{kind=link}
Download model from https://huggingface.co/fakezeta/openchat-3.5-0106-openvino-int8 in ir_model folder
1. Run interactive Q&A demo with Gradio:
$ python3 demo/qa_gradio.py -m "./ir_model" -d GPU
-d argument to select the default device: depending on your hardware may be one of these. Can be changed runtime with the dropdown menu widget.
This sample shows how to implement OpenChat model with OpenVINO runtime.
Only qa_gradio.py and relevant model.py has been adapted because the goal was to benchmark iGPU performance vs CPU vs other iGPU backends.
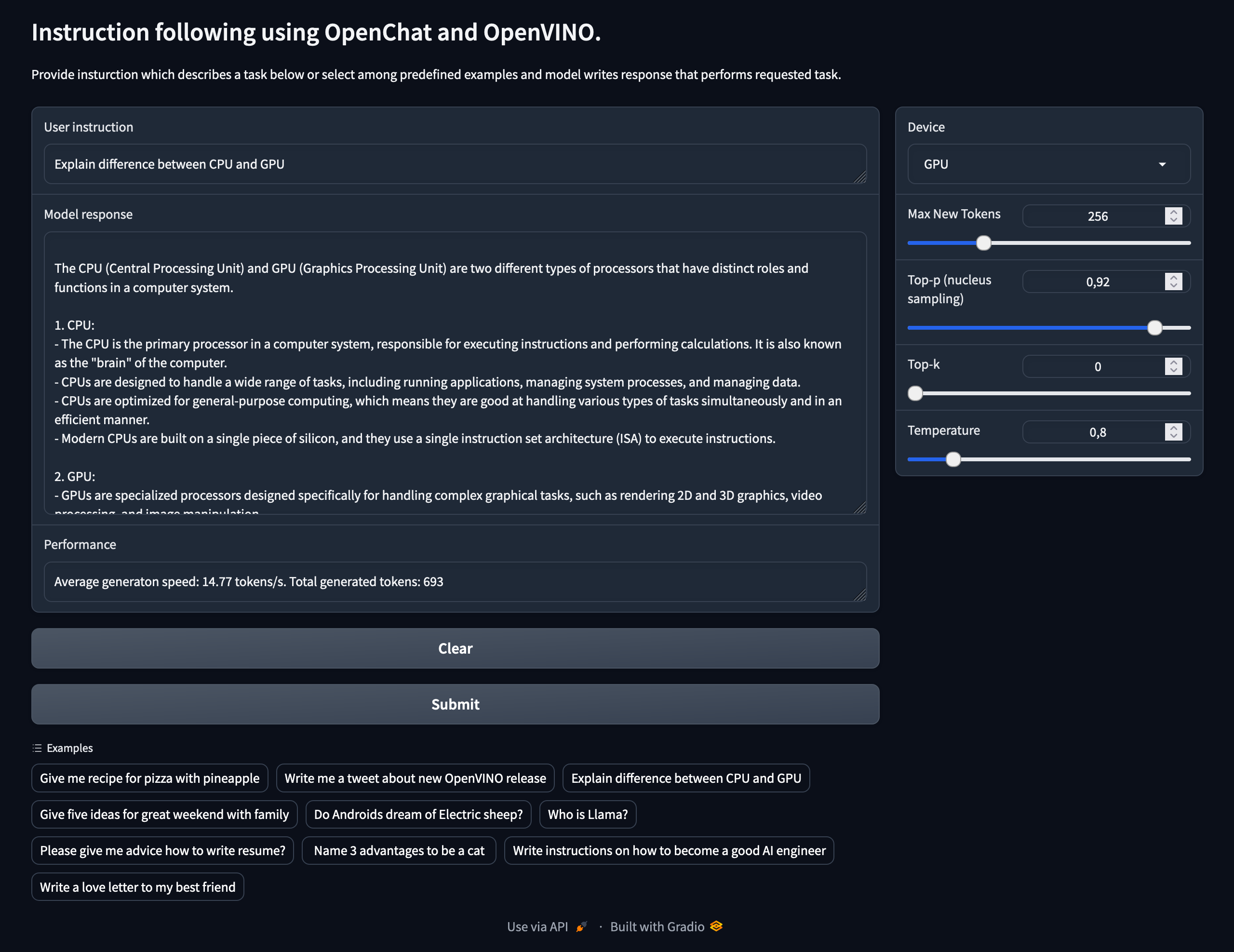
Following the original README from OpenVINO-dev-contest/llama2.openvino
-
Please follow the Licence on HuggingFace and get the approval from Meta before downloading llama checkpoints, for more information
-
Please notice this repository is only for a functional test and personal study.
- Linux, Windows
- Python >= 3.9.0
- CPU or GPU compatible with OpenVINO.
- RAM: >=16GB
- vRAM: >=8GB
$ python3 -m venv openvino_env
$ source openvino_env/bin/activate
$ python3 -m pip install --upgrade pip
$ pip install wheel setuptools
$ pip install -r requirements.txt
1. Export IR model
from Transformers:
$ python3 export_ir.py -m 'meta-llama/Llama-2-7b-hf'
or from Optimum-Intel:
$ python3 export_op.py -m 'meta-llama/Llama-2-7b-hf'
or for #GPTQ model:
$ python3 export_op.py -m 'TheBloke/Llama-2-7B-Chat-GPTQ'
1.1. (Optional) quantize local IR model with #int8 or #int4 weight
$ python3 quantize.py -m 'ir_model' -p 'int4'
For more information on quantization configuration, please refer to weight compression
2. Run pipeline
Optimum-Intel OpenVINO pipeline:
$ python3 ir_pipeline/generate_op.py -m "./ir_model" -p "what is openvino ?" -d "CPU"
or Restructured pipeline:
$ python3 ir_pipeline/generate_ir.py -m "./ir_model" -p "what is openvino ?" -d "CPU"
1. Run interactive Q&A demo with Gradio:
$ python3 demo/qa_gradio.py -m "./ir_model"
2. or chatbot demo with Streamlit:
$ python3 export_op.py -m 'meta-llama/Llama-2-7b-chat-hf' -o './ir_model_chat'
$ streamlit run demo/chat_streamlit.py -- -m './ir_model_chat'