This repository provides a demonstration of usual data sciene workflow. Please keep in mind, that this is just one example approach of many, use whatever works best for your team(s).
You should have already installed Anaconda.
First, configure Conda:
conda config --add channels conda-forge
conda config --set channel_priority strict
Secondly, create environment called data-science-workflow-demonstration.
conda create --name "data-science-workflow-demonstration" python=3.7.9 mlflow scikit-learn jupyterlab papermill matplotlib statsmodels ipywidgets
Conda checks to see what additional packages ("dependencies") will need, and asks if you want to proceed:
Proceed ([y]/n)? y
Type "y" and press Enter to proceed.
After everything has been installed, active the environment data-science-workflow-demonstration:
conda activate data-science-workflow-demonstration
cd notebooks && jupyter lab
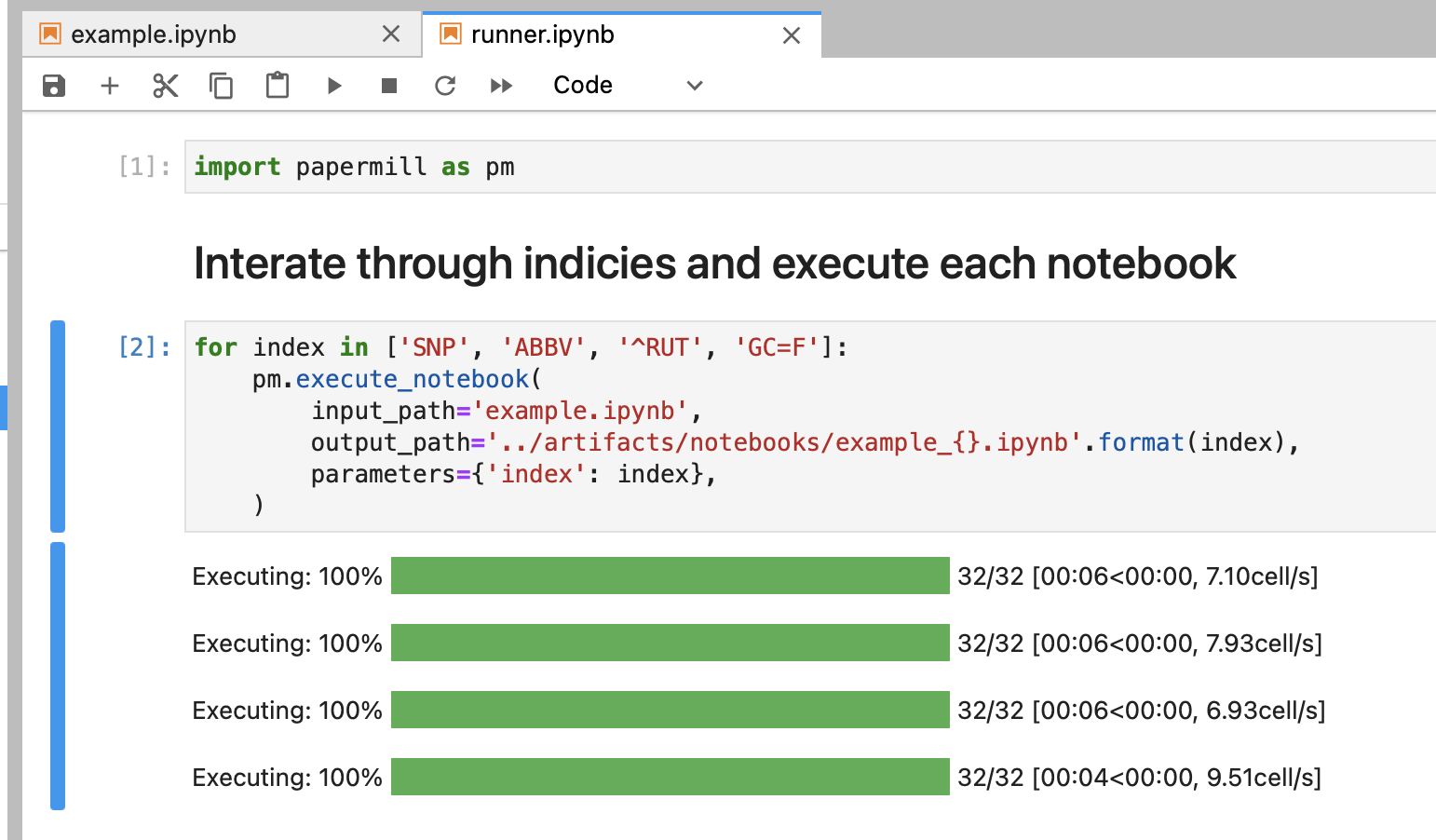
Run the cells in runner.ipynb!
You should see the following:
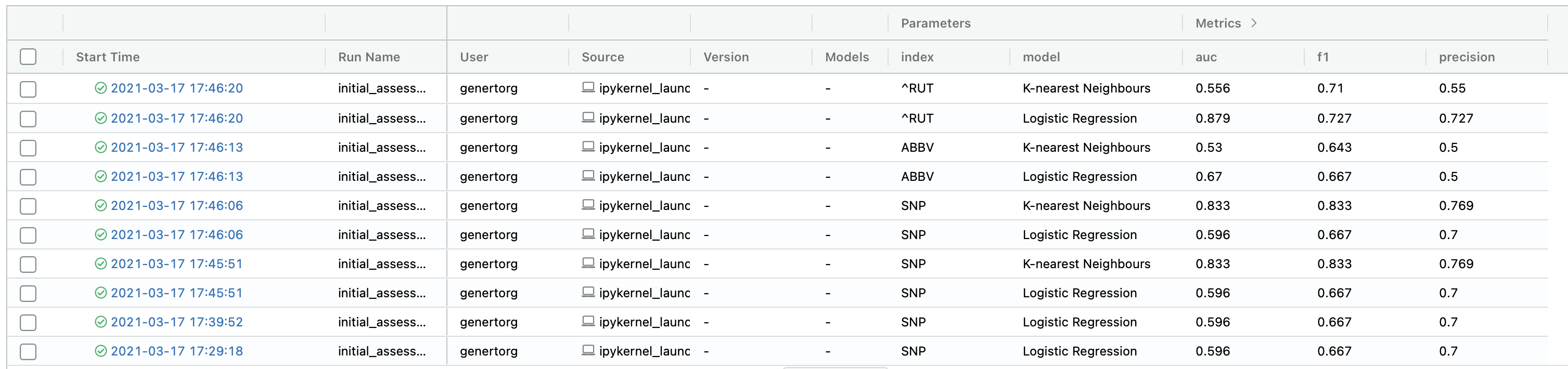
cd notebooks && mlflow ui
You should see the following:
Profit!