This repo deals with sequence learning of articles using CNN and RNN architectures. The dataset consists of article content, their titles, author names, date of publishing, and the name of publishers. The articles' content will be processed and analyzed to predict the name of the publisher. This would help us tell if the way of writing by publishers is unique to their own as the sequences of articles' content will be learned by the models.
CNN usually deals with convolutions of tensors such that it tries to find meaningful features in a localized manner depending on kernel size. In this repo, instead of localized transformations, a 1-D CNN will be operated on the sequence of tokenized text to generate feature transformations that learn the sequences within the articles. In contrast, RNN architectures are mainly built to learn the sequences and so, in this repo, a comparison will be made between the performances of a CNN vs RNN architecture on sequence learning.
The data can be found in either links below-
- GDrive Link - https://drive.google.com/drive/folders/1fxV90otr9Rj6WtXmTIHUQdQO8VOrErkd?usp=sharing
- Kaggle Link - https://www.kaggle.com/snapcrack/all-the-news
There are three essential notebooks here-
- Part 1 deals with cleaning and processing of the data to build the models
- In Part 2, the data is tokenized and then a 1-dimensional CNN architecture will be employed to train and test the model
- In Part 3, a Bi-directional LSTM network will be implemented
There are simple cleaning procedures implemented in this notebook. The mail addresses and usernames, if found, are removed. All punctuations, stopwords are removed. The words are lower-cased and finally lemmatization and stemming (with Snowball Stemmer) are applied.
As there are several publishers (as target), the slicing is performed to get the articles of only the top 5 publishers (by count) viz.
| Label | Publisher Name |
|---|---|
| 0 | Breitbart |
| 1 | New York Post |
| 2 | NPR (National Public Radio) |
| 3 | Washington Post |
| 4 | Reuters |
Finally, the target i.e. the name of the publisher is one-hot encoded.
After all of the processing, a 70-30 split is made to get the training set and testing set with a stratified target (train+test dataset = 74548 data points)
The tokenizer and padding functionalities are implemented first to tokenize the words of the articles in the training dataset. The tokenizer is first fit onto the training set that assigns a number to each unique word. Each article will then have an array of numbers that denote a particular word stored in the tokenizer's word-index dictionary.
As can be assumed, articles' length will vary and so the number of columns would be equal to the maximum length of all articles in the dataset. For the articles with shorter lengths, zeros will be padded after their length is finished to denote that no words are present at their positions.
For example, for the below corpus-
A1 :- I am here.
A2 :- He is here now.
The tokenized and padded form will be-
A1 :- [1, 2, 3, 0]
A2 :- [4, 5, 3, 6]
The tokenizer fit on the training set will then encode the testing set as per its word-index dictionary taken from the training set. There are certain dataset parameters that need to be fed to the model viz. maximum length of all articles and the vocabulary size of the training set.
length, vocab_size = 12052, 157706 (obtained values)
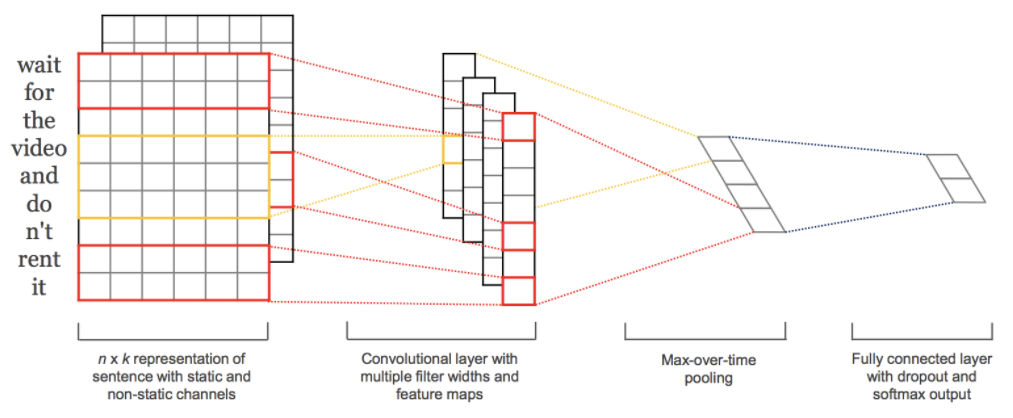
The model takes three layers as inputs (matrices of encoded vectors of the articles just repeated thrice). Each layer is evaluated as a separate channel with a different kernel_size that traverses and convolutes with the vectors.
An embedding layer first embeds the encoded vectors to generate another vector of size 10 for each word. This process is applied to all three channels.
A 1-dimensional convolutional layer then traverses over the matrix of embedded vectors (meaning the stride happens only in the vertical direction - see figure below denoting red boundary box as the kernel). The kernel size differs for the three channels producing features that capture the sequence of words with different lengths.
A dropout, 1-D pooling and flatten layer is applied to each channel with the same hyper-parameters applied across the three channels.
The flattened features from the three layers are then concatenated together to produce a single set of features which is then passed on to another dense layer that finally gives out an output containing 5 neurons for each label.
A similar architecture for reference is provided below -
The same tokenized and padded training and testing dataset is now modeled using a very simple Bi-Directional LSTM architecture. There is a tiny modification as the whole length of article will not be fed due to cost and time constraints i.e. out of 12052 features, the first 500 words of each article is fed to the model.
An input shape of 500 length is chosen for each article which produces a 100 sized vector using the Embedding layer of each word (as compared to 10 sized in CNN)
The bi-directional LSTM layer then runs on the vectors to learn the sequences from both ends (forwards and backwards)
The output is flattened and then fed to dense layers which finally produce the output of probability of 5 classes which get softmax activated finally
This is a very simple architecture and can be even experimented to find better results. The image below encapsulated the Bi-Directional LSTM model beyond which the Flattening and Dense layers are applied to generate the target.

| 1D-CNN | Bi-Directional LSTM |
|---|---|
| Batch_size = 32 | Batch_size = 32 |
| Number of parameters trained = 41,742,737 | Number of parameters trained = 17,285,161 |
| Number of features employed = 12052 | Number of features employed = 500 |
| Embedding Size = 10 | Embedding Size = 100 |
| Training Time = 2.1 hrs (on CPU) | Training Time = 2.3 hrs (on CPU) |
| No of Epochs = 4 (patience-2) | No of Epochs = 3 (patience-2) |
| Training Accuracy = 98.22% | Training Accuracy = 98.79% |
| Validation Accuracy = 87.55% | Validation Accuracy = 86.02% |
The performance is quite comparable between the models. However, there is a slight hint of overfitting with some difference between training and validation accuracy. Also worth noting is that the LSTM architecture employes fewer training parameters and a low number of features as opposed to CNN architecture.
Let's look at the F1-score for each publisher on the testing set:-
| Publisher Name | Class Count | 1D-CNN (F1 Score) | Bi-Directional LSTM (F1 Score) |
|---|---|---|---|
| Breitbart | 23781 | 0.93 | 0.91 |
| New York Post | 17485 | 0.80 | 0.78 |
| NPR (National Public Radio) | 11654 | 0.83 | 0.82 |
| Washington Post | 11077 | 0.99 | 0.97 |
| Reuters | 10709 | 0.81 | 0.78 |
Based on the models's overall performances, the individual class performances are commensurate. Publishers - Breitbart and Washington Post are found to employ a unique writing of their articles which is easily distinguishable from other publishers. The other publishers are not so distinct as the above two (with New York Post and Reuters being least distinguishable)
In summary, CNN architectures are found to perform comparably well as RNN architectures are expected to. CNN architectures, apart from their usual application, can also be implemented (carefully) to learn sequential data!