 2 levels:
-
ERROR: requests in error (exceptions and ES responses != 2xx)
-
INFO: requests not in error
The fields are the following (separated by ";"):
Position |
Element |
1 |
ES Client Operation Operations on indexes: create_index, create_type, delete_type Operations on documents: create, index, delete, reindex_all, delete_all |
2 |
Entity ID |
3 |
Index |
4 |
Type |
5 |
Status code of the HTTP response |
6 |
Message from ES (json or plain text) |
7 |
Execution time (in ms) |
It includes Request sending, ES processing and unmarshalling of the response
Examples:
-
Error: Authentication Required while creating an index
-
I;;Task;401;Authentication Required;100
-
-
Delete all documents of an index required
-
X;;Task;200;;430
-
Administration
The add-on will expose a dashboard for the monitoring of the indexing.
This dashboard will contain:
-
Statistics from ES (topology, indexes, documents…)
-
A view of the "Indexing Queue" length
-
A log of the indexing errors with an option to reindex the documents
-
Tools to launch manually a complete or partial reindexing
A basic version of this dashboard will be implemented in the first version of the add-on.
Search
Search query can be sent to ES directly or through a connector to eXo Unified Search.
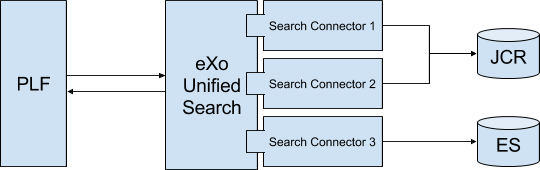
The search service will make direct calls to ES using the HTTP transport (even in embedded mode) and the Query DSL.
When ES search is invoked from eXo’s Unified Search, the search query string is generated by Unified Search. In this case, the fuzziness can be controlled via the standard properties of Unified Search : http://docs.exoplatform.com/PLF42/PLFAdminGuide.Configuration.UnifiedSearch.html.
The scope of the search will be all the fields of the documents except type, permission and createdDate.
Building efficient Indexes is a mix between
-
Search Speed
-
Index Compactness
-
Indexing Speed
-
Times for changes become visible
Lucene, the indexing engine behind ES, did some choice to keep the data structure small and compact. One result is that Lucene write is immutable: Index are never updated. In fact an update consist of the deletion of the previous document (deletion consist just to mark a document as deleted) and the creation of the new one. Consequently update is more expensive than Create.
→ ES is not good to store rapidly changing documents
An ES Cluster is composed of Node that are composed of Indexes that are composed of Shards (Lucene Index) that is composed of Index Segments (Inverted index).
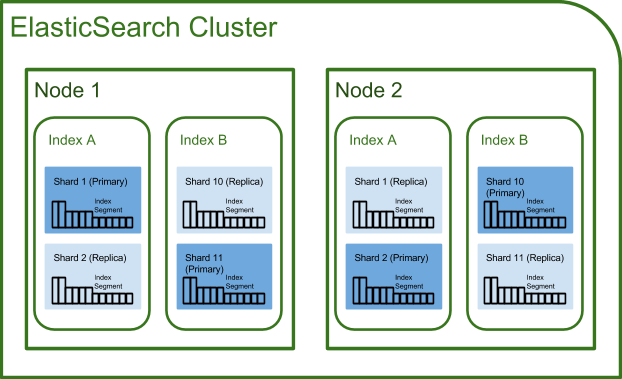
Segments become available for searching only when they are flushed. Flush is managed by the continuous index refreshing (by default every second).
Also flushing is not synchronised across node so it possible for searchers to briefly see separate timelines.
→ ES is not real time
One flush = One new Segment ~ (and possibly) trigger a merge depending on the merge policy (By default Lucene merge segment of same size by batch of 10).
During a search request, Lucene need to search on every segment and then merge the result.
SO more segments = slowest search
BUT merge segments = costing resources (especially I/O and CPU)
→ Lucene maintain a balance between having less segments and minimizing the merge cost
during merge (when documents marked as deleted are finally removed).
→ In pull Mode (especially when reindexing all datas) it’s a good idea to increase the refresh interval setting (or flushing manually) to do not lose too much time flushing and merging small segments.
During an ES search request on a ES node, the workflow is to search on all ES indexes → All shards → all index segments and then merge all results.
→ Searching 2 ES indexes with 1 shard each = Searching 1 ES index with 2 shards
The number of shards is specified at ES creation time and cannot be change later.
→ The only way to increase the number of shard is to reindex all datas
Two types of shards:
-
Primaries of shards (only one): Use for index request
-
Replica of shards (0..n): Only use for search request (and failover)
→ Adding more nodes would not help us to add indexing capacity but searching capacity
For consistency, the primary shard requires that the majority (a quorum) of shard copies return a success response in order to respond successfully to client for an indexing request. The quorum number is defined as follows:
int( (primary + number_of_replicas) / 2 ) + 1
Success means that the operation has been written in the transaction log of the shards no whether if the document is actually part of a live index through a searchable segment.
→ Adding more replicas decrease the overall indexing throughput: You need to wait more nodes to acknowledge the operation (unless you set the write consistency parameter to one instead of quorum)
Cluster state is replicated to every node in the cluster. A state contains:
-
Shard routing table (which node host which indexes and shards)
-
Metadata about every node (where it runs and where what attribute the node has)
-
Index mapping (contains document routing configuration)
-
Template (easily create new indexes)
A node can be defined as Client (Serving/coordinate request), Data (Hold documents) and Master (Manage the cluster). A node can be client, data and master in the same time.
The uniqueness of document ID in ES is defined by type. It means that the couple type/id (= uid) is unique in ES. By default ES is using this document ID to define on which shard the document will be indexed (routing).
We must not let ES specify the ID of the document for us. If we specified an ID for the document, it’s easy to reindex a document. You can safely retry the request: if Elasticsearch did index it, it will reindex it - and the result will be that the document is indexed only one time. If we let ES assign itself the id to document, trying to reindex a document can lead to duplication.
Each PLF document type (task, event, wiki) have unique ID. For instance it doesn’t exist two task with ID = 1. So we need to use PLF ID for document ID in ES.
A shard is the atomic scaling unit for an ES index. It means that a shard is a single indivisible unit and cannot be divided for scaling purpose. It exist no technical limit on the size of a shard, but as a shard is indivisible, the limit to how big a shard can be is related to the hardware of a node.
Specifying the number of shards is one of the most important decision to think about when you create an ES index as it cannot be modified later.
This number depends of the quantity of data you have and the hardware capacity that host your nodes.
The target is to have as less shard as possible for performance purpose will having not too big shard to avoid losing our possibility to easily scale in the future.
Or which document go where ?
Routing is the process of determining on which shard a document will reside in:
Document are routed based on a routing key and are placed on shard number "hash(key) modulo n” where n is the number of primary shards in the index.
The default routing scheme hashes the ID of a document work well but you can improve it by defining yourself the routing policy. We can define the key to be whatever we want (for instance user or document type).
The advantage to define specific routing is to have faster search queries.
For instance let say I have 1 index with 3 shards and I’m indexing 5 differents type of documents (task, wiki, event, doc, activity). If let the default routing policy to document id, it means that task documents can be in any shards. So when I’m searching on the specific type task, Elasticsearch has no idea where my tasks documents are, all the tasks were randomly distributed around shards. So Elasticsearch has no choice but to broadcasts the request to all 3 shards and then merge the result. This can be a non-negligible overhead and can easily impact performance.
Now let’s say that I define a specific routing to route indexing document not based on their document id but based on their type. This means that all task documents will be indexed in the same shards ("hash("tasks”) modulo 5” always return the same shard number). So when I’m searching on the specific type task, Elasticsearch will broadcasts the request to only one shard and it doesn’t need to broadcasts the request to all 3 and then merge results.
Routing a specific document type to a specific shard can be problematic when the number of different documents type is not homogeneous. For instance imagine that 90% of the data to index is wiki document. Following our previous example the shard containing wiki document will be far bigger compare to other shards. As a shard is indivisible this can lead to a big problem for scalability.
Remembering that a ES index with three shards is exactly the same that 3 ES indexes with 1 shard each, have a specific ES index for each type can be a good solution. Then for each ES index you can define the number of shards according to the volume of data you are expected for each type.
For instance in the case of you are expecting that 90% of data to index is wiki document we can create a Wiki ES index with 10 shards and other type (task, event, doc, activity) have their own ES index with only one shard.
To conclude, we should define default shards policy for PLF based on the "average" use case of PLF, for example by analysing the data from community. But our system must be easily configurable to be able to adapt too many scenarios:
-
Use only one index and let ES decide on which shard the document must be indexed based on the document id (ES default config)
-
Use only one index and route document to specific shard accordingly to their type
-
Use one index per document type and let ES decide on which shard the document must be indexed based on the document id
For production environment, especially for big customer, the configuration of the number of shards for each PLF type ES indexes must be done on a case by case basis.
Pros |
Cons |
|
Index per PLF instance/tenant |
Search query on all type is more efficient (Only one index) |
Search query on one type is less efficient because we have to filter on the EntityType on a global index instead of searching on a dedicated index (except if we define a routing policy based on type → In this case we cannot find tune) |
Index per application (ex: calendar) |
Possibility to fine-tune ours different index. For instance 10 shards for Wiki app and only 1 shard for calendar app (Indexing a wiki page is not the same size that indexing an event) Search query on one type is more efficient (index is smaller) |
Search query on all types is less efficient (But still possible as ES accept cross-indexing search) |
Index per type (ex:wiki-page) |
Possibility to fine-tune ours different index. For instance 10 shards for Wiki page and only 1 shard for calendar event (Indexing a wiki page is not the same size that indexing an event) Search query on one type is more efficient (index is smaller) |
Search query on all types is less efficient (But still possible as ES accept cross-indexing search) |
According to the way Unified Search is designed today (One connector per type), one application (Task, Calendar…) will have to implement as many connectors as they have document types (pointing to the same index).
3 possible options:
Pros |
Cons |
|
Listen to PLF events |
Standard way in PLF. Low coupling with the business logic. |
Not integrated in the transaction. |
Trigger indexing manually in the business code |
Can be integrated in the transaction if the business method is annotated @eXoTransactional |
High coupling with the business logic. Additional steps to be considered by the developer |
Listen to JPA events |
Integrated in the transaction |
High coupling with JPA entities lifecycle |
The 1st option ("Listen to PLF events") has been chosen.