This issue was moved to a discussion.
You can continue the conversation there. Go to discussion →
Memory leak when processing a large number of documents with Spacy transformers #12037
Comments
|
Thanks for the report and the code! A couple of questions:
|
|
Hi @shadeMe , I have attached three files:
About the documents being processed, I am processing this on a stream of English web pages. I am quite confident that these are all English documents (barring some minimal noise) due to the way I source them. I am not sure if this happens also with other languages. It is a stream of new content, and the shape of the memory usage graph is always as seen in model_predict_stream_long_run. |

|
Thanks for the extra context. After some extensive testing, we were able to reproduce the same memory behaviour, but the potential causes for that do not seem to point to a memory leak. Let's move this to the discussion forum as the underlying issue is not a bug per-se. BackgroundA bit of background on how the inference When a batch of documents are passed to the As you can imagine, the complexity of the above process requires us to maintain additional state for book-keeping and lazy-evaluation purposes. When combined with the transformer representations, each Profiling resultsDuring our testing, we only noticed ballooning memory usage when the
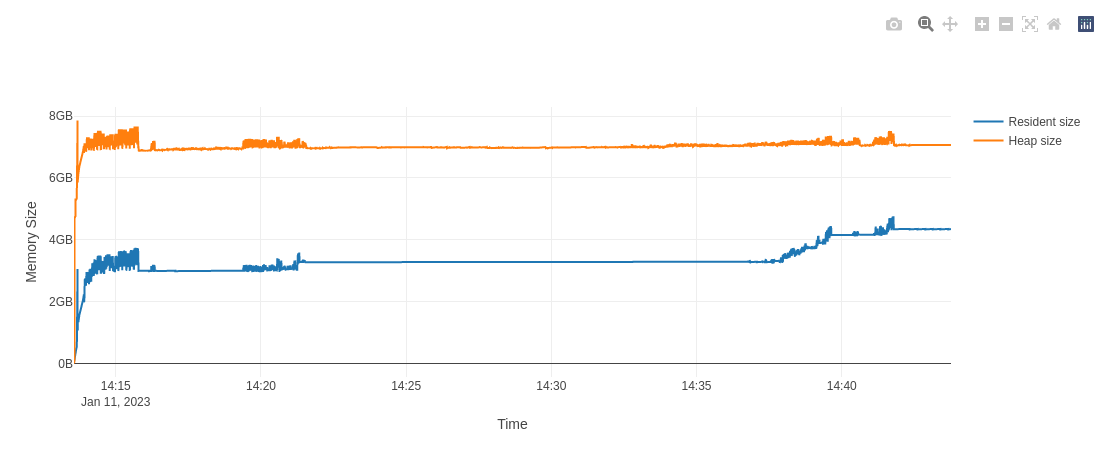
The above graph is from a profiling session where the Re. vocab length: Given that you're processing webpages, there's a high chance of the model encountering novel tokens that are not found in its pre-trained vocabulary. This results in their being added to its string store. While this also contributes to the increase in memory usage, it will likely be eclipsed by the transformer data. Nevertheless, periodically reloading the model should reset its vocabulary. MiscOne further point of note: |
This issue was moved to a discussion.
You can continue the conversation there. Go to discussion →
I have a Spacy distilbert transformer model trained for NER. When I use this model for predictions on a large corpus of documents, the RAM usage spikes up very quickly, and then keeps increasing over time, until I run out of memory, and my process gets killed.
I am running this on a CPU AWS machine m5.12xlarge
I see the same behavior when using en_core_web_trf model.
The following code can be used to reproduce error with en_core_web_trf model
Environment:
Additional info:
I notice that model vocab length and cached string store grows with the processed documents as well, although unsure if this is causing the memory leak.
I tried periodically reloading model, but that does not help either.
Using Memray for memory usage analysis:
The text was updated successfully, but these errors were encountered: