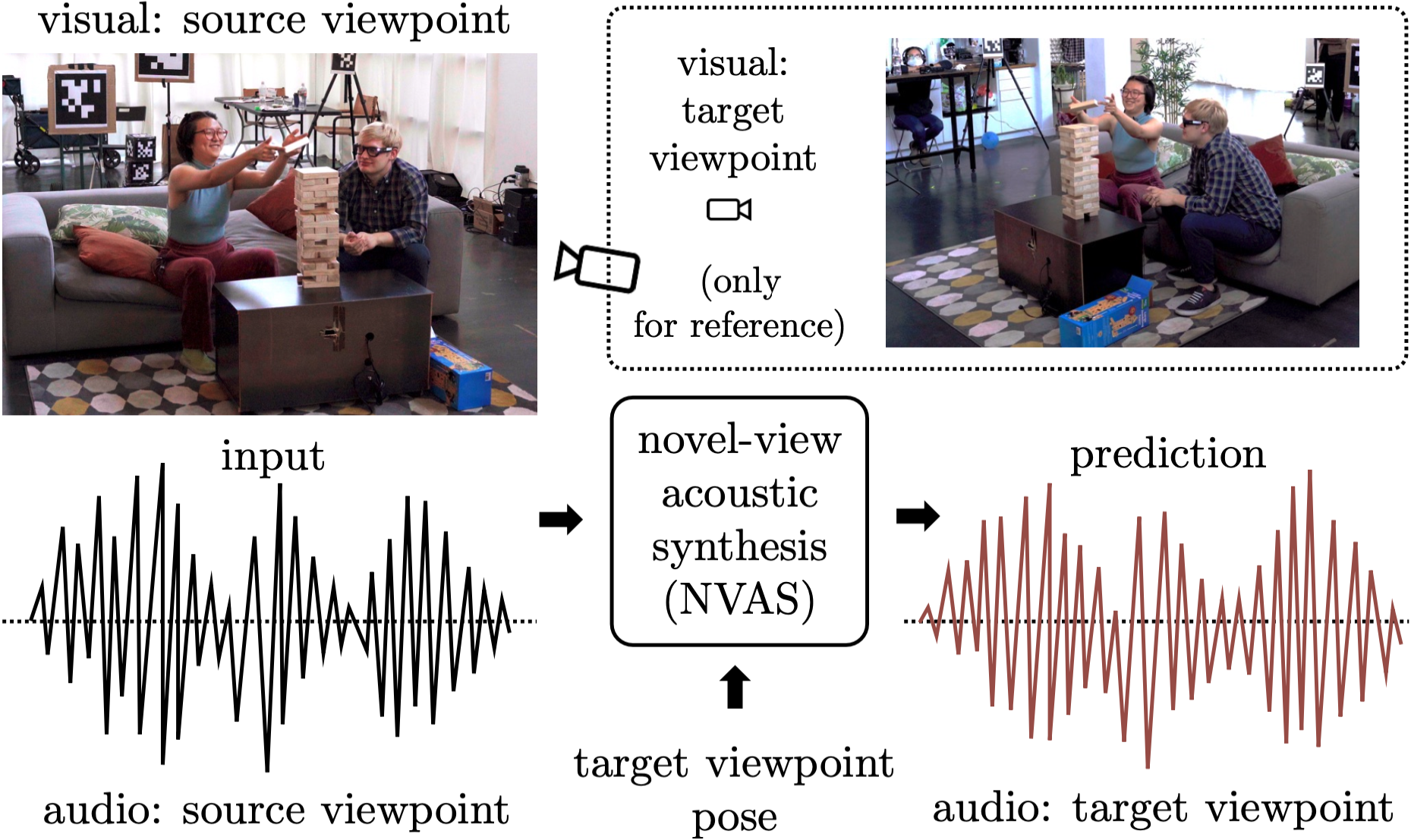
We introduce the novel-view acoustic synthesis (NVAS) task: given the sight and sound observed at a source viewpoint, can we synthesize the sound of that scene from an unseen target viewpoint? We propose a neural rendering approach: Visually-Guided Acoustic Synthesis (ViGAS) network that learns to synthesize the sound of an arbitrary point in space by analyzing the input audio-visual cues. To benchmark this task, we collect two first-of-their-kind large-scale multi-view audio-visual datasets, one synthetic and one real. We show that our model successfully reasons about the spatial cues and synthesizes faithful audio on both datasets. To our knowledge, this work represents the very first formulation, dataset, and approach to solve the novel-view acoustic synthesis task, which has exciting potential applications ranging from AR/VR to art and design. Unlocked by this work, we believe that the future of novel-view synthesis is in multi-modal learning from videos.
- Install this repo into pip by running the following command:
pip install -e .
This repo contains the code for the NVAS benchmark and our proposed model ViGAS.
- Training on SoundSpaces-NVAS
python nvas/trainer.py --version soundspaces_nvas --model vigas --dataset soundspaces_nvas --dataset-dir data/synthetic_dataset/v16 --num-channel 2 --n-gpus 1 --num-node 16 --num-worker 4 --batch-size 24 --gpu-mem32 --decode-wav --slurm --max-epochs 1000 --use-tgt-pose --use-tgt-rotation --encode-sincos --mag --one-speaker --auto-resume --audio-len 16000 --remove-delay --highpass-filter --use-rgb --remove-hyperconv --acausal --use-speaker-bboxes --metadata-file cleaned_metadata_v3.json --test --eval-best
- Training on Replay-NVAS
python nvas/trainer.py --version replay_nvas --model vigas --dataset replay_nvas --dataset-dir data/appen_dataset/v3 --num-channel 2 --n-gpus 8 --num-node 2 --num-worker 4 --batch-size 24 --gpu-mem32 --decode-wav --slurm --max-epochs 600 --mag --one-speaker --auto-resume --audio-len 16000 --highpass-filter --use-rgb --remove-hyperconv --acausal --use-speaker-bboxes --remove-delay --encode-sincos --use-tgt-pose --use-tgt-rotation --metadata-file metadata_v2.json --cam-position-file camera_positions_fixed_rotation.json --rotate-rel-pose
To test the model with the pretrained checkpoint, add the following flags to the training command:
--test --eval-best
Run the following script to download SoundSpaces-NVAS and Replay-NVAS:
bash download_data.sh
Note that the downloaded Replay data is for the NVAS task. To download the full Replay dataset, please refer to Replay.
See the CONTRIBUTING file for how to help out.
If you find the code, data, or models useful for your research, please consider citing the following paper:
@inproceedings{chen2023nvas,
title = {Novel-view Acoustic Synthesis},
author = {Changan Chen and Alexander Richard and Roman Shapovalov and Vamsi Krishna Ithapu and Natalia Neverova and Kristen Grauman and Andrea Vedaldi},
year = {2023},
booktitle = {CVPR},
}
This repo is CC-BY-NC 4.0 licensed, as found in the LICENSE file. It includes code from Binaural Speech Synthesis. See LICENSE-3RD-PARTY for their license.