Tensor Fox is a high performance package of multilinear algebra and tensor routines, with focus on the Canonical Polyadic Decomposition (CPD), also called PARAFAC or CANDECOMP. We recommend the wikipedia article for a introduction to this decomposition. In this package you will find an efficient CPD solver, a great variety of parameters for fine tuning, support to sparse tensors, routines to test models and tensor behavior, rank estimate, statistics, and many more!
- 🦊 Motivation
- 🦊 Getting Started
- 🦊 Performance
- 🦊 Structure of Tensor Fox
- 🦊 About Sparse Dot MKL
- 🦊 Author
- 🦊 License
- 🦊 References
Multidimensional data structures are common these days, and extracting useful information from them is crucial for several applications. For bidimensional data structures (i.e., matrices), one can rely on decompositions such as the Singular Value Decomposition (SVD) for instance. There are two possible generalizations of the SVD for multidimensional arrays of higher order: the multilinear singular value decomposition (MLSVD) and the canonical polyadic decomposition (CPD). The former can be seen as a PCA of higher order and is useful for dimensionality reduction, whereas the latter is useful to detect latent variables. Computing the MLSVD is just a matter of computing several SVD's, but the CPD is a challenging problem.
Determinating the rank of a tensor is a NP-hard problem, so the best option is to rely on heuristics, guessing and estimate. Although the value of the rank is a hard task, once we have its value or a reasonable estimate, computing an approximated CPD is a polynomial task. There are several implementations of algorithms to compute a CPD, but most of them relies on the alternating least squares (ALS) algorithm, which is cheap to compute but has severe convergence issues. Algorithms like the damped Gauss-Newton (dGN) are more robust but in general are much more costly. Tensor Fox is a CPD solver for Python (with Numpy and Numba as backend) which manages to use the dGN algorithm plus the Tensor Train Decomposition in a cheap way, being robust while also being competitive with ALS in terms of speed. Furthermore, Tensor Fox offers several additional multilinear algebra routines.
Installing with pip
The only pre-requisite is to have Python 3 installed. After this you just need to run the following command within your env:
pip install TensorFox
The package sparse_dot_mkl won't work properly with pip (we explain in more detail at the end of this text). This package is responsible for accelerating a few matrix multiplications. Tensor Fox still works without this package but it will use Scipy dot instead. I recommend installing Miniconda and then create an env with the following:
conda create --name tfx_env --channel defaults jupyter numpy pandas scipy scikit-learn matplotlib numba IPython sparse_dot_mkl
After this you may install TensorFox and everything will be fine. The channel must be defaults, otherwise Numpy won't be linked against MKL (see https://numpy.org/install/), which is necessary to work with sparse_dot_mkl. Finally, note that jupyter is optional, only if you want to work with jupyter notebooks.
Let's start importing Tensor Fox and other necessary modules.

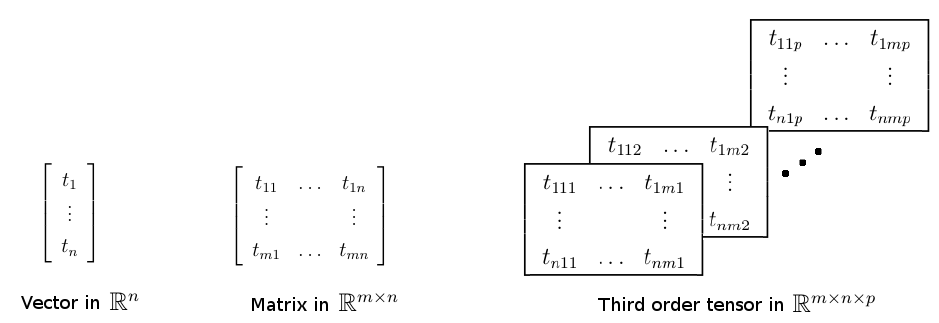
We will create a little tensor T just to see how Tensor Fox works at its basics. Consider the tensor defined below (the frontal slices of T are shown).


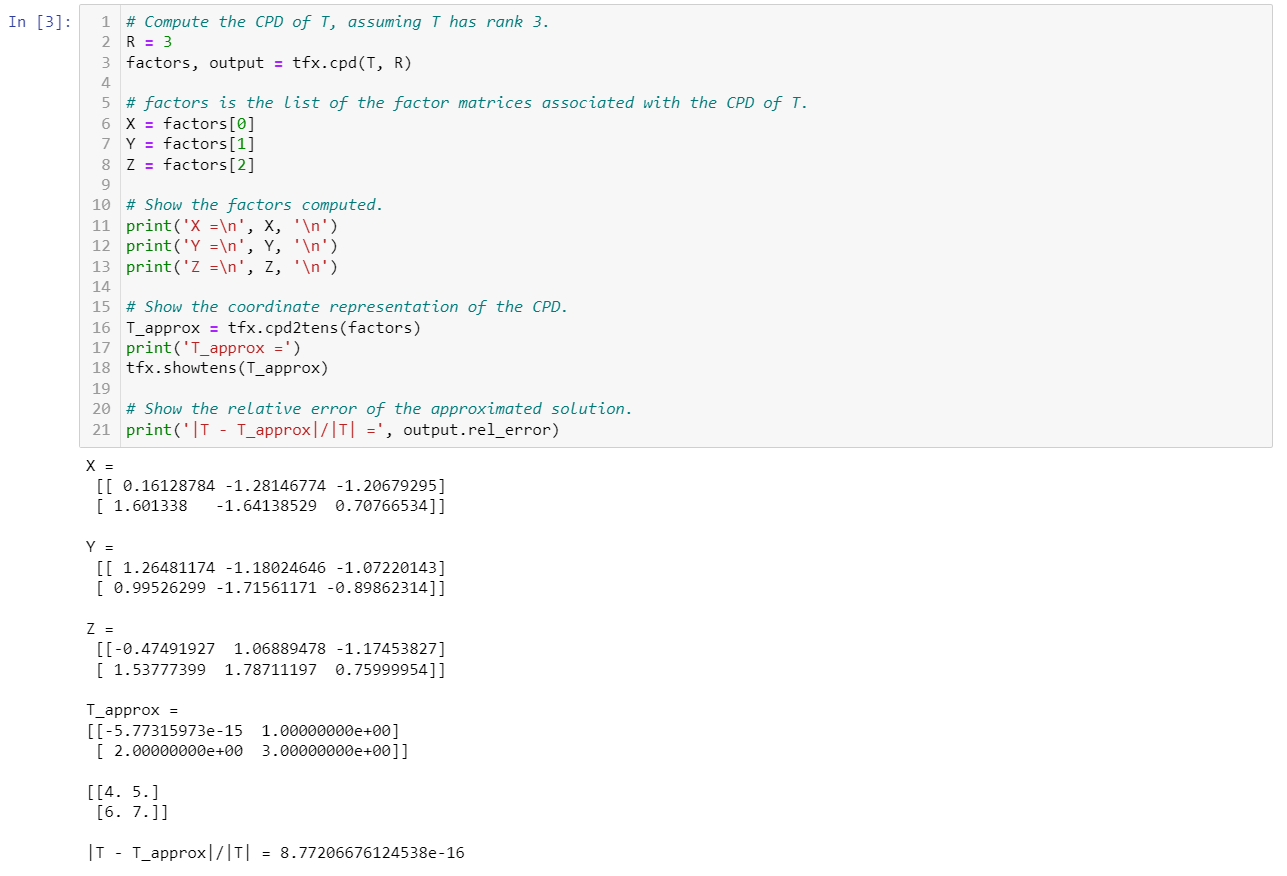
Now let's turn to the most important tool of Tensor Fox, the computation of the CPD. We can compute the corresponding CPD simply calling the function cpd with the tensor and the rank as arguments. This is just the tip of the iceberg of Tensor Fox, to know more check out the tutorial and the examples of applications.
In the following we compare the performances of Tensor Fox and other known tensor packages: Tensorlab (version 3.0), Tensor Toolbox (version 3.1), Tensorly and TensorBox. Our first benchmark consists in measuring the effort for the other solvers to obtain a solution close to the Tensor Fox default. We compute the CPD of four fixed tensors:
-
Swimmer: This tensor was constructed in this tutorial lesson. It is a set of 256 images of dimensions 32 x 32 representing a swimmer. Each image contains a torso (the invariant part) of 12 pixels in the center and four limbs of 6 pixels that can be in one of 4 positions. We proposed to use a rank R = 50 tensor to approximate it.
-
Handwritten digits: This is a classic tensor in machine learning, it is the MNIST database of handwritten digits. Each slice is a image of dimensions 20 x 20 of a handwritten digit. Also, each 500 consecutive slices correspond to the same digit, so the first 500 slices correspond to the digit 0, the slices 501 to 1000 correspond to the digit 1, and so on. We choose R = 150 as a good rank to construct the approximating CPD to this tensor. This tensor is also used here, where we present a tensor learning technique for the problem of classification.
-
Border rank: The phenomenon of border rank can make the CPD computation a challenging problem. The article [1] has a great discussion on this subject. In the same article they show a tensor of rank 3 and border rank 2. We choose to compute a CPD of rank R = 2 to see how the algorithms behaves when we try to approximate a problematic tensor by tensor with low rank. In theory it is possible to have arbitrarily good approximations.
-
Matrix multiplication: Matrix multiplication between square n x n matrices can be seen as a tensor of shape n² x n² x n². Since Strassen it is known that these multiplications can be made with less operations. For the purpose of testing we choose the small value n = 5 and the rank R = 92. However note that this is probably not the exact rank of the tensor (it is lower), so this test is about a strict low rank approximation of a difficult tensor.
PS: Tensor Fox relies on Numba, which makes compilations just in time (JIT). This means that the first run will compile the functions and this take some time. From the second time on there is no more compilations and the program should take much less time to finish the computations. Any measurement of performance should be made after the compilations are done. Additionally, be warned that changing the order of the tensor, the method of initialization or the method of the inner algorithm also triggers more compilations. Before running Tensor Fox for real we recommend to run it on a small tensor, just to make the compilations.
For each tensor we compute the CPD of TFX with default maximum number of iterations 100 times and retain the best result, i.e., the CPD with the smallest relative error. Let err be this error. Now let ALG be any other algorithm implemented by some of the mentioned libraries. We set the maximum number of iterations to maxiter, keep the other options with their defaults, and run ALG with these options 100 times. The only accepted solutions are the ones with relative error smaller that err + err/100. Between all accepted solutions we return the one with the smallest running time. If none solution is accepted, we increase maxiter by a certain amount and repeat. We try the values maxiter = 5, 10, 50, 100, 150, ..., 900, 950, 1000, until there is an accepted solution. The running time associated with the accepted solution is the accepted time. These procedures favour all algorithms against TFX since we are trying to find a solution close to the solution of TFX with the minimum number of iterations. We remark that the iteration process is always initiated with a random point. The option to generate a random initial point is offered by all libraries, and we use each one they offer (sometimes random initialization was already the default option). There is no much difference in their initializations, which basically amounts to draw random factor matrices from the standard Gaussian distribution. The time to perform the MLSVD or any kind of preprocessing is included in the time measurements.
We are using the following algorithms in this benchmark:
- NLS: Tensorlab NLS without refinement
- NLSr: Tensorlab NLS with refinement
- Tlab-ALS: Tensorlab ALS withou refinement
- Tlab-ALSr: Tensorlab ALS with refinement
- MINF: Tensorlab MINF without refinement
- MINFr: Tensorlab MINF with refinement
- Tly-ALS: Tensorly ALS
- OPT: Tensor Toolbox OPT (with 'lbfgs' algorithm)
- fLMA: TensorBox fast Levenberg-Marquardt algorithm.
The first round of our benchmarks is showed below.

Now we consider another round of tests, but instead of fixed tensors we use a family of tensors. More precisely, we consider random tensors of shape n x n x ... x n and rank R = 5, where the entries of each factor matrix are drawn from the normal distribution (mean 0 and variance 1). First we consider fourth order tensors with shape n x n x n x n, for n = 10, 20, 30, 40, 50, 60, 70, 80. Since the Tensorlab's NLS performed very well in the previous tests, we use only this one for Tensorlab and start with this algorithm, making 20 computations for each dimension n and averaging the errors and time. After that we run the other algorithms adjusting their tolerance in order to match the NLS results.
In all tests we tried to choose the options in order to speed up the algorithms without losing accuracy. For example, we noticed that it was unnecessary to use compression, detection of structure and refinement for the NLS algorithm. These routines are very expensive and didn't bring much extra precision, so they were disabled in order to make the NLS computations faster. Similarly we used the initialization 'svd' for Tensorly because it proved to be faster than 'random', and we used the algorithm 'lbfgs' for Tensor Toolbox OPT. Finally, for Tensor Fox we just decreased its tolerance in order to match the precision given by the NLS algorithm. The results are showed below.

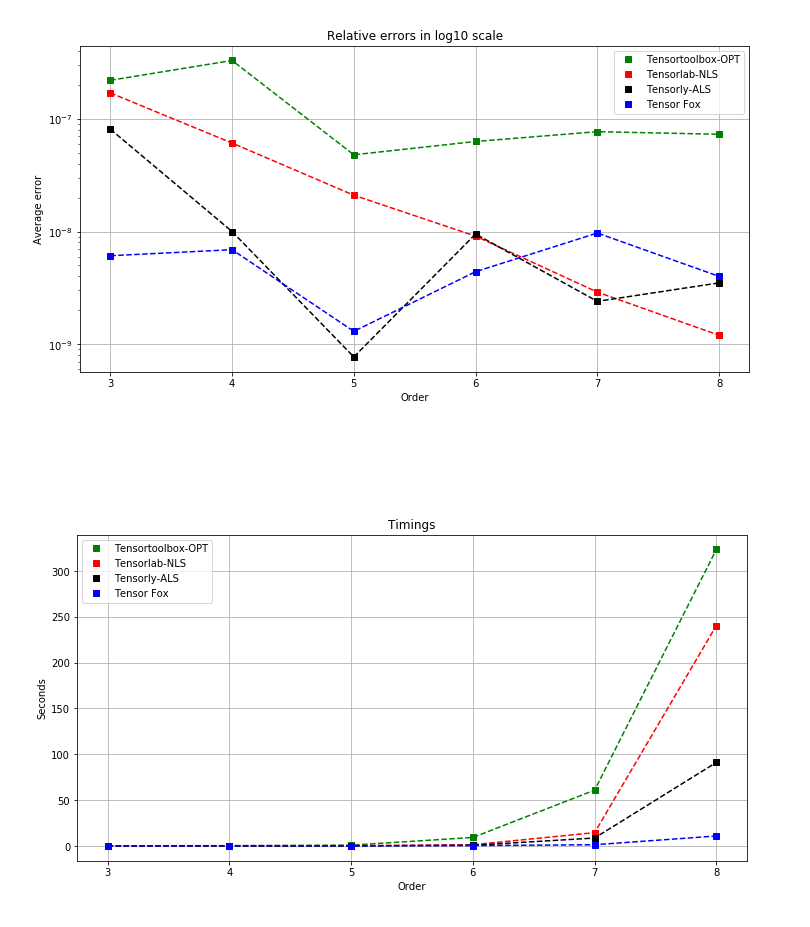
Next, we make the same procudure but this time we fixed n to n = 10 and increased the order, from order 3 to 8. These last tests shows an important aspect of Tensor Fox: it avoids the curse of dimensionality, whereas the other algorithms still suffers from that. We consider random rank-5 tensors of shape 10 x 10 x 10, them 10 x 10 x 10 x 10, up to tensors of order 8, i.e., with shape 10 x 10 x 10 x 10 x 10 x 10 x 10 x 10, with the same distribution as before. For anyone interested in reproducing these tests, it is possible to generate these tensors with the command tfx.gen_rand_tensor(dims, R).
In this section we summarize all the features Tensor Fox has to offer. As already mentioned, computing the CPD is the main goal of Tensor Fox, but in order to accomplish this goal several 'sub-goals' had to be overcome first. Many of these sub-goals ended up being important routines of multilinear algebra. Besides that, during the development of this project several convenience routines were added, such as statistics analysis of tensors, rank estimation, automated plotting with CPD information, and many more. Below we present the modules of Tensor Fox and gives a brief description of their main functions.
| TensorFox | |
|---|---|
| cpd | computes the CPD of a tensor T with rank R. |
| rank | estimates the rank of a tensor. |
| stats | given a tensor T and a rank R, this function computes some statistics regarding the CPD computation. |
| foxit | does the same job as the cpd function but at the end it prints and plots relevant information. |
| Auxiliar | |
|---|---|
| tens2matlab | given a tensor, this function saves the tensor in Matlab format file. |
| gen_rand_tensor | this function generates a random tensor with standard Gaussian distribution. |
| gen_rand_sparse_tensor | this function generates a sparse random tensor with standard Gaussian distribution. |
| Compression | |
|---|---|
| mlsvd | computes the MLSVD of a tensor. |
| test_truncation | this function test one or several possible truncations for the MLSVD of T, showing the error of the truncations. |
| Conversion | |
|---|---|
| cpd2tens | converts the factor matrices to the corresponding tensor in coordinate format. |
| cpd2sparsetens | same as cpd2tens but for sparse tensors. |
| sparse2dense | given the variables defining a sparse tensor, this function computes its dense representation. |
| dense2sparse | given a dense tensor, this function generates its sparse representation. |
| unfold | given a tensor and a mode, this function computes the unfolding of the tensor with respect of that mode. |
| sparse_unfold | given a sparse tensor and a mode, this function computes the sparse unfolding of the tensor with respect of that mode. |
| foldback | given a matrix representing a unfolding of some mode and the dimensions of the original tensor, this function retrieves the original tensor from its unfolding. |
| normalize | normalize the columns of the factors to have unit column norm and introduce a central tensor with the scaling factors. |
| denormalize | given the normalized factors together with a central tensor, this function retrives the non-normalized factors. |
| equalize | make the vectors of each mode to have the same norm. |
| change_sign | after the CPD is computed it may be interesting that each vector of a rank one term is as positive as possible, in the sense that its mean is positive. If two vectors in the same rank one term have negative mean, then we can multiply both by -1 without changing the tensor. |
| Critical | |
|---|---|
| this module responsible for the most costly parts of Tensor Fox (basically it is a module with a bunch of loops) |
| Display | |
|---|---|
| infotens | display several informations about a given tensor. |
| rank1_plot | this function generates an image with the frontal sections of all rank one terms (in coordinates) of some CPD. |
| rank_progress | plots the partial sums of rank one terms corresponding to the k-th slice of the CPD. The last image should match the original CPD. |
| test_tensors | a function made specifically to test different models against different tensors. It is very useful when one is facing difficult tensors and needs to tune the parameters accordingly. |
| GaussNewton | |
|---|---|
| dGN | damped Gauss-Newton function adapted for the tensor problem.. |
| cg | conjugate gradient function adapted for the tensor problem. |
| regularization | computes the Tikhonov matrix for the inner algorithm. |
| precond | computes the preconditioner matrix for the inner algorithm. |
| Initialization | |
|---|---|
| starting_point | main function to generates the starting point. There are four possible methods of initialization, 'random', 'smart_random', 'smart', or you can provide your own starting point as a list of the factor matrices. |
| MultilinearAlgebra | |
|---|---|
| multilin_mult | performs the multilinear multiplication. |
| sparse_multilin_mult | performs the sparse multilinear multiplication. |
| multirank_approx | given a tensor T and a prescribed multirank (R1, ..., Rm), this function tries to find the (almost) best approximation of T with multirank (R1, ..., Rm). |
| kronecker | computes the Kronecker product between two matrices. |
| khatri_rao | computes the Khatri-Rao product between two matrices. |
| hadamard | computes the Hadamar product between two matrices. |
| cond | computes the geometric condition number of the factor matrices of some CPD. |
| rank1_terms_list | computes each rank 1 term, as a multidimensional array, of the CPD. |
| forward_error | let T = T_1 + T_2 + ... + T_R be the decomposition of T as sum of rank-1 terms and let T_approx = T_approx_1 + T_approx_2 + ... + T_approx_R be the decomposition of T_approx as sum of R terms. Supposedly T_approx were obtained after the cpd function. The ordering of the rank-1 terms of T_approx can be permuted freely without changing the tensor. While |
Sparse Dot MKL is a wrapper for the sparse matrix multiplication in the intel MKL library. This package is used by Tensor Fox when computing the SVD of large sparse matrices. In the case this package is not installed properly, Scipy routines will be used instead.
This package requires the MKL runtime linking library libmkl_rt.so (or libmkl_rt.dylib for OSX, or mkl_rt.dll for WIN). If the MKL library cannot be loaded an ImportError will be raised when the package is first imported. MKL is distributed with the full version of conda, and can be installed into Miniconda with conda install -c intel mkl. Alternatively, you may add need to add the path to MKL shared objects to LD_LIBRARY_PATH (e.g. export LD_LIBRARY_PATH=/opt/intel/mkl/lib/intel64:$LD_LIBRARY_PATH). There are some known bugs in MKL v2019 which may cause intermittent segfaults. Updating to MKL v2020 is highly recommended if you encounter any problems.
It is possible to experience failure in the computations due to the environment variable MKL_INTERFACE_LAYER being differente than ILP64. In some machines this warning can be triggered even when this variable is correct (check this with os.getenv("MKL_INTERFACE_LAYER")). If this happens, a workaround is to change the line
int_max = np.iinfo(MKL.MKL_INT_NUMPY).max
to
int_max = np.iinfo(np.int64).max
in sparse_dot_mkl._mkl_interface._check_scipy_index_typing. If this is too complicated, set mkl_dot to False (see this tutorial for more about this option). In this case Tensor Fox will detect this and use only Scipy routines for sparse matrices.
- Felipe B. Diniz: https://github.com/felipebottega
- Contact email: felipebottega@gmail.com
- Linkedin: https://www.linkedin.com/in/felipe-diniz-4a212163/?locale=en_US
- Kaggle: https://www.kaggle.com/felipebottega
This project is licensed under the GNU GENERAL PUBLIC LICENSE - see the LICENSE.md file for details.
- V. de Silva, and L.-H. Lim, Tensor Rank and the Ill-Posedness of the Best Low-Rank Approximation Problem, SIAM Journal on Matrix Analysis and Applications, 30 (2008), pp. 1084-1127.
- P. Comon, X. Luciani, and A. L. F. de Almeida, Tensor Decompositions, Alternating Least Squares and other Tales, Journal of Chemometrics, Wiley, 2009.
- T. G. Kolda and B. W. Bader, Tensor Decompositions and Applications, SIAM Review, 51:3, in press (2009).
- J. M. Landsberg, Tensors: Geometry and Applications, AMS, Providence, RI, 2012.
- B. Savas, and Lars Eldén, Handwritten Digit Classification Using Higher Order Singular Value Decomposition, Pattern Recognition Society, vol. 40, no. 3, pp. 993-1003, 2007.
- C. J. Hillar, and L.-H. Lim. Most tensor problems are NP-hard, Journal of the ACM, 60(6):45:1-45:39, November 2013. ISSN 0004-5411. doi: 10.1145/2512329.
- A. Shashua, and T. Hazan, Non-negative Tensor Factorization with Applications to Statistics and Computer Vision, Proceedings of the 22nd International Conference on Machine Learning (ICML), 22 (2005), pp. 792-799.
- S. Rabanser, O. Shchur, and S. Günnemann, Introduction to Tensor Decompositions and their Applications in Machine Learning, arXiv:1711.10781v1 (2017).
- A. H. Phan, P. Tichavsky, and A. Cichoki, Low Complexity Damped Gauss-Newton Algorithm for CANDECOMP/PARAFAC, SIAM Journal on Matrix Analysis and Applications, 34 (1), 126-147 (2013).
- L. De Lathauwer, B. De Moor, and J. Vandewalle, A Multilinear Singular Value Decomposition, SIAM J. Matrix Anal. Appl., 21 (2000), pp. 1253-1278.
- F. Bottega Diniz, PhD Thesis, https://www.pgmat.im.ufrj.br/index.php/pt-br/teses-e-dissertacoes/teses/2019-1/281-tensor-decompositions-and-algorithms-with-applications-to-tensor-learning/file
- Tensorlab - https://www.tensorlab.net/
- Tensor Toolbox - http://www.sandia.gov/~tgkolda/TensorToolbox/
- Tensorly - https://github.com/tensorly/
- TensorBox - https://github.com/phananhhuy/TensorBox