In this repo, we will deal with Translation of languages, specifically English to French. An Encoder-Decoder model using LSTM layers combined with Bahdanau Attention Mechanism will be implemented for training (along with Teacher Forcing - feeding the translation in a sequential manner to the decoder). Teacher Forcing can be compared to spoon-feeding wherein we ask the decoder model to spit out the next word when fed with the previously translated word(s) as well as the complete sequence of input language words (weighted with attention)
After the model gets trained, we will look at two inference algorithms viz. Greedy Search and Beam Search and discuss about each. For model's evaluation, we propose the BLEU metric to know how good the model can translate (albeit the metric having its own limitations)
Machine Translation models have been in existence for a long time. They are composed of Encoder-Decoder linked models. Encoder model's primary objective is to encode and learn the sequences of the source language while the Decoder Model's objective is to translate it to a target language. While these models have worked good, Bahdanau et. al. in circa 2014 came up with an Attention Mechanism that helps the decoder to focus on some words from the source language while translating and spitting out each word. This led to remarkable improvements in the model's performance and now Attention is being implemented to several applications apart from translation work in domains such as Computer Vision, etc.
In this notebook, we need to have tensorflow (2.4) installed in order to run it. Some knowledge on Deep NN Models is assumed as well as knowledge on RNN-LSTM networks
Source Language:- English
Target Language:- French
The dataset is provided by an organization through the below link: Link for getting data - http://www.manythings.org/bilingual/
The notebook is segmented into following sections:
Section 1: Data Processing
Section 2: Data Tokenization
Section 3: Building the Model
Section 4: Training the Model
Section 5: Inference from the Model (Greedy & Beam Search)
Section 6: Evaluation of the Model
The data consists of english phrases/sentences and their french translations.
- All special characters are removed
- Sentence-ending symbols (. , ? !) are given spaces
- Add 'start' at the start of the sentence and 'end' at the end of the sentence (to signal the model the start and end of any phrase/sentence)
As this notebook is for presentation purpose, we limit the data to the first 50,000 english-french data points. This number can be manipulated as per the user's needs
We end up with data that contains information like this-
| ENG_processed | FRA_processed |
|---|---|
| tom lied to all of us . | tom nous a a tous menti . |
| tom lied to everybody . | tom a menti a tout le monde . |
| tom liked what he saw . | tom a aime ce qu il a vu . |
and so on...
The tensorflow's tokenizer and padding functionalities will tokenize the processed text.
This means that for two texts in the corpus -
S1:- I am here
S2:- He is here right now
The tokenized form would be -
S1:- [1, 2, 3, 0, 0]
S2:- [4, 5, 3, 6, 7]
Basically, the tokenized form would replace the word with a unique number that would represent that word.
- Notice the padding done at the end of sentence 1 (two 0's added). This will be done based on the maximum length of a sentence in a particular language
- Notice the repetiton of 3 in both tokenized forms which represent the word 'here' being repeated
Two separate tokenizers for each language will fit onto the each language's corpus to be tokenized. Besides this, we need two other values for each language for building the model architecture viz. maximum length of all sentences and vocabulary (count of unique words)
For Source Language (English)
- Max Length = 11
- Vocab Size = 5886
For Target Language (French)
- Max Length = 19
- Vocab Size = 10214
The tokenized text will be pickle stored finally to train the model with
Let us build up the concept slowly. Starting discussion with an Encoder-Decoder translation model (without any attention mechanism)
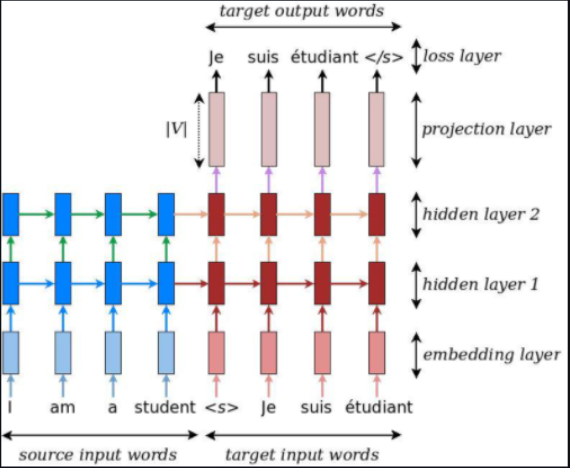
The blue cells denote the encoder and the red cells denote the decoder layers.
After the embedding layers embed each word of the source and target text, the encoder (blue hidden) layer learns the sequences in the source text as well as the final states of encoder from this layer are fed to the decoder (red hidden) layer that learns the sequences of translation along with the source states from the encoder.
The decoder layer then makes a projection layer which spits out a prediction vector of size V (vocabulary size of target language). The maximum probability value of this vector denotes the word that the model is predicting which is judged against what should be produced as a loss function.
Notice the <s> at the start of target input words which is the first word fed to the decoder model (representing the start of decoding) and the prediction at this point is the first word of translation. The last word of target input spits out </s> that would denote the end of translation.
Note that we have employed only one hidden layer in this notebook per encoder and decoder.
We will implement teacher forcing during training. This means that the model is fed with the translated word as an input to the decoder and that too in a sequential manner. In summary, it is the technique where the target word is passed as the next input to the decoder. Note that this won't and can not be implemented during inference.

The inference, i.e. translating once the model has been trained, would be a little different. Let's see how below-
Everything is the same except we don't know the target input to be fed to the model when you would be inferring (teacher forcing explained above).
In this case, the first prediction of <s> (moi) is fed as an input of next target word to the model the produce the next translated word. The sequence continues until we hit </s> where the translation stops.
Above figure is a type of greedy decoding since we are only looking at the word with the highest probability in the prediction vector. This is very basic seq2seq model. Adding the attention mechanism to it greatly enhances its performance. If you have understood the above architecture, move below to understand Attention Mechanism
Let's now start with an Encoder-Decoder translation model with Bahdanau attention mechanism

You will notice the addition of 'attention weights', 'context vector' and finally the attention vector to the above discussed model.
The calculation of the above hinges on the below formulae :-

The attention computation happens at every decoder time step. It consists of the following stages:
- The current target hidden state is compared with all of the source states to derive attention weights
- Based on the attention weights, we compute a context vector as the weighted average of the source states
- Then we combine the context vector with the current target hidden state to yield the final attention vector
- The attention vector is fed as an input to the next time step (input feeding)
The way of comparing the source states with the current target hidden state has been researched and Bahdanau' additive style has been employed in this notebook (Formula 4 in above figure). There are other comparative measures such as Luong's multiplicative style as well as their variations and combinations.
The comparison gives out a score when each source hidden state is compared with the current target hidden state. This score is fed to a softmax layer (Formula 1) that measures the score of the current hidden state against each source hidden state (which are the attention weights).
The weights are then assessed with the source states so that the model focuses on source input words where it should focus in translating the current target input (Formula 2). This produces a context vector that contains information where the context lies in the input sequence to translate the current word
The context vector is concatenated with the current target hidden state and then activated to get an attention vector (Formula 3) that encompasses all information of source input and for target input - everything upto the current target input state.
Also, the hidden state obtained during computation of attention vector is added as an input to the next word in target input so that the prior information is passed on in a sequential manner to its embedding and subsequent learning.
Notice the teacher forcing here during training when the target word is passed as the next input to the decoder. Again, as told earlier, it is an aspect only built-in during the training and the inference will act without it.
As before, during the inference, everything is same except that teacher-forcing isn't implemented and the translated 'prediction' word from the model itself is fed as the next input to the decoder
I believe that was a lot to take in. Here are some articles I referred when I tried to understand it all and I hope that these will be able to get you some more in-depth knowledge and insights -
- Base Article - https://www.tensorflow.org/tutorials/text/nmt_with_attention
- Understanding Attention - https://github.com/tensorflow/nmt#intermediate
- Understanding Types of Attention - https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3
An Object-oriented approach is applied as the Tensorflow-Keras libaries don't have predefined layers that can incorporate this architecture. There could be a way using backend Keras but I believe it would also require some modifications that can be done using a Class inheriting the backend classes.
Once the classes are formulated and model has been built (along with loss calculation and optimizer defined), the tf.GradientTape() function will be implemented to train the model on each batch and update the gradients of the trainable parameters. The model is trained for 20 epochs (with 0 patience), with shuffling of data in each epoch. For more information on this, please refer the notebook on how everything is defined and formulated.
1. Greedy Search
Greedy Search is the most basic inference algorithm. It takes the word with the highest probability at each output from the decoder input. This word is then fed to the next time step of the decoder to predict the next word until we hit the 'end' signal
Some outputs from Greedy Search -
- evaluate('it is very cold here') :- il fait tres froid ici
- evaluate('You may speak') :- vous pouvez discuter
2. Beam Search
Beam Search is slightly complicated. It produces K (which is user-defined) number of translations based on highest conditional probabilities of the words.
Let us understand this by taking an example -
Suppose we take k=3 (see below pic; reference:- https://www.youtube.com/watch?v=RLWuzLLSIgw&t=360s&ab_channel=DeepLearningAI)
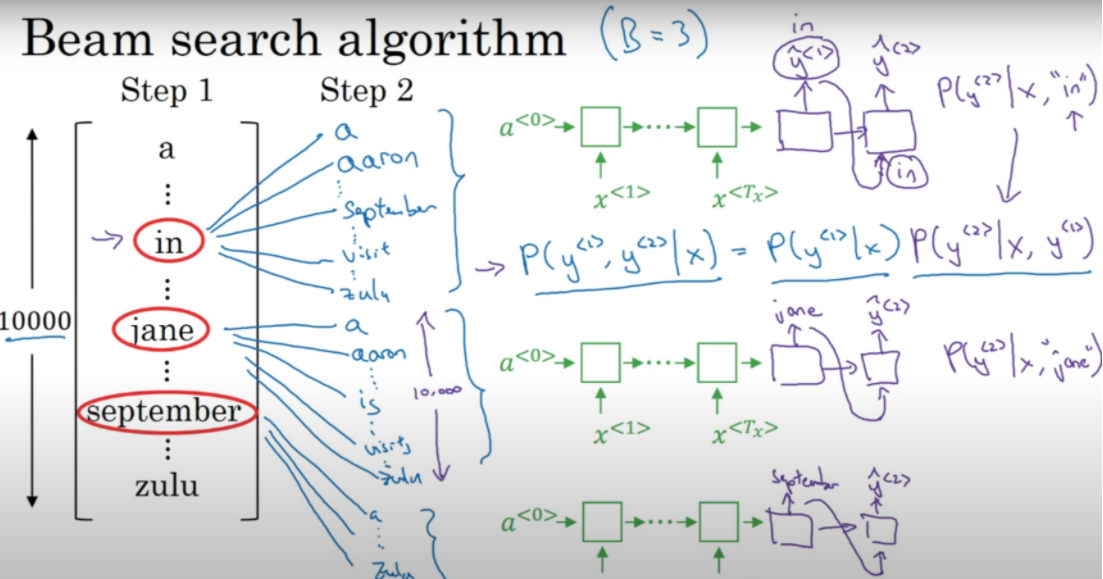
In beam search, we take the top k words as a possibility instead of the word with highest probability. In above pic, in step 1 - we see three words - (in, jane, september) as three possible translated words that have the highest probability out of the 10,000 vocabulary of words.
In step 2, for each of the previous word, we pick another top 3 words with highest probability. But this probability calculation is now conditional to the previous word and is calculated based on the probability formula given in the picture.
But, we slightly modify the probability calculation by taking its negative log (log being monotonous will not impact the values; this trick makes the formula to add the probabilities instead of multiplying them to avoid underflow). See modified formula below -
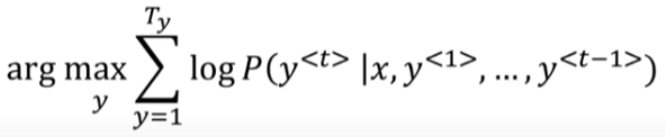
Once we have the 9 probabilities (k x k), we filter for the top 3 highest and then carry them forward to step 3 and so on.
One thing to note here is that there are k decoder models running here for reference for each word found in step 1. Let's discuss more about it with the pic below
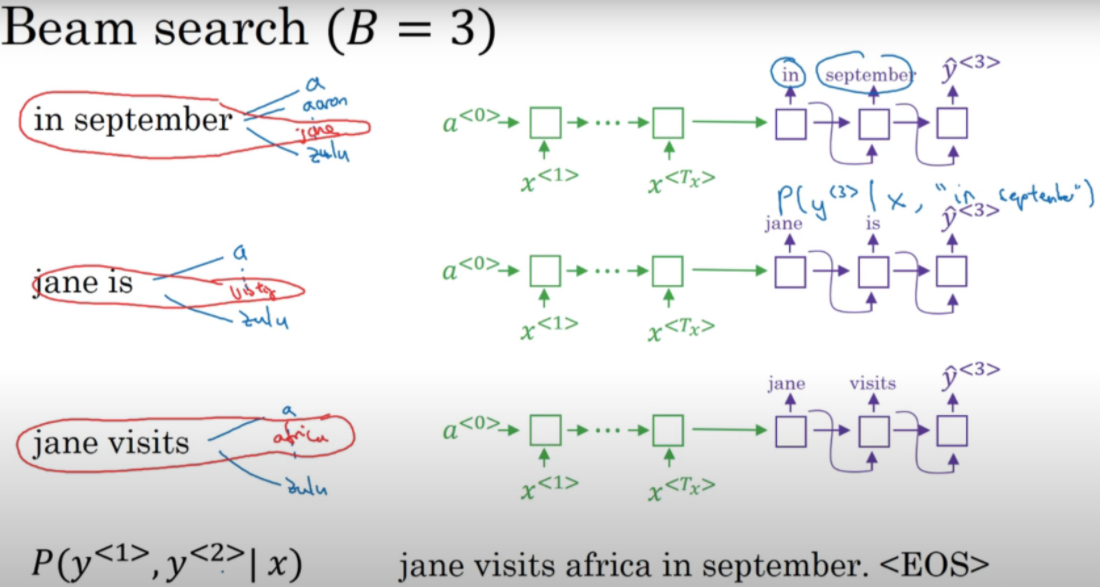
We see three decoder models that take the previous word as an input and then predicts the next word. Now some cases might arise here-
- The top three probabilities might come out of one or two previous words and so the decoder model(s) that don't have the highest probability get cut off. This is advantageous as we are concerned with the highest conditional probability of the entire sentence.
- A sentence progression can hit the 'end' signal before others and thus we get one possible translation of the sentence. The decoder model at this point might get cut off depending if it has more sequence progressions arising out of it.
Both cases above are considered in the algorithm formulation. The above points also helps to understand the working behind Beam Search
Below is an illustration of beam search with k=5 in translation to German. Notice 5 nodes at each vertical segment.
source:- https://medium.com/the-artificial-impostor/implementing-beam-search-part-1-4f53482daabe
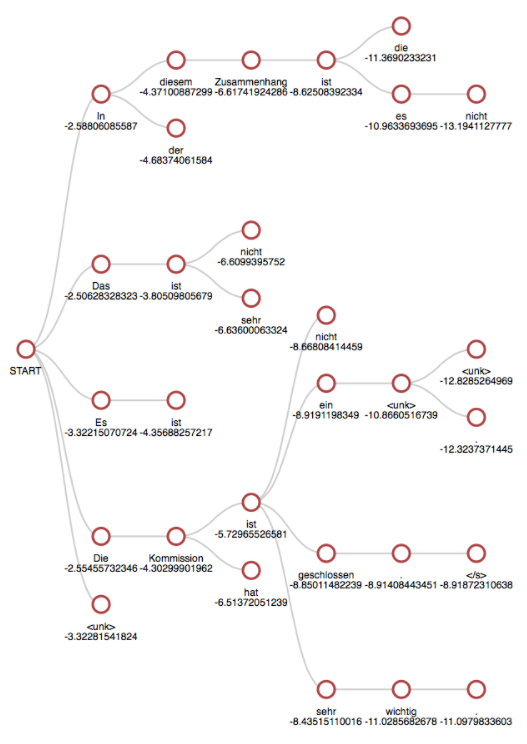
Some outputs from Beam Search -
-
evaluate_with_beam('it is very cold here', 5) :-
-
Translated Sentence 1 : "c vraiment froid" ; Associated Neg Log Probability: [1.4590162]
-
Translated Sentence 2 : "il tres froid ici" ; Associated Neg Log Probability: [1.2284557]
-
Translated Sentence 3 : "on beaucoup beaucoup ici" ; Associated Neg Log Probability: [2.4623508]
-
Translated Sentence 4 : "elle fort froid la bas" ; Associated Neg Log Probability: [3.4176364]
-
Translated Sentence 5 : "son a tres la bas" ; Associated Neg Log Probability: [3.54257]
-
-
evaluate_with_beam('You may speak', 5) :-
-
Translated Sentence 1 : "vous discuter" ; Associated Neg Log Probability: [0.7923796]
-
Translated Sentence 2 : "tu parler" ; Associated Neg Log Probability: [2.2389612]
-
Translated Sentence 3 : "peut arreter" ; Associated Neg Log Probability: [4.0256424]
-
Translated Sentence 4 : "il parler" ; Associated Neg Log Probability: [1.5031487]
-
Translated Sentence 5 : "on courir" ; Associated Neg Log Probability: [3.999619]
-
Any model has to be evaluated to know how good it is or to compare it with other models.
Machine translations are textual data and BLEU is a metric that can help to evaluate the translations with the correct translations that should be given. It is based on an n-gram model where it looks at the words appearing in the candidate translation with the reference translation (with combinations). There are obvious limitations to this evaluation such as it will look at the word's and nearby words' positions only.
NLTK's bleu_score library gives this functionality. It looks at 1-gram to 4-gram and gives an average value (not exactly average) for how good the translations match with each other. You can evaluate the model on a test set using corplus_bleu. For more information, do refer nltk library and this article - https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
On testing the model with BLEU, we find that even though the french translations are quite near to each other (when translated back to english) but the BLEU score is quite low. BLEU ranges from 0(denoting no match) to 1(denoting perfect match). As stated earlier, this is a limitation of BLEU but it is still widely practiced as a metric to measure textual models' performances.