Weights protected under CC-By-NC license #198
Comments
|
Just a note about this question on a broader level: they might not be able to give you a better license depending on how permissive are their rights of the original music used to train this. In other words, maybe the music that trained this model cannot permit a better license. |
|
This is not possible, as mentioned by @rsxdalv the rights were negociated for a research purpose. |
|
@JadeCopet, how many tracks should I add to a dataset to make it useful? |
|
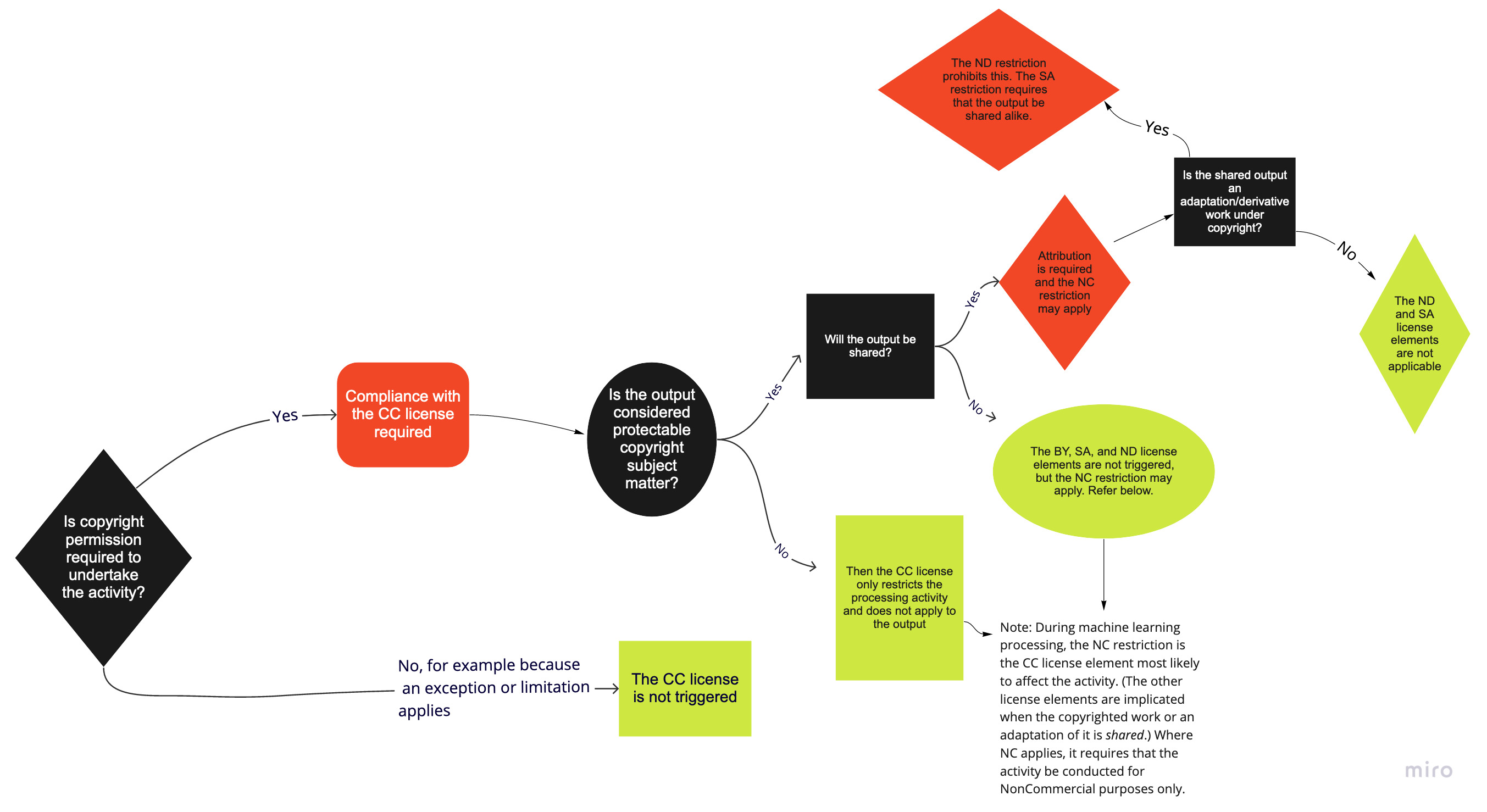
I should chime in here and say that the CC-BY-NC license isn't the same as other contract-like licenses that deal with generated outputs specifically (think Open RAIL-M). It would only likely deal with commercial use of the weights, not the generated output. The US Copyright Office has clarified that generations without sufficient human intervention (on the part of the end-user, not the creators of the model) from a machine learning-based system are de facto public domain. This distinction essentially means that the weights themselves cannot be used in a commercial setting, like for the purposes of running an ML-based music generation service. It does not prevent someone from generating outputs and then using those outputs commercially. In other words, the copyright status of a model and the output of said model are separate. Like the RAIL-M license, some newer "licenses" attempt to create a contract between the model distributor and the user to dictate what types of content can be generated and for which purposes. Considering this is wholly absent from CC-BY-NC, it seems valid to assume that generations created with Audiocraft are de facto public domain. Generating things with the model itself would not likely constitute commercial use unless the activity of generation itself (and not merely using the generations after the fact) constitutes commercial activity. Again, think of a person generating some samples for their music (commercial or otherwise) vs. someone generating music samples for paying customers online, in real time. Here's an official CC flowchart that illustrates this point. Note this section:
There's also a specific disclaimer about NC, but it basically reiterates what I said above: the NC restriction would apply to the generation phase, not to the output. In other words, if you're not generating for money while you're generating, then the output will likely not be subject to NC restrictions. This might even mean that samples could be sold after the fact, assuming you weren't generating them for cash during the runtime of the program (with the specific weights licensed under CC-BY-NC). I am not a lawyer or legal expert, and this is not legal advice. |
{kind=link}
|
I find it hard to agree with your assessment.
The information is good, but going from "require sufficient human input to
not be public domain" to a reduced "are basically public domain" assumes
that prompting AI is easy. And if it's not, what are the licensing terms?
Also, the link didn't about this ruling or guideline only opened the page
with many other links without a direct explanation.
The US ruling is also informative but again not conclusive - other
jurisdictions might go another way. (And there are incentives for them to
do so)
I understand your point, and it is true within this repository. Other
repositories or projects are not as lucky. NC can be extremely limited,
which also is the reason for questioning it, or even openly criticizing it.
Like, if you distribute them with your project (which does not require
money directly), a lawyer might still say that you are breaking the NC
clause, due to - advertising, association with other paid products etc etc.
Similarly, I've never heard of an SAAS loophole for NC because it's so
broad that it could easily be argued as a breach of license. Hence why I'm
far from saying that NC is safe from litigation if you accidentally
generated the next hit song.
Finally, the public domain aspect is also logical but flawed. Of course, if
copyright requires a human to be valid in a legal sense, AI cannot possess
it, though not all AI works start with clicking "generate". If I had a
special dataset of a 192kbps studio quality piano with thousands of hours
that I trained or fine tuned my AI on, it's not the same as someone using a
publicly available AI to generate a piano.
…On Wed, Nov 15, 2023, 1:44 PM EuphoricPenguin ***@***.***> wrote:
I should chime in here and say that the CC-BY-NC license isn't the same as
other contract-like licenses that deal with generated outputs specifically
(think Open RAIL-M
<https://www.licenses.ai/blog/2022/8/26/bigscience-open-rail-m-license>).
It would only likely deal with commercial use of the weights, not the
generated output. The US Copyright Office has clarified that generations
without sufficient human intervention (on the part of the end-user, not the
creators of the model) from a machine learning-based system are de facto
public domain <https://www.copyright.gov/ai/>. This distinction
essentially means that the weights themselves cannot be used in a
commercial setting, like for the purposes of running an ML-based music
generation service. It does not prevent someone from generating outputs and
then using those outputs commercially. In other words, the copyright status
of a model and the output of said model are separate. Like the RAIL-M
license, some newer "licenses" attempt to create a contract between the
model distributor and the user to dictate what types of content can be
generated and for which purposes. Considering this is wholly absent from
CC-BY-NC, it seems valid to assume that generations created with Audiocraft
are de facto public domain. Generating things with the model itself would
not likely constitute commercial use unless the activity of generation
itself (and not merely using the generations after the fact) constitutes
commercial activity.
*I am not a lawyer or legal expert, and this is not legal advice.*
—
Reply to this email directly, view it on GitHub
<#198 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ABTRXI7O6GM7PE5K24FM6PDYERJFLAVCNFSM6AAAAAA3GVJFWGVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTQMJRHA2DINZUGA>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
This isn't talking about the copyright of the model itself, but rather illustrating that the copyright status of generated works is independent of the license terms applied by the model. A derivative work of a de fecto public domain machine generated work can receive protection, but that is on the part of the user. Here's the original statement by the U.S. Copyright Office that I was attempting to refer to; it's referring specifically to copyright registry applications, but applies to copyright in general. This is because they're simply clarifying that, across the board, works created without sufficient human intervention are de facto public domain. On some level of post-processing, it might be possible to derive something that is protected from that public domain work. That's a separate issue, though, and the most important thing to note after all of this is that the copyright status of generations is independent of the model, and they are very likely to be public domain. Here's a news article about the same statement if you don't want to hunt for this quote, but essentially, text prompting, and even basic settings tweaking, is likely not enough for a work to receive protection.
Hypothetical laws/case law aren't laws/case law, and I'm focused on my immediate jurisdiction.
I think it's most important to point out that I never argued for this existence of a SAAS loophole, but rather was indicating that as a possible example of CC-BY-NC license violation. NC terms are confusing, and it was arguably a poor choice for a machine learning model. Still, I think your concerns about litigation for "marketing" are a bit overblown, considering (from my own rough understanding) that the NC part of the license is specifically referring to actual monetary gain received by the end-user. Whether samples generated using MusicGen are associated with a hit song or not, the legality status of those samples remains unchanged. I'll remind everyone again that this would apply at inference, and not to the final generations.
I'm not sure what you mean by this example. Both generations, without sufficient human intervention at inference, would produce de facto public domain works; that's precisely what I was referring to before. The copyright status of the database, model weights, or inference code is irrelevant. You might have your own copyright on the weights, but this has no impact on the copyright status of raw output, even when the model is prompted with text. This is specifically what the U.S. Copyright Office clarified. I am not a lawyer or legal expert, and this is not legal advice. |
|
"The EC concludes that the amount of free and creative choices made by a
human actor in the creative process of AI-assisted output should not be
underestimated. Therefore, these choices may contribute to the result of
an original work. An AI-assisted output could qualify as a work protected
by copyright if a human actor initiated and conceived the work and
subsequently redacted the output in a creative
manner."
https://www.gevers.eu/blog/artificial-intelligence/artificial-intelligence-ai-the-qualification-of-ai-creations-as-works-under-eu-copyright-law/#:~:text=The%20EC%20concludes,a%20creative%0Amanner
.
While EUs copyright stance seems similar, I would, with the quote above,
risk saying that it's not really "defacto public domain". To the point
that, sure, you might have some works that have different copyright levels
based on region (or more likely, everyone applies to EU copyright and then
uses it as a base).
And because it feels like I need to say this point again: yes, even without
Photoshopping the output, if you did something like intentionally combine
two LORAs and got something that you actually expected, I'd say you are
copyrightable within the EU.
As for the piano dataset example, I would point out that it's part of the
conception phase/preparation after conception, and directly supports the
intentionality of the output. But if you generated a drum and bass track
after making a piano model, it would be much more "dumb luck" and "black
box".
Meanwhile, I doubt midjourneys generations are copyrightable precisely
because of the limited options.
This is as far as I'll go. If you (and the US copyright office) see AI
tools as a magic black box that automatically get their outputs to be
public domain, sure.
As for the NC, there's a reason it's not used for software and related
components. Distributing NC copyrighted material isn't a walk in the park
legally. Developers do avoid it, especially if it's applied to source code.
…On Wed, Nov 15, 2023, 10:07 PM EuphoricPenguin ***@***.***> wrote:
I find it hard to agree with your assessment.
The information is good, but going from "require sufficient human input to
not be public domain" to a reduced "are basically public domain" assumes
that prompting AI is easy. And if it's not, what are the licensing terms?
Also, the link didn't about this ruling or guideline only opened the page
with many other links without a direct explanation.
This isn't talking about the copyright of the model itself, but rather
illustrating that the copyright status of generated works is independent of
the license terms applied by the model. A derivative work of a de fecto
public domain machine generated work can receive protection, but that is on
the part of the user.
Here's the original statement
<https://www.federalregister.gov/documents/2023/03/16/2023-05321/copyright-registration-guidance-works-containing-material-generated-by-artificial-intelligence>
by the U.S. Copyright Office that I was attempting to refer to; it's
referring specifically to copyright registry applications, but applies to
copyright in general. This is because they're simply clarifying that,
across the board, works created without sufficient human intervention are
de facto public domain. On some level of post-processing, it might be
possible to derive something that is protected from that public domain
work. That's a separate issue, though, and the most important thing to note
after all of this is that the copyright status of generations is
independent of the model, and they are very likely to be public domain. Here's
a news article about the same statement
<https://www.artnews.com/art-news/news/ai-generator-art-text-us-copyright-policy-1234661683/>
if you don't want to hunt for this quote, but essentially, text prompting,
and even basic settings tweaking, is likely not enough for a work to
receive protection.
The US ruling is also informative but again not conclusive - other
jurisdictions might go another way. (And there are incentives for them to
do so)
Hypothetical laws aren't laws, and I'm focused on my immediate
jurisdiction.
I understand your point, and it is true within this repository. Other
repositories or projects are not as lucky. NC can be extremely limited,
which also is the reason for questioning it, or even openly criticizing it.
Like, if you distribute them with your project (which does not require
money directly), a lawyer might still say that you are breaking the NC
clause, due to - advertising, association with other paid products etc etc.
Similarly, I've never heard of an SAAS loophole for NC because it's so
broad that it could easily be argued as a breach of license. Hence why I'm
far from saying that NC is safe from litigation if you accidentally
generated the next hit song.
I think it's most important to point out that I never argued for this
existence of a SAAS *loophole*, but rather was indicating that as a
possible example of CC-BY-NC license *violation*. NC terms are confusing,
and it was arguably a poor choice for a machine learning model. Still, I
think your concerns about litigation for "marketing" are a bit overblown,
considering (from my own rough understanding) that the NC part of the
license is specifically referring to actual monetary gain received by the
end-user. I'll remind everyone again that this would apply at inference,
and not to the final generations.
Finally, the public domain aspect is also logical but flawed. Of course, if
copyright requires a human to be valid in a legal sense, AI cannot possess
it, though not all AI works start with clicking "generate". If I had a
special dataset of a 192kbps studio quality piano with thousands of hours
that I trained or fine tuned my AI on, it's not the same as someone using a
publicly available AI to generate a piano.
I'm not sure what you mean by this example. Both generations, without
sufficient human intervention at inference, would produce de facto public
domain works; that's precisely what I was referring to before. The
copyright status of the database, model weights, or inference code is
irrelevant. You might have your own copyright on the weights, but this has
no impact on the copyright status of raw output, even when the model is
prompted with text. This is specifically what the U.S. Copyright Office
clarified.
—
Reply to this email directly, view it on GitHub
<#198 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ABTRXI47FQWJNEE7A5AZ2STYETEC3AVCNFSM6AAAAAA3GVJFWGVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTQMJSGU4TQOJQGU>
.
You are receiving this because you were mentioned.Message ID:
***@***.***>
|
Stable Diffusion is a bit of an outlier in terms of image generation, as a massive concerted community effort has essentially created a headache-inducing number of options that you can tweak to create very much original outputs. I've spent hours in A1111 myself, and I have no doubts most generations that aren't merely text prompts would be eligible for copyright protection. I don't think this extends to Audiocraft, however, since the only real driving force is a text prompt, and in the US, at least, that isn't enough to be subject to copyright protection. Again, this even sidesteps the issue of whether or not it really matters if it enters the public domain at this stage, considering it seems obvious that the actual copyright status of each generation is independent of the model. Still, I think it's easier to point out the legal reality of those initial generations being public domain, as it makes it easier to see where the CC-BY-NC restrictions of the model start (at runtime) and where they stop (in regards to generated output).
Unless a model overfits on the training data and accidentally generates something that is basically identical to the input audio, it's essentially irrelevant how the training dataset was assembled. If you own the rights to the training data, great, but holding those rights is not necessary to train a model that complies with copyright law. Again, if the output is distinct from the training data (which is what the goal is with any well-trained generative AI), the copyright status of the dataset is irrelevant to both the model weights and the final output.
I would agree in the case of Midjourney, which, as mentioned previously, is vastly different from running something like SD + A1111 locally. I think it's easy to see how Audiocraft's options are much closer to MJ than to A1111. Like I said before, my primary focus is on the US, but many of these concepts (like the aforementioned training data licensing) are treated similarly under EU law.
It's weird that a company as large as Meta wouldn't have found a better option for the model weights, as the license essentially applies no restrictions to the generated output. Some contract-like licenses do, but they seemed to have either ignored this distinction or assumed that the NC provisions were "good enough" to either scare off users who didn't know better or to thwart the efforts of commercial competitors (which it probably would for SAAS). Thankfully, for us users, the NC licenses simply can't apply to public domain outputs, and the CC-BY-NC license itself applies no restrictions on generated output. Another good thing is that Audiocraft's source code is MIT, so someone like the person earlier in the thread could embark on their own journey to train their own weights and still benefit from the underlying code. I am not a lawyer, and this is not legal advice. Talk to someone who knows what they're talking about if you need serious help. |
As mentioned the model weights are licensed under CC-By-NC license that prevents any commercial usage. Is there any way to employ the model weights for commercial usage, probably negotiating on a separate license or paying for appropriate royalties?
The text was updated successfully, but these errors were encountered: