Visualizing yelp challeng's data with Shiny!
Live Demo • Getting started • Idioms • Authors
The aim of this project is to develop an interactive visualization tool going trough all the design abstraction levels needed to properly structure a complex visualization project.
The easyest way to get a grasp on what the project does is to look at our live demo.
We suggest you to install RStudio.
Once installed you can easily install shiny issuing the following command in RStudio console:
> install.packages("shiny")The dataset used is the yelp visualization challenge dataset which collects various informations about businesses around the world and check-in events generated by users.
Good visualization are aimed to answer defined questions. For this reason we selected some interesting questions concerning the dataset:
- How are the business geographically distributed?
- What is the distribution of review score on a determined geography? Are there areas that are more "picky"?
- Is there a relationship between the number of check-in and the number of reviews?
- Which is the relationship between the most common business cate- gories?
- In which time of the day the customer check-in? Does it coincides with the opening hours?
- Is it true that different categories have different opening hours? Like bars opens until late and restaurants close sooner.
The project implements various idioms (plots) in different tabs.
The map tab aims to answer the first three questions. For that reason we used facetig of multiple idioms. A choroplet map for the geographical distribution of the businesses, an histogram of the review score and a scatter plot between the logarithm of the number of reviews and the number of check-in.
Businesses can be filtered by review score and the size and color of the bubbles can encode different values.
All the idioms are coordinated, as can be seen in the following demo:

We represented the relationship between the businesses categories as a network, having as nodes the names of the categories and a link every time two categories appears in the same business. The weight associated to link will increase each time the link appears in the dataset. Being inspired by the "les miserables" co-occurrence adiacency matrix, we decided to use the same idiom. The user will be able to manipulate the view by selecting the sorting criteria of the matrix by name of category, frequency and cluster.
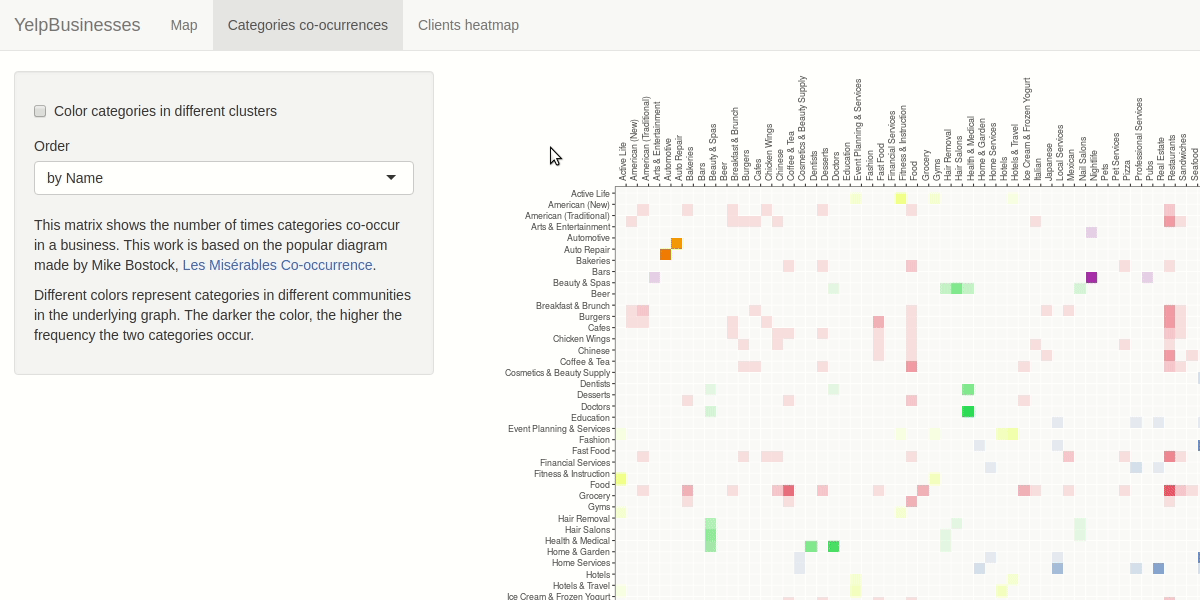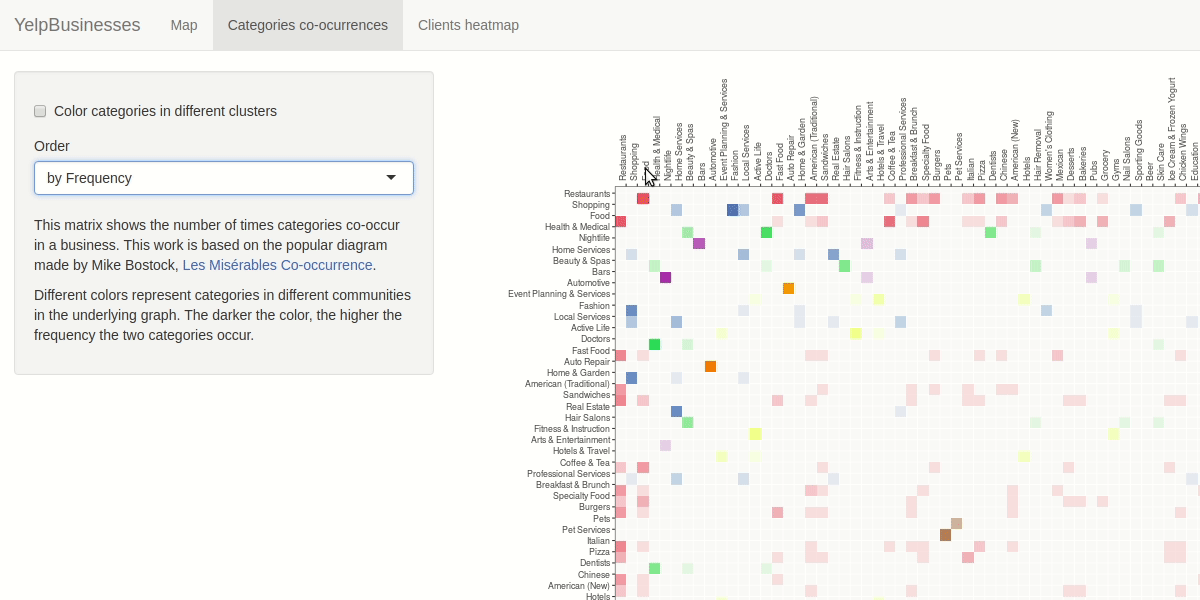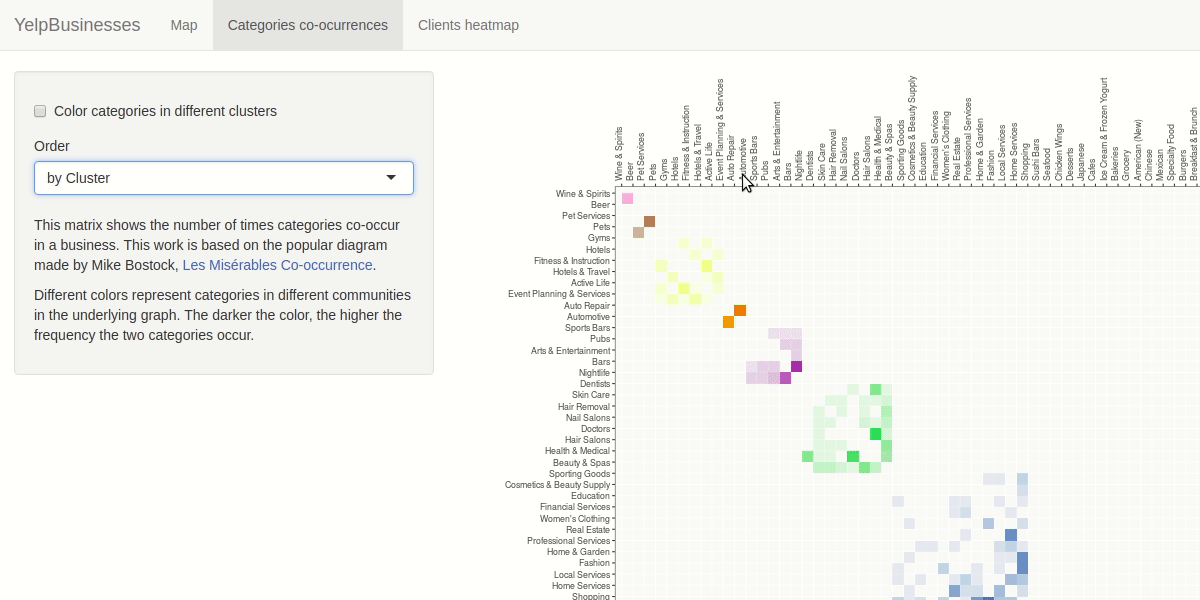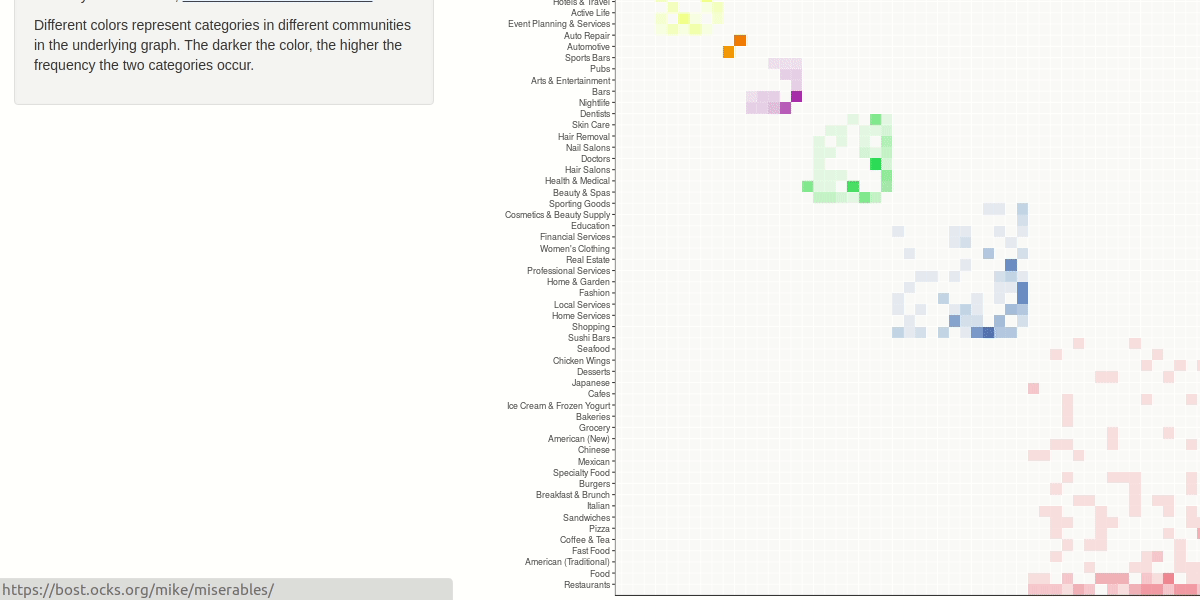
For investigating the similarities between check-in hours and opening hours we decided to apply some aggregation building two matrix with day of the week and hour as rows and columns index. We calculated a scalar field where each cell rapresent the number of check-in in that hour/day and the number of business open in that hour/day. The user have the capability to filter by selecting the category to analyze. We choose a purely sequential colormap without a central reference. The user is also be able to apply smoothing to the heat map to ease the detection of particular patterns, like you can see in the demo below.
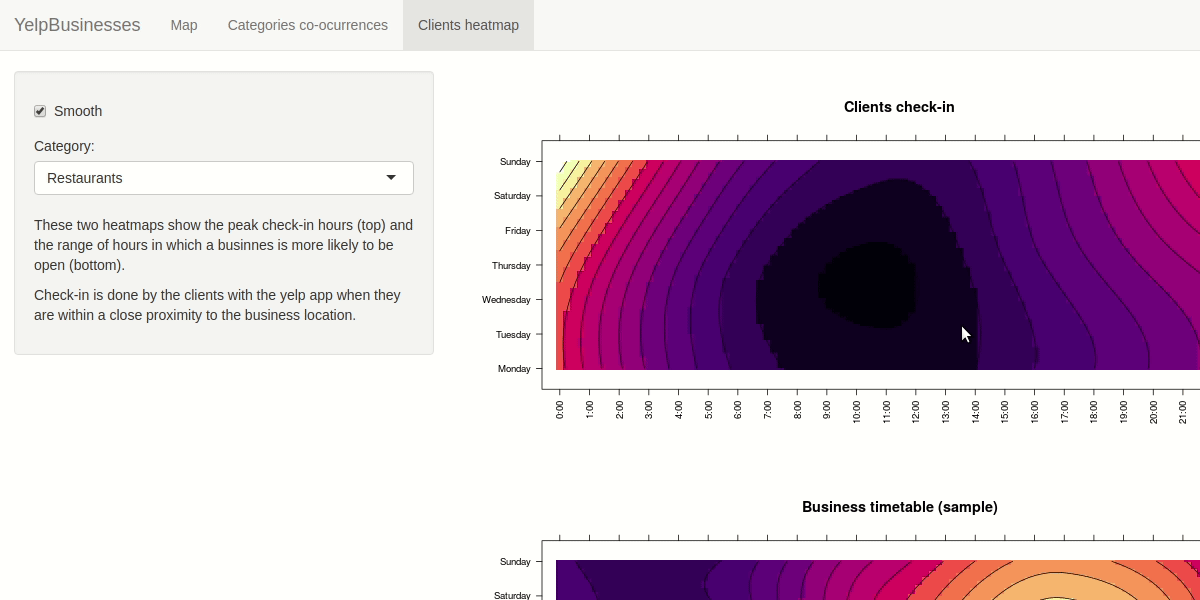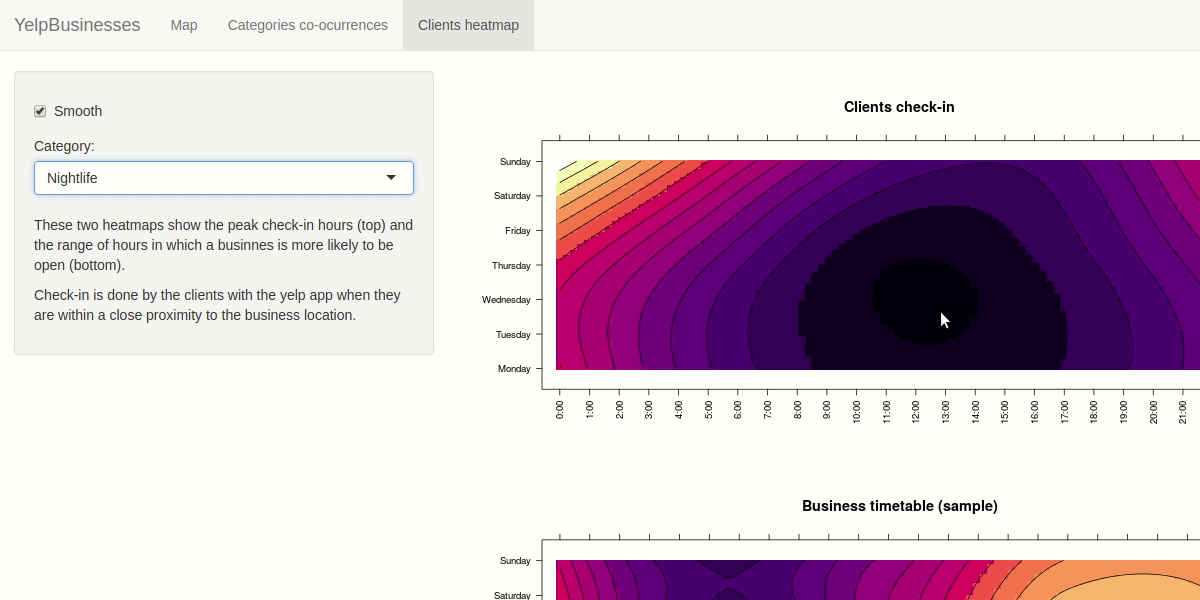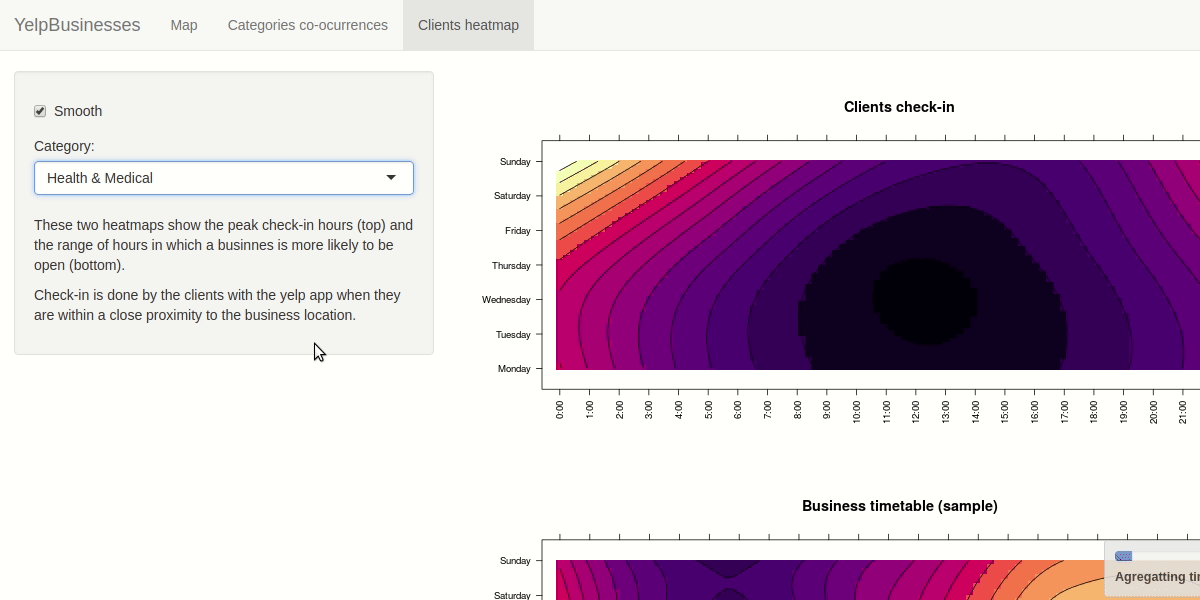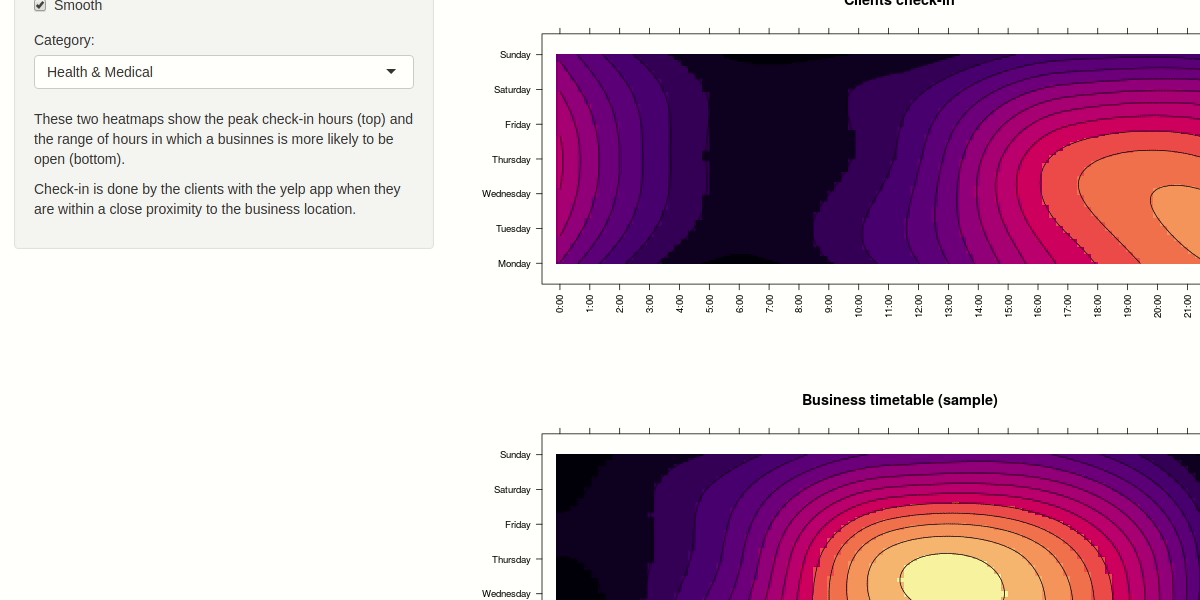
In case you want to learn more about the design decisions taken and the selection of the idioms used we seggest you to read the report we redacted.
- Fernando Díaz
- Giorgio Ruffa