Participación en la competición organizada por Cajamar (2017)
Hackathon creado por Cajamar y Microsoft, dónde se formó el grupo de trabajo WorkingData, formado por Francisco Javier Vílchez, Raúl Lopez y David Jiménez.
Mediante la senda de contratación histórica del cliente en la Entidad, podrás analizar sus contrataciones habituales con el objetivo de ver quiénes son, qué productos se venden conjuntamente, y cuáles son los siguientes productos a contratar.
Se parte de una cesta de productos inicial y el resultado será una serie de productos a contratar, que conformará la cesta futura.
El análisis de la cesta de productos permite optimizar las estrategias de Cross y Up Selling.
Se debe construir el mejor modelo de Association Rules a través de Market Basket Analysis de tal forma que te permita disponer de un motor de recomendación de contratación de productos. ¿Serás capaz de predecir cuál será el próximo producto financiero a contratar por el cliente?.
Para ello puedes utilizar las distintas técnicas de Machine Learning disponibles para este tipo de problemas: Reglas de asociación, modelos de clasificación, etc…
Los primeros pasas dados para la resolver el reto propuesto, como en todo proyecto de datos, es la comprensión del problema mediante el análisis exhaustivo de los datos. Para esto usamos una herramienta de visualización llamada Spotfire creada por TIBCO, es una herramienta muy intuitiva y cuya curva de aprendizaje no es muy elevada, teniendo en no mucho tiempo gráficos complejos para ser analizados. Se empezaron haciendo gráficos muy simples sobre el comportamiento global de cada variable hasta llegar a hacer gráficos más complejos que interaccionan unos con otros para conseguir comprender de los datos.
Para saber interpretar mejor los datos, se necesitaba tener un conocimiento más avanzando del mundo de la banca, por ello se contactó con personal relacionado en este mundo para recabar información y saber cómo abordar este problema. Una vez conocidos los datos y el problema se planteó la forma de resolver el reto. En una primera instancia se pensó en usar algoritmos de machine learning conocidos como pueden ser Random Forest, C4.5 o algoritmos de creación de reglas como Apriori, no obteniendo modelos interpretables y de difícil viabilidad en la vida real. Se hizo por tanto una búsqueda intensiva en la literatura para buscar posibles alternativas. Y se encontraron dos alternativas: sistemas de recomendación y reglas de secuencia.
Dado el historial de compras y otras características de un cliente, ¿qué es probable que deseen comprar en el futuro? Como bien se especifica en el problema, necesitamos crear un modelo que junto el análisis de la cesta de productos permita optimizar las estrategias de Cross y Up Selling. A partir de la literatura vemos como los algoritmos de recomendación son los más usados para tal efecto.
El articulo CMRULES: An Efficient Algorithm for Mining Sequential Rules Common to Several Sequences describe un algoritmo el cual detecta patrones de secuencia comunes mediante reglas de asociación. Esto se consigue haciendo una modificación en la métrica clásica de soporte y confianza. Gracias a este artículo se descubrió un software llamando SPMF. Dicho software es open source e implementa una gran cantidad de algoritmos de reglas de secuencia entre otros. A parte de esta gran cantidad de algoritmos para el descubrimiento de secuencia que a nuestro juicio es la mejor manera de resolver este reto, este software tiene otra ventaja y es que uno de sus creadores es profesor en la Universidad de Murcia pudiendo tener soporte en caso de problemas de funcionamiento.
En el siguiente enlace de youtube se muestra un video donde se comenta todo el análisis exploratorio y junto con el uso de la herramienta de visualización Spotfire https://youtu.be/xB0ZPDH33lM
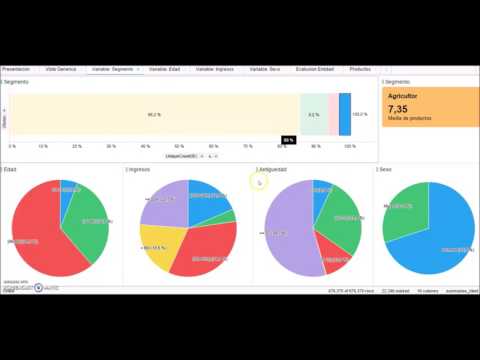
Para hacer el análisis exploratorio se ha utilizado una herramienta de visualización llamada Spotfire, siendo muy parecida a Tableau. Con esta herramienta hemos hecho tres análisis sobre los datos.
El primera análisis es viendo los datos desde un punto de vista global, sin centrarse en explorar una variable en concreto, concluyendo que la mayoría de los clientes están en el segmento Particular (85%) y siendo el segmento de Agricultura el que menos clientes tiene con un total de 3.3%. Como puntos positivos de la entidad a la vista de los datos podemos decir que existe una gran paridad entre sus clientes, existiendo un 54,6% de hombres y un 45,4% de mujeres, felicitando a la compañia por sus campañas realizadas ya que consultado a personal con experiencia en datos bancarios recalca la importancia para una entidad cumplir con el objetivo de paridad entre sus clientes. Otro aspecto positivo es la gran afiliación de los clientes a la entidad, un total de 73,6% tiene una antigüedad entre 10 y más de 20 años. Un campo de mejora de la entidad se localiza en las personas jóvenes, estas solo constituyen un 14,1% del total de sus clientes, recomendando hacer campañas más especializadas para personas comprendidas en esta franja de edad. Remarcar a nivel de ingresos que el grueso de sus clientes está comprendido en rango 6.000 y 12.000 un total de 46,1% están dentro de esta franja. Y para terminar el análisis global mencionar que de media cada cliente compra un total de 4,95 productos, prácticamente 5 productos.
Para seguir comprendiendo mejor los datos disponibles, se ha realizado un análisis más detallado sobre cada variable. Cuando se observa la variable segmento se concluye que los aquellos clientes que está dentro del segmento particular compran de media 4,61 productos que está por debajo de la media aumentando de manera significativa en el resto de segmentos (6,72 Autónomo, 6,97 Comercio y 7,35 Agricultor), es decir, aque segmento que tiene un menor número de clientes (Agricultor) es el que más productos financieros compra de media. Centrándose en aquellos clientes cuyo segmento es Particular, se puede decir que el comportamiento del resto de variables es este grupo es muy parecido al descrito en el análisis global esto se explica porque al existir un gran volumen de personas dentro de este segmento con respecto a los otros influye significativamente en este análisis. En el segmento de Agricultura la paridad ya no se cumple, existiendo un total del 15559 hombres un 69.9% del total, otro dato importante de este segmento es que la mayoría de la gente tiene una antigüedad superior a 20 años, más concretamente un 54,4% y tienen una edad comprendida entre 45 y 65 años.
Analizando la variable edad se observa como las personas que tienen más de 65 años y menos de 18 solo compran productos dentro del segmento de particulares. Los clientes cuyas edades están comprendidas entre 45 y 65 tienen una variabilidad más del resto de variables. Destacar que aquellos clientes que tengan una edad entre 30 y 45 son los que más productos compran de media respecto al resto 6,03 estando por encima de la media global. Sea cual sea el rango de edades analizado se mantiene la paridad entre sexos, siendo más relevante en la franja de menor de 18 años hasta 30 años.
Otra variable analizada es la de ingresos. Aquellos clientes que tienen un nivel de ingresos más alto compran más productos, existiendo un salto significativo entre rentas entre < 6000 y 12000 con el resto. La franja de edad de clientes con mayores ingresos está comprendida entre 45 y 65 años. Como se ha destacado en variables anteriores en esta ocasión hay alto grado de paridad entre los clientes con ingresos entre 6000 y 12000. También destacar que sea cual sea el nivel de ingresos por parte de los clientes la antigüedad de estos en la entidad está comprendida mayoritariamente entre 10 y más de 20 años, recalcando nuevamente el nivel de afiliación de los clientes.
