8M games - training progress note #1569
Comments
|
How many Gigabyte of data is the necessary training data ? (i mean the data we need to train a new network can't be that long ago, 10x128 training games can't be valuable now for example) |
|
A full window is about 20G-30G IIRC. The problem is that it evolves a few times a day so it's not very fit for torrenting. The storage server that broke was very nice because I could update it almost incrementally with rsync. At worst I'll rent a dedicated server with a big HDD for a while. |
To make it clear, the data for old networks doesn't change any more so this you can torrent. But of course if you're trying to beat the last network, you want the data for the last network, and this gets a bit more messy. |
|
Yeah it would not be as practical, but it would be possible to create a new torrent on a schedule like on every 2 days. It would maybe be acceptable of a delay to do training experiments. Renting a server could be doable too, do not hesitate to create a go fund me or something like it to help with money, i think many of us would donate a little to help with renting. |
|
Is there room for improvement with SWA? |
|
@gcp FYI, bjiyxo released v15 of his 256x20 network a few days ago. It hasn't been queued yet. |
|
the webpage shows the training games of 256x20 v15 is 8.121M, it is too big, as bjiyxo syas it was up to lz 146 |
|
I wasn't sure what number to use. I changed it to 7690965. |
|
@gcp Can you post the new raw training data (including 147, 148, and ELF) on Google Drive or Dropbox? Then I can train a new 20b catching up the latest 15b. |
|
Did the previous 20b include any ELF games? |
|
@carljohanr Yes, including ~ 150k ELF games. |
|
You attribute the slow progress to lack of ELF games in the window. However, if that is the case, i am rather worried by the rate of progress intrinsically our training pipeline. It looks as though our training hardly inproves strength, while apparently there is still a lot of room for Improvement. Of course I understand that learning Goes faster with a good tutor, but it seems to have nearly stalled without it. |
Our progress would have been clearly slower without the ELF data. That's why we are using it! I am not sure we would have stalled out or not without it, or would have needed to jump to 256x20 faster, but it seems likely. (Of course, in terms of time, generating the ELF data took time that could have been used for "regular" training games) |
|
@ThorAvaTahr Not so worried on my side, I think we are "not so far" from the theoretical maximum of a 15x192 network, hence the selfplay improvement necessarily slows down. What kept a relatively good pace of progress is due to ELF, accelerating strongly the process vs a pure selfplay approach. Once you remove ELF, it is not accelerated anymore and as we are close to the max, it is (very) slow... JMHO. |
|
Did anyone notice that each time GCP posted about the current situation and what the plans were...we'd have a PASS in the next few hours :) |
|
Not to be a spoilsport, but the irony of that disappears with the knowledge these posts tend to be accompanied with a lowering of the learning rate. |
|
maybe lz148 is better than 149, as it beat 20 weights and last 20k games, while 149 only beat 1 weight, and is beaten by 2 weights and only last 6000 games |
The learning rate was not changed, fixing the dump of the window was enough (for now). |
I'll update the #167 topic with some temporary links. |
|
The selfplay games of Elf are going to 25k. Will we train a super ELF (20*224) for replacing ELF to generate new better selfplay game? |
|
the elf self play will hit 250k games today, will @gcp stop elf play tomorrow? |
|
So it's normal to expect a point at which a network of a given size can still be improved but only by training games that come from a larger network? |
|
@TFiFiE it's not true theoretically as, after an infinite time of efficient selfplay training, the net should go to its maximum performance. So training it with a larger net or not, it should reach its maximum. |
|
@2j3150 elf is just a helper for LZ. Why do we need to discard our LZ and train a so -called “super Elf II “? But we do need to enlarge our network for a better LZ in order to beat and swallow the elf weight. |
|
2j3150 means, since we have good training set(>250k) to enhance ELF itself, we could try to train better-ELF separately. If we would get better-ELF net, it may help LZ training too. |
|
elf self play games is over 250k. 7933493 total self-play games (20519 in past 24 hours, 625 in past hour, includes 250252 ELF). |
|
most of you seem only to think about how to make lz stronger instead of appreciating the progress of the project as it is also, 250k is just an estimation, it could be 260k, 300k, 350k, depending on how things go my suggestion would be less matches, instead of doing them every 30k games, do it rather every 50-60k games should be quite safe, and start with +64.0k networks (as +32.0k rarely pass). The computing power saved can be invested in more selfplay training EDIT : +30k new games after 8M total games have naturally much less impact than +30k new games at 1M total games, so maybe its the right time to widen the window |
|
@wonderingabout I disagree with your suggestion which is just a disturbing to normal LZ training. |
|
sorry but you're dreaming.. so i think lz keeping working in the same direction would be much appreciated, at least by me, and among possible projects the ones that first come to my mind are generalized komi (being able to play with -50.5 komi against dan players for example), support for handi games with realistic moves, customizbale realistic and reliable difficulty (i know you can pick first networks to lower difficulty, but these have many flaws in particular falling to ladders) see my above comment for EDIT EDIT 2 : for customizable difficulty, make lz play moves to reach ex. 30% winrate = win ?, or variable winrate during the game = win ? |
|
Don't take ELF for granted. FAIR is not a go company. We might need to reach AlphaGo Zero by ourselves. As far as I'm concerned,I will always support the Go AI which will constantly improve itself,no matter how long it takes. |
|
i am afraid of the new weights become too strong, others can training with them, and the risk of lz lost in ai competition increases |
|
i'm curious to see how lz 152 compares to elf now |
|
Difference was about 315 Elo with 86% winrate. Since that, LZ progressed around 205 Elo, but it is selfplay, so the real improvement is rather ~80 Elo, so the remaining difference should be around 230 Elo, ie a ~79% win rate for ELF vs LZ152. But LZ vs Elf is becoming a kind of selfplay scale too, with an inflated scale. Hence, the difference should be smaller than 230 Elo: hard to guess but I'd say ~180 Elo, ie a ~74% win rate |
|
I'm a little less optimistic, so I'll say 79% for ELF (vs. LZ152). |
|
78% after (only) 37 games: seems we are not too far of, but still extremely noisy, we have to wait for at least 100 games to get a better idea! |
|
I just updated the 3-3 knight's move tracking #1442 From LZ148, the priors for the critical move for the joseki increased suddenly from 17% to LZ150 32% to LZ152 46%. Perhaps in addition to ELF reaching half of the window, newer training data is pushing out those from much older networks that would have trained towards ~10% prior instead of ELF's ~100% prior. Here's the progress of the joseki for just the 192x15 networks every 5 since turning on ELF: |

|
@gcp We should lower the learning rate in my opinion if there isn't any progress on 15b today. |
|
200k without a promotion. It's time for LR drop :) |
|
@bjiyxo's point still holds in my opinion. With process as slow as currently, you eventually get lucky passes. A change to LR and a plan to soon switch to 256x20 would make a lot of sense now. |
|
|

|
@jkiliani "A change to LR and a plan to soon switch to 256x20 would make a lot of sense now." Perhaps after lowering LR gets exhausted, to give a try to lowering promotion limit to 52% or 51% for a week or so? It would not hurt, would it? |
|
|

|
|

|
no promotion in 10 days, then 7 nets appear on a row. |
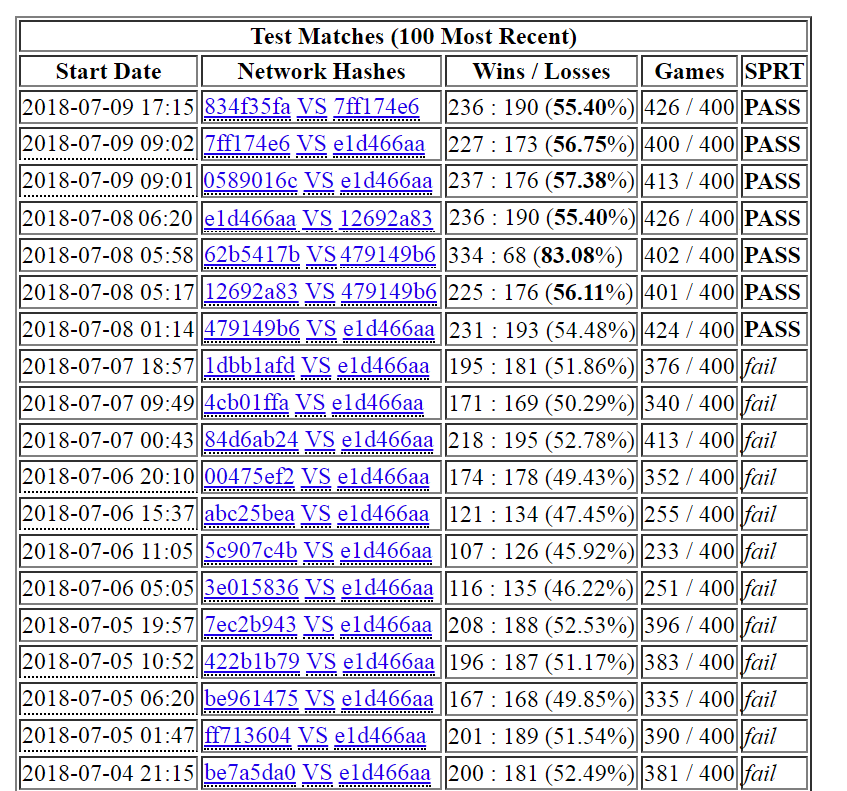
|
I lowered learning rate at around 200k games, but 7ff1 passed while still using the old rate. |
|
on a more serious note, i find it a bit strange that lz gets 2 (and maybe 3) promotions on a row after this 200k games stagnation |
|
@gcp What is the current learning rate ? |
|
I’ve also wondered if there is a trend with many recent "long reigning champions" (networks that last 50k+ selfplay without losing 55% to anynew nets) first being beaten, and then these new networks usually get beaten themselves in 5k games or so? "Revolution eats its children"? Learning rate was not the culprit for many of these, as it was changed only now. Could be just random stuff ofc |
|
@gcp why lower learning rate can speed up promote? |

|
@jokkebk that was actually fairly easy to explain: those cases were networks of the same training batch. As they were trained with more training steps on the same data, they got stronger.
|

|
@NhanHo Do you have the plan to train new network of 1286 using later raw data, as you have done to 645 network? |
If we're in between your two examples, it's as if the parameters jump from one side of the ramp to the other, without going down (but not too big, so it doesn't diverge up either). If you halve (or more) the step sizes, it will go right down to the bottom. |
One other factor might be that on a new iteration the learning starts from the best network, so you're now starting the learning off of a very good spot and adding a lot of iterations onto that. This could especially be true for 256k promotes. |
0.0001 @ batch size = 256. |
|
lz just got a new promotion |
|
lz 156 vs elf winrate 23-25% |
|
Anyone know if ELF is correctly resigning in the 300+ move games? http://zero.sjeng.org/match-games/5b4be7022f06263c66c692a7 http://zero.sjeng.org/viewmatch/580fc26fdfa45d8707374cef8018a03424df3d06eff03cd0c68fa295da6132b9?viewer=wgo Looking at the average network eval (no search), ELF thinks the win rate is around 15% while LZ156 thinks it's closer to 25% and 40%. So I suppose at least both agree that ELF was in a losing position… |
|
To self-prove the resign is correct or not, Leela Zero can continue the game without resigning? Then, scoring from the endgame to see which side (black or white) wins. |
|
some games are wrongly resigned, but it is less than 5% generally, so on 400 games we can assume the number of wrongly resigned games is the same thanks for doing the elf test, i was surprised to see it improve that much (with a delta of possible error margin in mind) |
Small note because I know many people will start "panicking" as we have 200k games with no notable strength progress (i.e. PASS).
One reason why progress dropped a bit is that the ELF games left the training window. This wasn't intentional. I tried a quick fix (I was traveling) of increasing the window to 800k but the result wasn't particularly good. I somewhat rewrote the dumping code now to correctly deal with this and the next run should be closer to what was intended (~230k ELF + 250k regular). We'll see if this improves things. There'll be some delay before the next bunch of networks as I was fiddling with the training setup to get it debugged.
If these fixes don't produce progress, the next step will be a lowering of the learning rate. Because we're using SWA this might not necessarily produce a jump either.
It would be good to be able to start training and comparing 256x20 now, to figure out if network size is the issue (it sounds likely, but we do need confirmation in the form of a stronger 256x20 without which we can't do anything anyway!). It is really extremely unfortunate that we have the problem in #167 now. If this does not get resolved in a few days I will see if I can get some other hosting set up. (Data loss is not an issue, I have 2 full backups of the database...)
The text was updated successfully, but these errors were encountered: