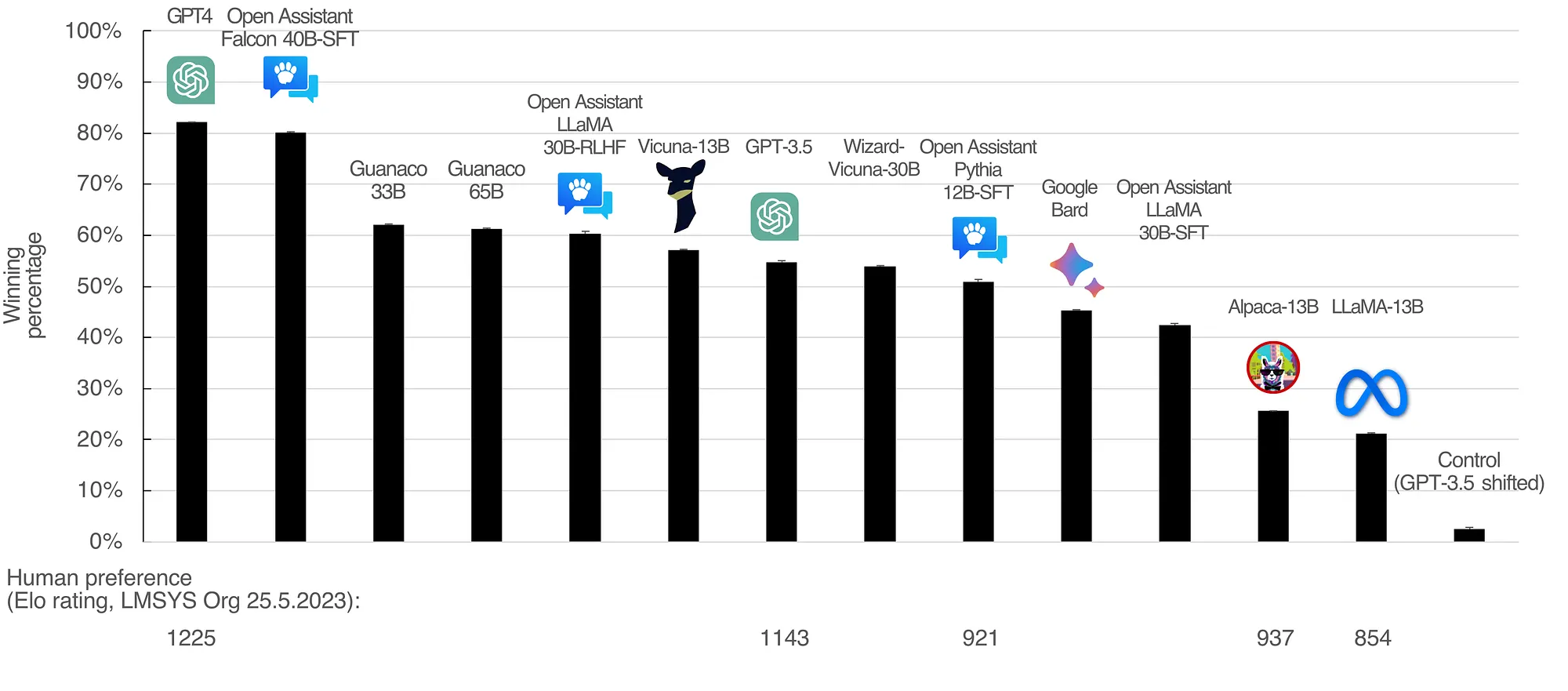
https://medium.com/@geronimo7/open-source-chatbots-in-the-wild-9a44d7a41a48
export APIKEY="YOURKEY"
python3 get_review.py -r "gpt-3.5-pairwise" -a table/answer/answer_vicuna-13b.jsonl table/answer/answer_pythia-12b-sft-v8-7k-steps.jsonl -o table/review_pairwise/review_vicuna-13b_pythia-12b-sft-v8-7k-steps -dr 3 -k "$APIKEY"
# calc winning percentage
python3 reviews_winrate_pairwise.py -r table/reviews_pairwise
# generate html
python3 generate_webpage_data_from_table.py -r table/reviews_pairwise