{kind=link}
- fast and precise MIME type and file extension detection
- long list of supported MIME types
- possibility to extend with other file formats
- common file formats are prioritized
- text vs. binary files differentiation
- safe for concurrent usage
go get github.com/gabriel-vasile/mimetypemtype := mimetype.Detect([]byte)
// OR
mtype, err := mimetype.DetectReader(io.Reader)
// OR
mtype, err := mimetype.DetectFile("/path/to/file")
fmt.Println(mtype.String(), mtype.Extension())See the runnable Go Playground examples.
Only use libraries like mimetype as a last resort. Content type detection
using magic numbers is slow, inaccurate, and non-standard. Most of the times
protocols have methods for specifying such metadata; e.g., Content-Type header
in HTTP and SMTP.
Q: My file is in the list of supported MIME types but it is not correctly detected. What should I do?
A: Some file formats (often Microsoft Office documents) keep their signatures towards the end of the file. Try increasing the number of bytes used for detection with:
mimetype.SetLimit(1024*1024) // Set limit to 1MB.
// or
mimetype.SetLimit(0) // No limit, whole file content used.
mimetype.DetectFile("file.doc")If increasing the limit does not help, please open an issue.
mimetype uses a hierarchical structure to keep the MIME type detection logic. This reduces the number of calls needed for detecting the file type. The reason behind this choice is that there are file formats used as containers for other file formats. For example, Microsoft Office files are just zip archives, containing specific metadata files. Once a file has been identified as a zip, there is no need to check if it is a text file, but it is worth checking if it is an Microsoft Office file.
To prevent loading entire files into memory, when detecting from a reader or from a file mimetype limits itself to reading only the header of the input.
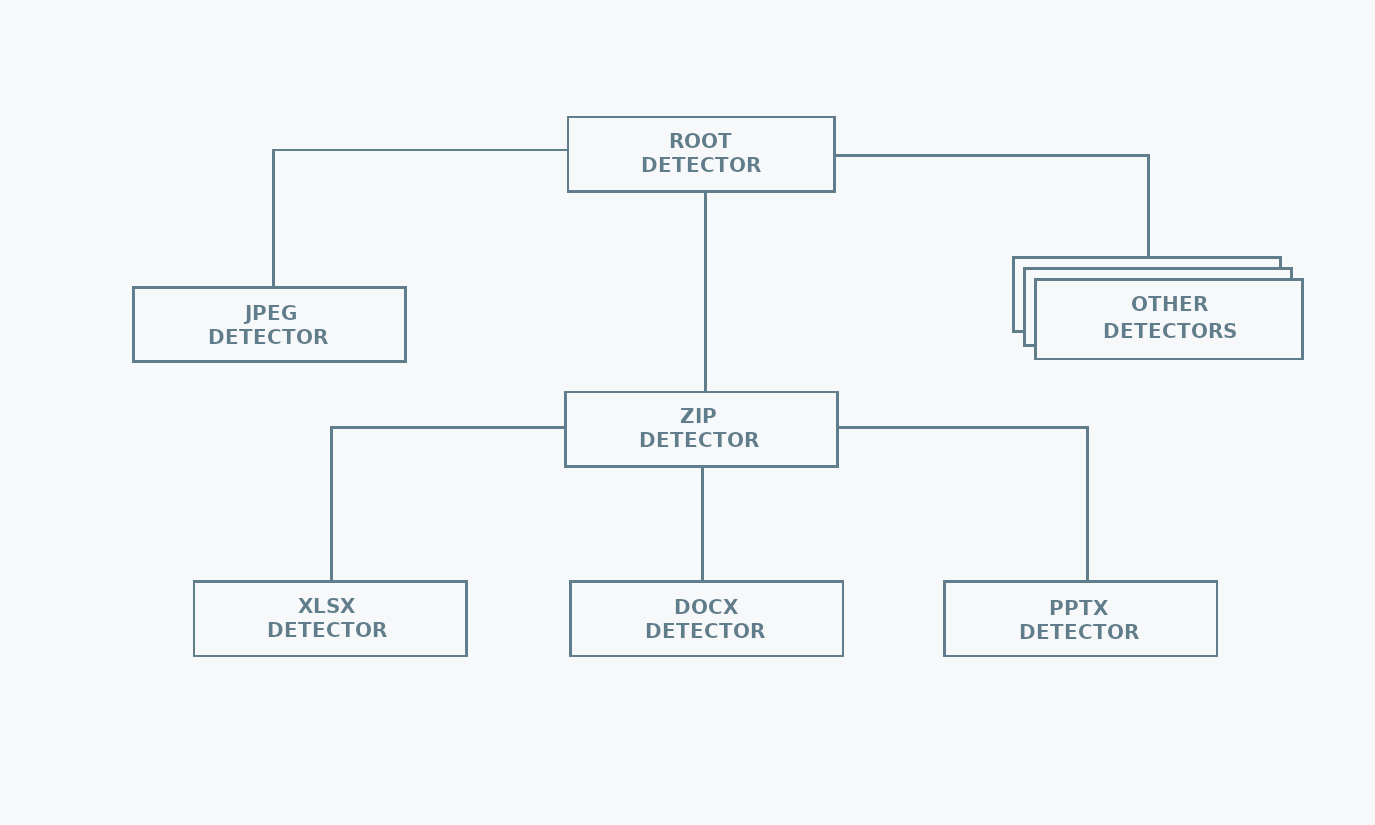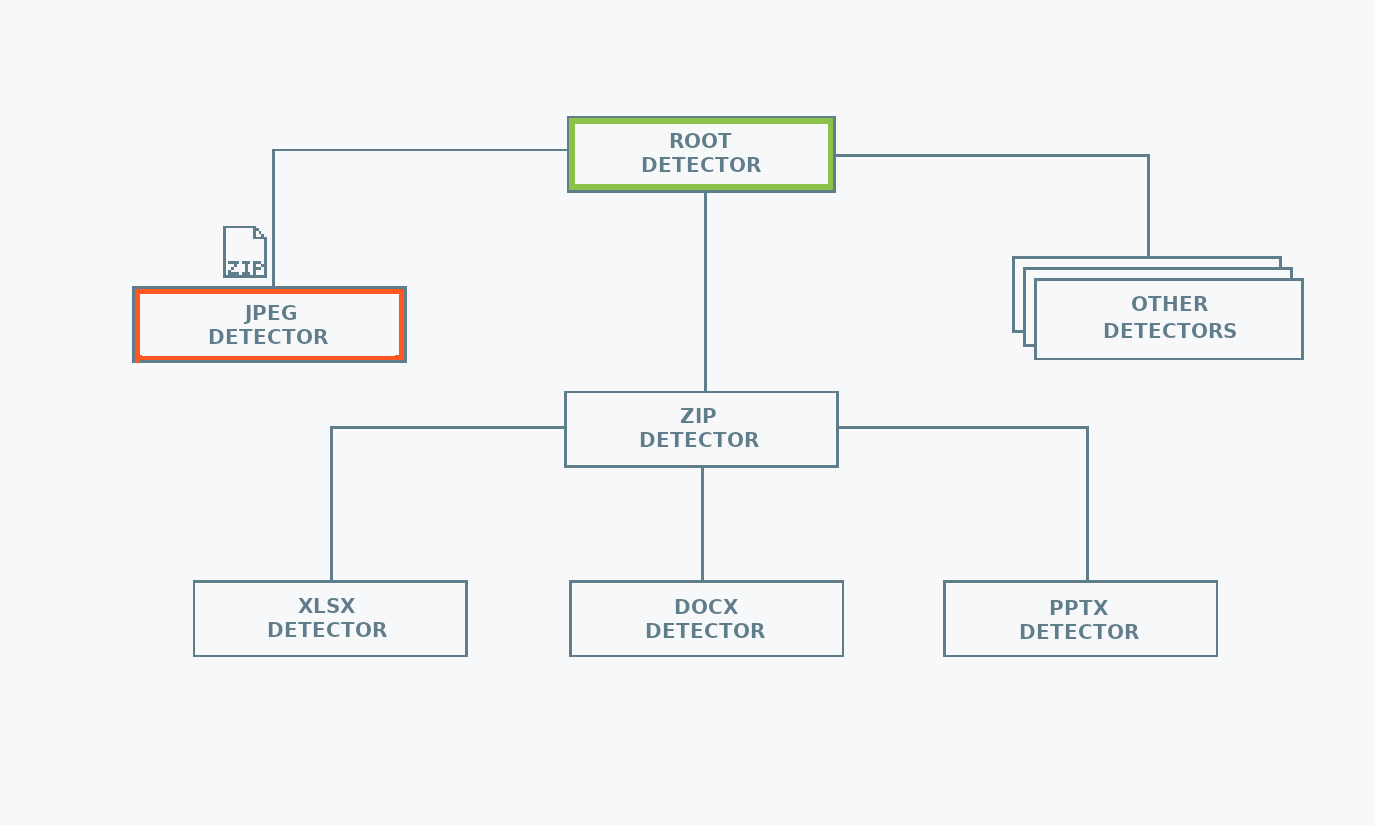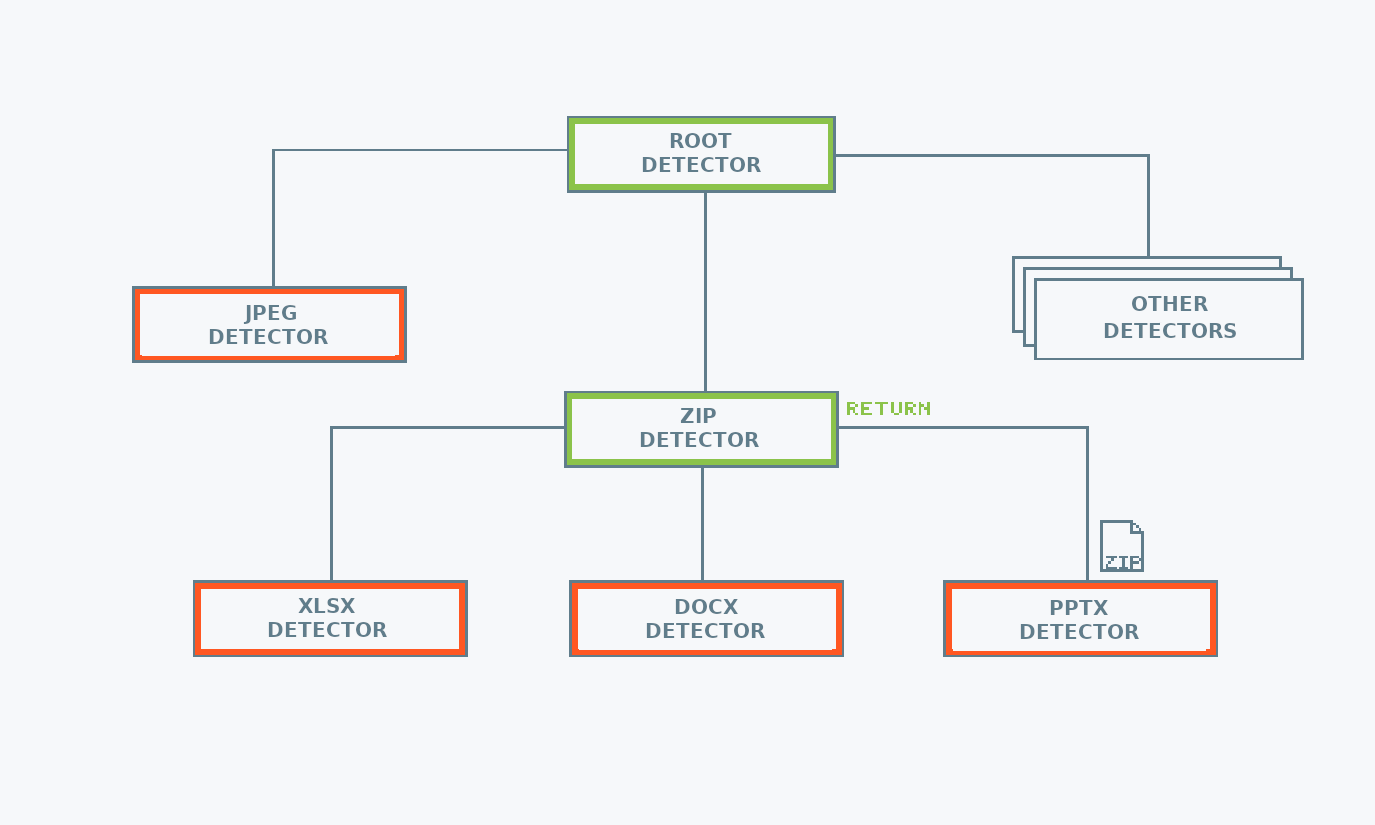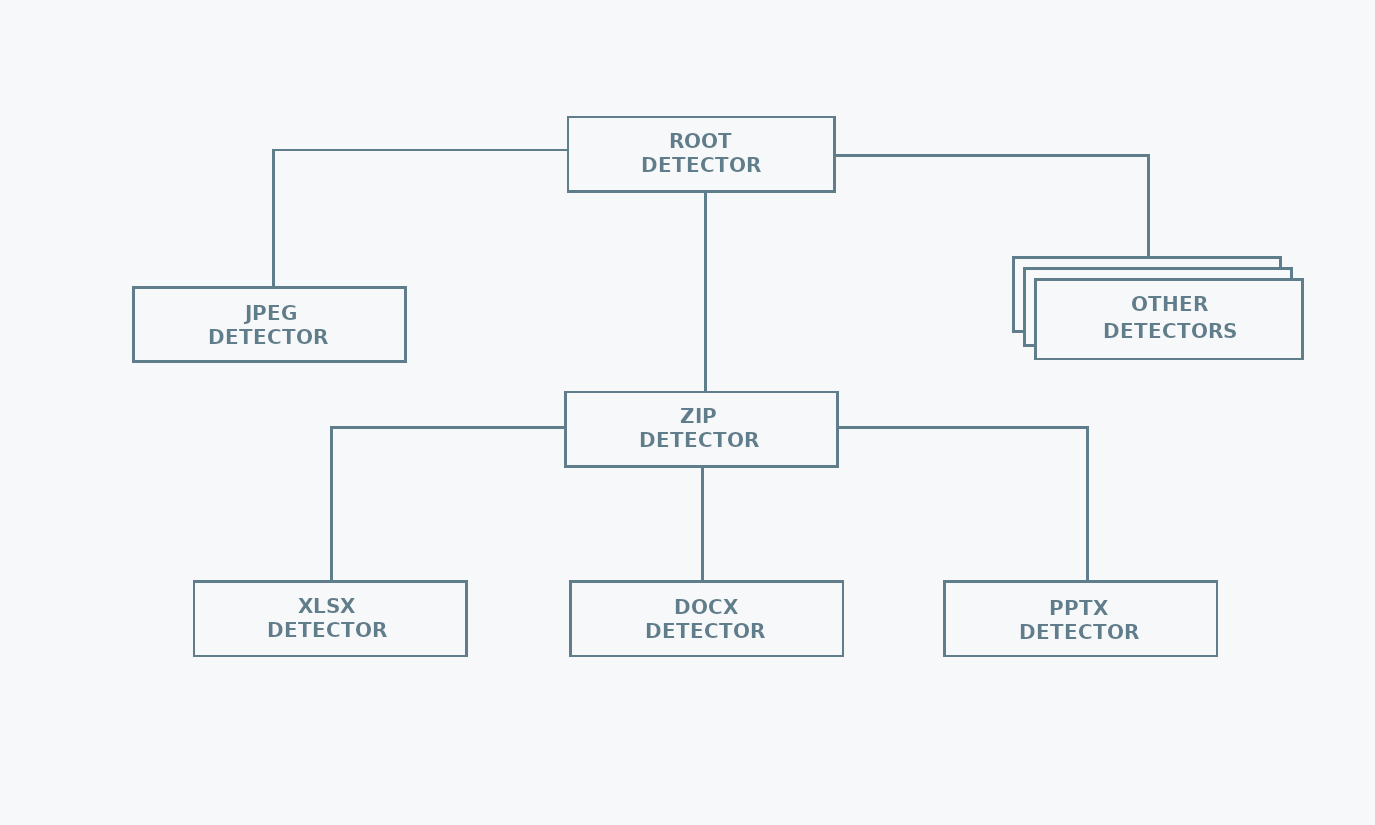
Thanks to the hierarchical structure, searching for common formats first,
and limiting itself to file headers, mimetype matches the performance of
stdlib http.DetectContentType while outperforming the alternative package.
mimetype http.DetectContentType filetype
BenchmarkMatchTar-24 250 ns/op 400 ns/op 3778 ns/op
BenchmarkMatchZip-24 524 ns/op 351 ns/op 4884 ns/op
BenchmarkMatchJpeg-24 103 ns/op 228 ns/op 839 ns/op
BenchmarkMatchGif-24 139 ns/op 202 ns/op 751 ns/op
BenchmarkMatchPng-24 165 ns/op 221 ns/op 1176 ns/opSee CONTRIBUTING.md.