El tercer análisis que se hace sobre los datos es a nivel de producto. Se observa como desde 1969 la entidad no ha hecho otra cosa que incrementar el número de productos que se venden por año, existiendo un aumento considerable en el año 2011 donde se compraron el doble de productos que el año anterior. Coincidiendo con la coyuntura económica de España en 2012,2013 y 2014 se observa una pequeña caída en el número de productos, coincidiendo justamente con el rescate bancario que tuvo lugar en el país. El repunte en 2011 se debe a la venta masiva del producto 9993 y 9992, teniendo una gran aceptación en ese año pero sufriendo un gran desplome en los años posteriores, concluyendo que quizás dichos productos se deban a una oferta puntual de la entidad bancaria. También se aprecia un aumento del número de productos ofertados desde 1990 aumentando año a año, existe una excepción y es en el segmento Particular cuyo aumento de cartera de productos comienza antes, concretamente en 1984.
Observando que productos son los más vendidos, podemos destacar 6 productos, el 601 con un 19,8%, el producto 301 con un 12,7%, el producto 201 con un 10,1% del total, los productos 9993 y 9992 con un 6,9% cada uno y por último el 2302 con un 8%, sumando todos estos porcentajes da un total de 64,4% de cuota total de productos. Los productos 601 y 301 no solo son los más vendidos sino que existen en la entidad desde los comienzos, aumentando la venta de este conforme van pasando los años.
En este apartado se presentarán las distintas modificaciones que se le aplicaron a los conjuntos de datos de train y test así como las distintas variables adicionales que se crearon para comprender, analizar y resolver el problema.
En primer lugar, decidimos añadir a nuestro conjunto de datos (train y test) una nueva variable denominada "Estación" con el objetivo de que nos pudiese ayudar a la hora de realizar un análisis temporal. Dicha variable toma cuatro valores posibles: Primavera, Verano, Otoño e Invierno según el mes en el cual un cliente adquiere un producto. El objetivo de esta variable es ver si existe estacionalidad a la contratación de productos por estaciones.
Reducir la demension del conjunto de datos sin perdida de información es vital, así se verá reducido el tiempo de computo de las ejecuciones de los diferentes modelos. Esto es posible gracias a que cada cliente tiene asignada siempre la misma información, es decir, un cliente que hizo la primera de un prodcuto hace 20 años es etiquetado con la misma información que si hace una compra en los últimos meses, en otras palabras, no hay una evolución temporal de los valores de los clientes. Por tanto es posible tener un dataset donde cada fila corresponda a un cliente con la información de las 7 variables de entrada más un array con todos los productos que ha comprado, la fecha de la primera y última compra, el número de prodcutos y la frecuencia de compra que se calcula como (fecha_max - fecha_min)/nº_productos. Reduciendo así el tamaño del dataset teniendo inicialmente 3350601 filas a un total de 676370.
Algo similiar se hace sobre los productos, donde cada fila corresponde con un código de producto y se la añaden como columnas el número de clientes que ha comprado ese producto, la fecha de la primera compra y ultima de ese producto así como la diferencia en años entre ambas fechas. Este dataset ha sido usado para el análisis temporal de la serie.
Otra de las decisiones que se tomó, fue construir un dataset donde las columnas esten formadas por cada uno de los clientes y colocar tantas columnas como productos diferentes existan, esto nos va a permitir analizar nuestro conjunto de datos de forma más sencilla por las siguientes razones: *Nos permite agrupar en una misma fila un único cliente, ya que para cada fila tendremos un cliente donde para cada producto tendrá el valor de 0 si el cliente no adquirió el producto y el valor de 1 en caso de que adquiera el producto en algún momento. *Esta manipulación nos va a permitir conocer de forma rápida e intuitiva el número de productos que tiene contratado cada cliente con la entidad y por lo tanto también el número de productos que un cliente no tiene contratado con la entidad. *También nos permitirá filtrar el correspondiente dataset por ejemplo por los distintos segmentos y ver para cada segmento que productos se contratan y que productos no se contrata y con que frecuencia se contratan. *Otra de las razones por la cuál decidimos realizar esta manipulación, es que nos permite obtener la matriz de correlación entre productos. Es decir, nos va a permitir encontrar la correlación que existe entre los productos que compran por ejemplo los clientes cuyo segmento es Agricultor. De esta forma podemos obtener información de si determinados productos se encuentran correlacionados de forma positiva, correlacionados de forma negativa o no están correlacionados.
4.- JUSTIFICACIÓN DEL MODELO (SELECCIÓN DE MODELO/S Y AJUSTE DE PARÁMETROS, ELECCIÓN DE MÉTRICA ELEGIDA Y JUSTIFICACIÓN, BONDAD DEL MODELO, INTERPRETABILIDAD DEL MODELO Y VIABILIDAD DE PUESTA EN PRODUCCIÓN)
Como hemos explicado anteriormente, el modelo utilizado es el de recomendación basado en el filtrado colaborativo. En la literatura encontramos diferentes librerías en R que nos facilita bastante la tarea de implementar el modelo.
El filtrado colaborativo es una rama de recomendación que tiene en cuenta la información sobre diferentes usuarios. La palabra "colaborativo" se refiere al hecho de que los usuarios colaboran entre sí para recomendar artículos. De hecho, los algoritmos toman en cuenta las compras y preferencias de los usuarios. El punto de partida es una matriz de clasificación en la que las filas corresponden a los usuarios y las columnas corresponden a los productos.
Debemos destacar que existen dos tipos de métodos de recomendación de filtrado colaborativo: filtrado colaborativo basado en usuarios (User-based collaborative filtering, UBCF) y filtrado colaborativo basado en productos (Item-based collaborative filtering, IBCF).
En nuestro caso hemos usado filtrado colaborativo basado en artículos. Dado un nuevo usuario, el algoritmo considera las compras del usuario y recomienda nuevos artículos. El algoritmo básico se basa en estos pasos: 1. Para cada dos productos, mide cuán semejantes son en términos de haber sido comprado por usuarios similares 2. Para cada producto, identifica los k-artículos más similares 3. Para cada usuario, identifica los artículos más similares a las compras del usuario
El primer paso con IBCF es establecer una similitud entre los ítems. En el caso de datos binarios (estamos trabajando con un dataset donde cada fila representa un único cliente y las columnas son cada uno de los productos, donde habrá un 1 ó 0 si se ha comprado o no dicho producto, respectivamente), las distancias como la correlación y el coseno no funcionan correctamente. Una buena alternativa es el índice de Jaccard. Dado dos productos, el índice se calcula como el número de usuarios que compran los artículos dividido por el número de usuarios que compran al menos uno de ellos. De esta forma creamos el modelo de recomendación y el siguiente paso sería predecir las recomendaciones para el conjunto de test.
El ajuste de parámetros se ha realizado en base al parámetro k. El algoritmo calcula las similitudes entre cada par de ítems. Luego, para cada ítem, identifica sus k-ítems más similares y lo almacena. Para ello se ha creado un grid de parámetros con distintos valores que junto a la validación cruzada y la curva ROC nos ha servido para elegir el mejor valor de k. En este caso, k=30.
Con la validación cruzada nos aseguramos que nuestro modelo no se sobreajusta a los datos de entrenamiento. Realizamos 4 particiones del conjunto de datos, dónde se irán alternando para crear diferentes conjuntos train-test: 3 particiones formarán el conjunto train y 1 el test.
Con la curva ROC nos mostrará de forma visual aquel modelo que mejor se comporta. Será aquel que tenga un mayor área bajo la curva, el cual indica la probabilidad de que una producto sea recomendado de forma correcta.
Las medidas de precisión usadas son las siguientes: - Precisión: es el porcentaje de artículos recomendados que se han comprado. Es el número de False Positive dividido por el número total de positivos (TP + FP). - Recall: Este es el porcentaje de artículos comprados que se han recomendado. Es el número de True Positive dividido por el número total de compras (TP + FN). También es igual a la tasa verdaderamente positiva.
El modelo IBCF presenta una interpretabilidad sencilla y presenta una alta viabilidad para la puesta en producción. Una vez que el modelo es entrenado, basta con aplicarlo a clientes a los cuales queremos recomendarles nuevos productos que sean de su interés y por tanto, proporcione un mayor beneficio al banco. El entrenamiento del modelo tiene un coste computacional muy bajo, ya que en poco tiempo es entrenado. En cambio, un modelo UBCF es más costoso computacionalmente en comparación al IBCF, necesita calcular una matriz de distancias entre todos los clientes. Lo cual aumenta considerablemente el tiempo de entrenamiento del modelo. Razón por la que elegimos el modelo IBCF.