Personality-Captions Dataset #3738
Comments
|
Please can the author respond to it( may be @klshuster ) please |
|
Hi there, you are correct that the training and validation splits only have 1 caption per image, whereas the test set has 5 captions for image; the test set was collected this way such that reference BLEU scores could be computed. If you're referring to Table 6 in the paper, those are generated outputs, where the model outputs a response conditioned on the listed personality. This table demonstrates the flexibility of the model (and the efficacy of personality conditioning) |
|
Hi Thanks for your Response, So its not the compulsion that we need to get 5 outputs for a single Image? like 1 image with 1 personality trait and its caption has to be the out put in general is what your are meaning? |
|
i am not sure I understand the question, could you please elaborate? |
|
well what my doubt was are the dataset designed in such a way that we need to compulsorily get 5 output for each image? Or one trait and caption per image will also be okay? |
|
so if i am implementing my model i am getting the output as below is that correct?
|

|
Also from the training set can i ignore the columns candidates and 500 candidates and carryout my work? will that affect anything? |
Hope that answers your questions |
So is this output correct as per the dataset? |
|
yes! |
|
is there a way i can get your complete code to check how it is working? i mean any link to the complete code? |
|
this project page details how to use the dataset within ParlAI: https://parl.ai/projects/personality_captions/ |
Hi, could you please tell me how to download the personality-caption dataset? I can't find any clue in ParlAI |
Hi @PineappleWill, as mentioned in the linked project page, the dataset can be accessed via |
|
Should we also divide image dataset to train test and validate? becoz we only have captions files as test train and validate in .json format |
|
the data entries in the json files include fields for the image id corresponding to the relevant image. The images are indeed unique by split |
|
so you mean no need to split the images again? when i downloaded the data set i got 2 folders one is personality_captions and the other one is yfcc_images. |
|
or you mean like i need to create a seperate test train and val folder for images taking its ID's from the json files? Or should i just train the train folder? Please can you clear this doubt. |
|
the yfcc images folder has all of the images. the splits of the images are within the json files. You will need to look at the json files to determine which images correspond to which split. |
|
so are you meaning like i need to create different folders again? |
|
how are you interacting with the dataset? if you are using parlai you don't need to create folders, it's all handled within the code. If you are using the dataset outside of ParlAI, I can't really help you as I do not know what system you are using |
|
i am working on google collab |
|
outside ParlAi |
|
i am getting below error when i run the code
|
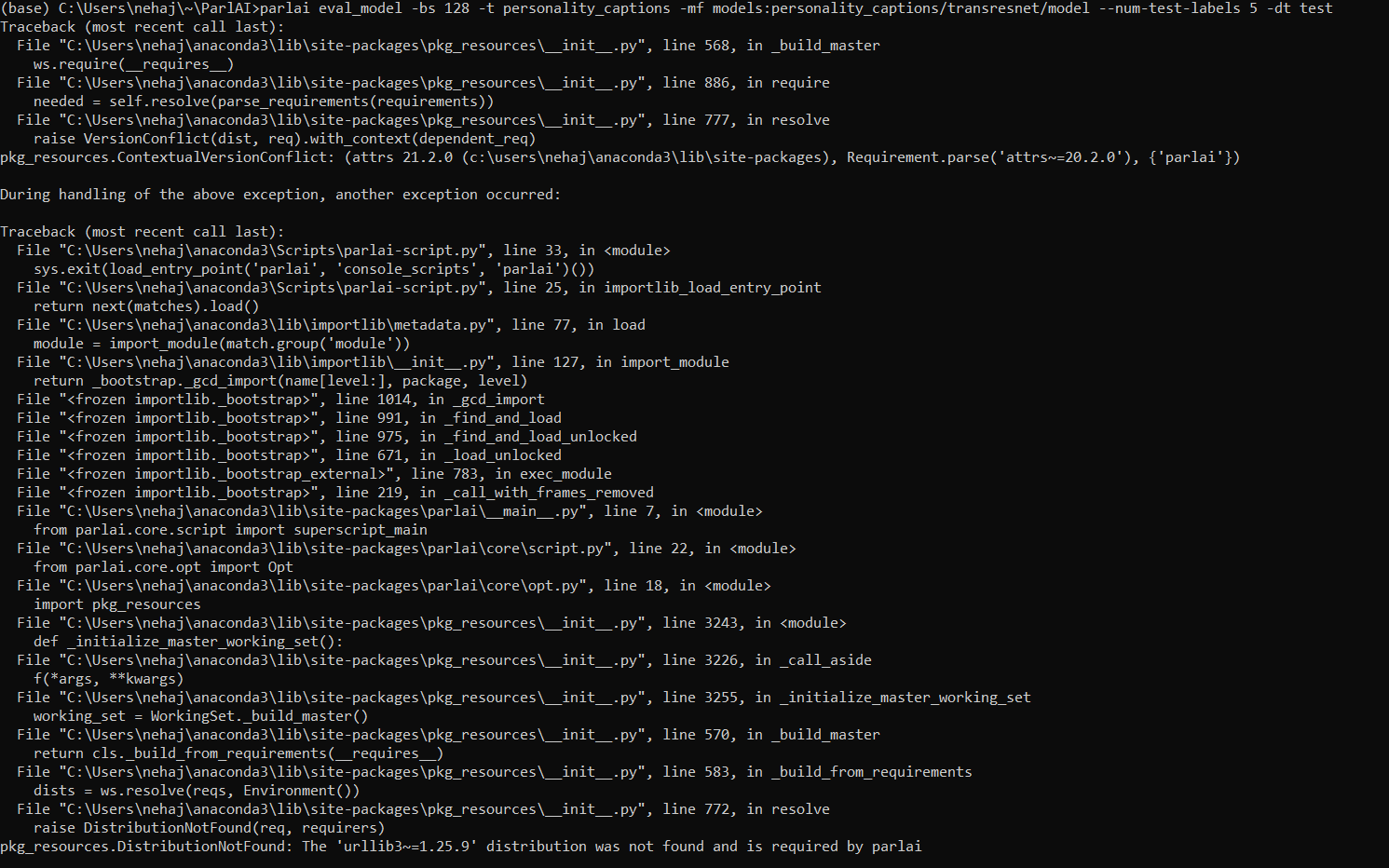
|
@klshuster could you please let me know |
|
we don't support windows so I am unable to help you out with this |
|
if you can have a look at that image i am inside ParlAi environment so is that anything you can help? |
|
The error seems to be coming from |
|
@mojtaba-komeili thanks for responding but which version i need to check and how? |
|
Based on this I say anything |
@klshuster As you mentioned in the first point regarding additional captions in the paper was an example to show how to control the model, may I know from where those 5 different captions for the same images taken?, as per the dataset one image has one caption so a bit confused, Could you please let me know in detail |
|
@klshuster Please can you respond to this last question so it will be helpful to me for my project to carryon |
|
Can someone please respond it would be of great help @stephenroller |
|
these are captions from the retrieval model during inference. the candidate set is all utterances from the training set. the model is given a test image and the shown personality, and then is asked to retrieve a relevant response (from the training utterances). |
|
@klshuster I am really sorry could you please elaborate a bit as it s a bit confusing and tricky |
|
Are you familiar with how dialogue retrieval models work? A retrieval model is given a personality and an image and is asked to generate an answer. The model is a retrieval-based model, not a generative model. That means the model scores a set of candidate sentences and returns the highest scoring sentence as its response. The model needs a set of utterances from which to choose for its response. We take all human utterances from the training set of Personality-Captions and allow the model to select a response from this set. Because the model was trained on several images with several personalities, the model can select several different top responses for the same image, if the personality input is varied (Happy, Sad, Angry, etc.) |
|
@klshuster yeah i understand that thank you, but really confused regarding that candidates column in validation set and candidates, additional_comments, 500_candidates columns in testing set, could you please let me know where i need to use this becoz training set doesn't have any additional column and the model is trained based on that set only |
|
I described those additional columns here: #3738 (comment) If you're training a generative model you don't need to worry about them. |
|
One last question , for generative model should i use that additional comments column? Because for training i am giving only 3 columns so. Also can i concatenate the comment and additional comment to make it a single column and use it for testing? Same for Retrieval model can i concatenate all the columns(candidates, 500_candidates, comments, additional comments) and make a single comment column? |
|
what do you mean by concatenating the columns? |
|
merging the columns and making it as one comment column |
|
they are separate comments so i am not sure how that would work
I'm not sure how else I can describe this |
|
@klshuster may i know on which OS u have run the code pls |
|
ubuntu |
|
When i run the below code given by you guys to evaluate the model inside Parlai env then i am getting the below And once this is done it just keeps asking me the below Please confirm that you have obtained permission to work with the YFCC100m dataset, as outlined by the steps listed at https://multimediacommons.wordpress.com/yfcc100m-core-dataset/ [Y/y]: y |
|
@klshuster could you please help me with this |
|
what happens if you enter |
|
the same things happens i.e it gets broken all the time and i need to again enter y and this repeats |
|
When i run the interactive session i am getting the below error (base) C:\Users\nehaj\anaconda3\Parlai_Project\ParlAI-ce02a0eb9e4d8bf38377d0908ed7bd3b47d7ab2a\projects\personality_captions>python interactive.py -mf models:personality_captions/transresnet/model |
|
it seems the candidates file is corrupted |
|
Sorry then how can i proceed |
|
what is the value of the |
|
Sorry but not able to find that |
|
@klshuster one last question, even for generative mode while testing ,we need to input an image and a personality trait and the model should generate the caption right |
|
that is correct |
|
This issue has not had activity in 30 days. Please feel free to reopen if you have more issues. You may apply the "never-stale" tag to prevent this from happening. |
I have downloaded the dataset, but when i go through the data set training dataset has one caption per image, where as testing has 5 different columns, can someone tell me in the final output of the paper you guys have shown that one image has 5 different personality trait outputs, but from the dataset i can see that there is only one comment and personality trait per image, How is it possible to get 5 different output for a single image, can someone please explain
The text was updated successfully, but these errors were encountered: