Flashlight MLP is much slower than Jax+Jit python implementation #898
Labels
question
Further information is requested
Comments
|
This isn't surprising. The ArrayFire CPU backend is single-threaded and not optimized for performance -- it hardly JITs computations and primarily exists as a debugging tool. While the ArrayFire OpenCL backend is better (uses a JIT and some async/parallel computation), CPU performance may still be underwhelming, and it isn't properly supported at the moment in Flashlight. We're currently developing a CPU backend based on Intel's oneDNN library which should significantly improve performance (and will also enable proper interoperability with the ArrayFire OpenCL backend). Stay tuned for updates -- commits on that backend will appear in cc @StrongerXi, who's adding this. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Question
Since both flashlight and jax are proposed for high performance and easy low-level ops implementation, it is desired to compare them. I simply tried a compiled MLP model (
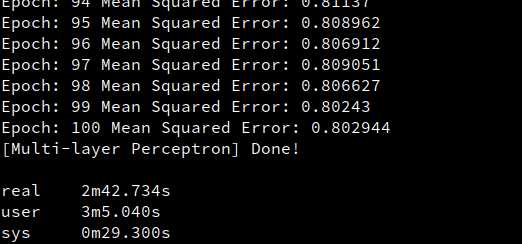
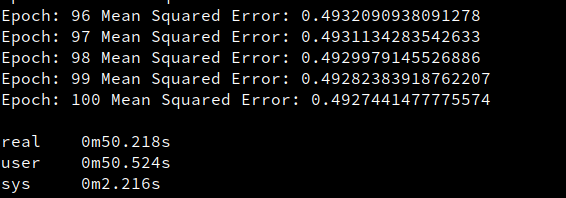
flashlight/fl/examples/Perceptron.cpp) and reproduced Jax+Flax+Jit python MLP. The results show that Flashlight is much slower than Jax.Additional Context
All tests are conducted on a CPU-only machine.
Flashlight:
Jax:
Htop monitor:

Click to toggle contents of `test_jax_mlp.py`
The text was updated successfully, but these errors were encountered: